 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Hungarian: Match-Free Supervision for End-to-End Object Detection
Mar 09, 2026Recent DEtection TRansformer (DETR) based frameworks have achieved remarkable success in end-to-end object detection. However, the reliance on the Hungarian algorithm for bipartite matching between queries and ground truths introduces computational overhead and complicates the training dynamics. In this paper, we propose a novel matching-free training scheme for DETR-based detectors that eliminates the need for explicit heuristic matching. At the core of our approach is a dedicated Cross-Attention-based Query Selection (CAQS) module. Instead of discrete assignment, we utilize encoded ground-truth information to probe the decoder queries through a cross-attention mechanism. By minimizing the weighted error between the queried results and the ground truths, the model autonomously learns the implicit correspondences between object queries and specific targets. This learned relationship further provides supervision signals for the learning of queries. Experimental results demonstrate that our proposed method bypasses the traditional matching process, significantly enhancing training efficiency, reducing the matching latency by over 50\%, effectively eliminating the discrete matching bottleneck through differentiable correspondence learning, and also achieving superior performance compared to existing state-of-the-art methods.
AMap: Distilling Future Priors for Ahead-Aware Online HD Map Construction
Dec 22, 2025



Online High-Definition (HD) map construction is pivotal for autonomous driving. While recent approaches leverage historical temporal fusion to improve performance, we identify a critical safety flaw in this paradigm: it is inherently ``spatially backward-looking." These methods predominantly enhance map reconstruction in traversed areas, offering minimal improvement for the unseen road ahead. Crucially, our analysis of downstream planning tasks reveals a severe asymmetry: while rearward perception errors are often tolerable, inaccuracies in the forward region directly precipitate hazardous driving maneuvers. To bridge this safety gap, we propose AMap, a novel framework for Ahead-aware online HD Mapping. We pioneer a ``distill-from-future" paradigm, where a teacher model with privileged access to future temporal contexts guides a lightweight student model restricted to the current frame. This process implicitly compresses prospective knowledge into the student model, endowing it with ``look-ahead" capabilities at zero inference-time cost. Technically, we introduce a Multi-Level BEV Distillation strategy with spatial masking and an Asymmetric Query Adaptation module to effectively transfer future-aware representations to the student's static queries. Extensive experiments on the nuScenes and Argoverse 2 benchmark demonstrate that AMap significantly enhances current-frame perception. Most notably, it outperforms state-of-the-art temporal models in critical forward regions while maintaining the efficiency of single current frame inference.
vMFCoOp: Towards Equilibrium on a Unified Hyperspherical Manifold for Prompting Biomedical VLMs
Nov 13, 2025Recent advances in context optimization (CoOp) guided by large language model (LLM)-distilled medical semantic priors offer a scalable alternative to manual prompt engineering and full fine-tuning for adapting biomedical CLIP-based vision-language models (VLMs). However, prompt learning in this context is challenged by semantic misalignment between LLMs and CLIP variants due to divergent training corpora and model architectures; it further lacks scalability across continuously evolving families of foundation models. More critically, pairwise multimodal alignment via conventional Euclidean-space optimization lacks the capacity to model unified representations or apply localized geometric constraints, which tends to amplify modality gaps in complex biomedical imaging and destabilize few-shot adaptation. In this work, we propose vMFCoOp, a framework that inversely estimates von Mises-Fisher (vMF) distributions on a shared Hyperspherical Manifold, aligning semantic biases between arbitrary LLMs and CLIP backbones via Unified Semantic Anchors to achieve robust biomedical prompting and superior few-shot classification. Grounded in three complementary constraints, vMFCoOp demonstrates consistent improvements across 14 medical datasets, 12 medical imaging modalities, and 13 anatomical regions, outperforming state-of-the-art methods in accuracy, generalization, and clinical applicability. This work aims to continuously expand to encompass more downstream applications, and the corresponding resources are intended to be shared through https://github.com/VinyehShaw/UniEqui.
Learning Global Representation from Queries for Vectorized HD Map Construction
Oct 08, 2025The online construction of vectorized high-definition (HD) maps is a cornerstone of modern autonomous driving systems. State-of-the-art approaches, particularly those based on the DETR framework, formulate this as an instance detection problem. However, their reliance on independent, learnable object queries results in a predominantly local query perspective, neglecting the inherent global representation within HD maps. In this work, we propose \textbf{MapGR} (\textbf{G}lobal \textbf{R}epresentation learning for HD \textbf{Map} construction), an architecture designed to learn and utilize a global representations from queries. Our method introduces two synergistic modules: a Global Representation Learning (GRL) module, which encourages the distribution of all queries to better align with the global map through a carefully designed holistic segmentation task, and a Global Representation Guidance (GRG) module, which endows each individual query with explicit, global-level contextual information to facilitate its optimization. Evaluations on the nuScenes and Argoverse2 datasets validate the efficacy of our approach, demonstrating substantial improvements in mean Average Precision (mAP) compared to leading baselines.
AdaGAT: Adaptive Guidance Adversarial Training for the Robustness of Deep Neural Networks
Aug 24, 2025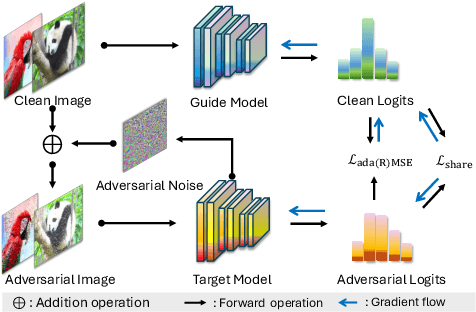
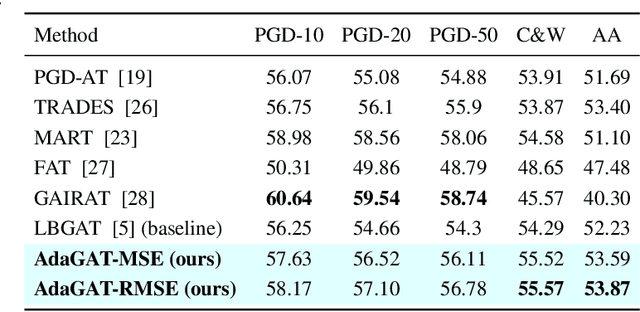
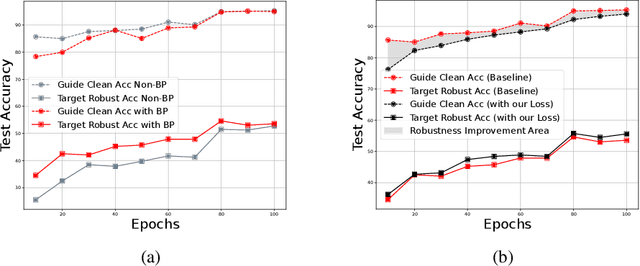
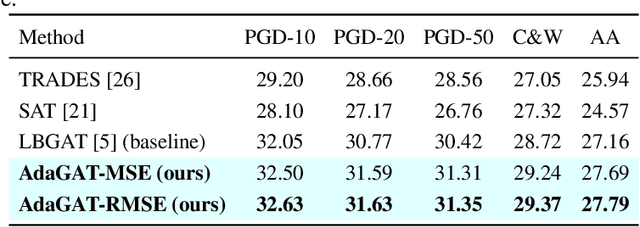
Adversarial distillation (AD) is a knowledge distillation technique that facilitates the transfer of robustness from teacher deep neural network (DNN) models to lightweight target (student) DNN models, enabling the target models to perform better than only training the student model independently. Some previous works focus on using a small, learnable teacher (guide) model to improve the robustness of a student model. Since a learnable guide model starts learning from scratch, maintaining its optimal state for effective knowledge transfer during co-training is challenging. Therefore, we propose a novel Adaptive Guidance Adversarial Training (AdaGAT) method. Our method, AdaGAT, dynamically adjusts the training state of the guide model to install robustness to the target model. Specifically, we develop two separate loss functions as part of the AdaGAT method, allowing the guide model to participate more actively in backpropagation to achieve its optimal state. We evaluated our approach via extensive experiments on three datasets: CIFAR-10, CIFAR-100, and TinyImageNet, using the WideResNet-34-10 model as the target model. Our observations reveal that appropriately adjusting the guide model within a certain accuracy range enhances the target model's robustness across various adversarial attacks compared to a variety of baseline models.
Reusing Attention for One-stage Lane Topology Understanding
Jul 23, 2025Understanding lane toplogy relationships accurately is critical for safe autonomous driving. However, existing two-stage methods suffer from inefficiencies due to error propagations and increased computational overheads. To address these challenges, we propose a one-stage architecture that simultaneously predicts traffic elements, lane centerlines and topology relationship, improving both the accuracy and inference speed of lane topology understanding for autonomous driving. Our key innovation lies in reusing intermediate attention resources within distinct transformer decoders. This approach effectively leverages the inherent relational knowledge within the element detection module to enable the modeling of topology relationships among traffic elements and lanes without requiring additional computationally expensive graph networks. Furthermore, we are the first to demonstrate that knowledge can be distilled from models that utilize standard definition (SD) maps to those operates without using SD maps, enabling superior performance even in the absence of SD maps. Extensive experiments on the OpenLane-V2 dataset show that our approach outperforms baseline methods in both accuracy and efficiency, achieving superior results in lane detection, traffic element identification, and topology reasoning. Our code is available at https://github.com/Yang-Li-2000/one-stage.git.
Control Map Distribution using Map Query Bank for Online Map Generation
Apr 04, 2025Reliable autonomous driving systems require high-definition (HD) map that contains detailed map information for planning and navigation. However, pre-build HD map requires a large cost. Visual-based Online Map Generation (OMG) has become an alternative low-cost solution to build a local HD map. Query-based BEV Transformer has been a base model for this task. This model learns HD map predictions from an initial map queries distribution which is obtained by offline optimization on training set. Besides the quality of BEV feature, the performance of this model also highly relies on the capacity of initial map query distribution. However, this distribution is limited because the limited query number. To make map predictions optimal on each test sample, it is essential to generate a suitable initial distribution for each specific scenario. This paper proposes to decompose the whole HD map distribution into a set of point representations, namely map query bank (MQBank). To build specific map query initial distributions of different scenarios, low-cost standard definition map (SD map) data is introduced as a kind of prior knowledge. Moreover, each layer of map decoder network learns instance-level map query features, which will lose detailed information of each point. However, BEV feature map is a point-level dense feature. It is important to keep point-level information in map queries when interacting with BEV feature map. This can also be solved with map query bank method. Final experiments show a new insight on SD map prior and a new record on OpenLaneV2 benchmark with 40.5%, 45.7% mAP on vehicle lane and pedestrian area.
Chameleon: Fast-slow Neuro-symbolic Lane Topology Extraction
Mar 10, 2025Lane topology extraction involves detecting lanes and traffic elements and determining their relationships, a key perception task for mapless autonomous driving. This task requires complex reasoning, such as determining whether it is possible to turn left into a specific lane. To address this challenge, we introduce neuro-symbolic methods powered by vision-language foundation models (VLMs). Existing approaches have notable limitations: (1) Dense visual prompting with VLMs can achieve strong performance but is costly in terms of both financial resources and carbon footprint, making it impractical for robotics applications. (2) Neuro-symbolic reasoning methods for 3D scene understanding fail to integrate visual inputs when synthesizing programs, making them ineffective in handling complex corner cases. To this end, we propose a fast-slow neuro-symbolic lane topology extraction algorithm, named Chameleon, which alternates between a fast system that directly reasons over detected instances using synthesized programs and a slow system that utilizes a VLM with a chain-of-thought design to handle corner cases. Chameleon leverages the strengths of both approaches, providing an affordable solution while maintaining high performance. We evaluate the method on the OpenLane-V2 dataset, showing consistent improvements across various baseline detectors. Our code, data, and models are publicly available at https://github.com/XR-Lee/neural-symbolic
Unified Few-shot Crack Segmentation and its Precise 3D Automatic Measurement in Concrete Structures
Jan 15, 2025
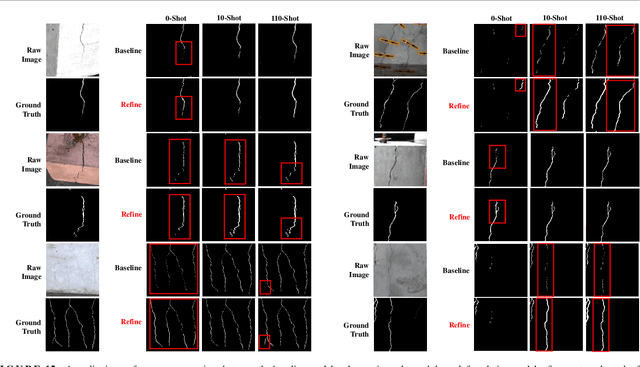

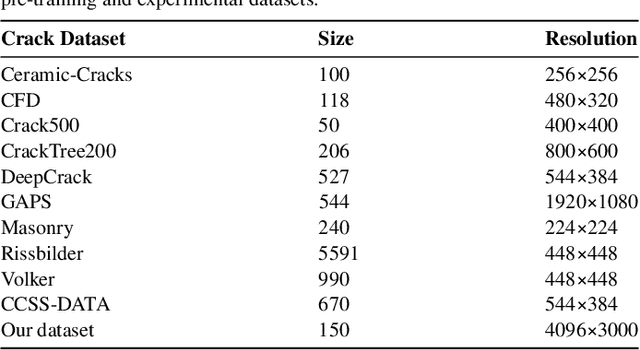
Visual-Spatial Systems has become increasingly essential in concrete crack inspection. However, existing methods often lacks adaptability to diverse scenarios, exhibits limited robustness in image-based approaches, and struggles with curved or complex geometries. To address these limitations, an innovative framework for two-dimensional (2D) crack detection, three-dimensional (3D) reconstruction, and 3D automatic crack measurement was proposed by integrating computer vision technologies and multi-modal Simultaneous localization and mapping (SLAM) in this study. Firstly, building on a base DeepLabv3+ segmentation model, and incorporating specific refinements utilizing foundation model Segment Anything Model (SAM), we developed a crack segmentation method with strong generalization across unfamiliar scenarios, enabling the generation of precise 2D crack masks. To enhance the accuracy and robustness of 3D reconstruction, Light Detection and Ranging (LiDAR) point clouds were utilized together with image data and segmentation masks. By leveraging both image- and LiDAR-SLAM, we developed a multi-frame and multi-modal fusion framework that produces dense, colorized point clouds, effectively capturing crack semantics at a 3D real-world scale. Furthermore, the crack geometric attributions were measured automatically and directly within 3D dense point cloud space, surpassing the limitations of conventional 2D image-based measurements. This advancement makes the method suitable for structural components with curved and complex 3D geometries. Experimental results across various concrete structures highlight the significant improvements and unique advantages of the proposed method, demonstrating its effectiveness, accuracy, and robustness in real-world applications.
PC-BEV: An Efficient Polar-Cartesian BEV Fusion Framework for LiDAR Semantic Segmentation
Dec 19, 2024Although multiview fusion has demonstrated potential in LiDAR segmentation, its dependence on computationally intensive point-based interactions, arising from the lack of fixed correspondences between views such as range view and Bird's-Eye View (BEV), hinders its practical deployment. This paper challenges the prevailing notion that multiview fusion is essential for achieving high performance. We demonstrate that significant gains can be realized by directly fusing Polar and Cartesian partitioning strategies within the BEV space. Our proposed BEV-only segmentation model leverages the inherent fixed grid correspondences between these partitioning schemes, enabling a fusion process that is orders of magnitude faster (170$\times$ speedup) than conventional point-based methods. Furthermore, our approach facilitates dense feature fusion, preserving richer contextual information compared to sparse point-based alternatives. To enhance scene understanding while maintaining inference efficiency, we also introduce a hybrid Transformer-CNN architecture. Extensive evaluation on the SemanticKITTI and nuScenes datasets provides compelling evidence that our method outperforms previous multiview fusion approaches in terms of both performance and inference speed, highlighting the potential of BEV-based fusion for LiDAR segmentation. Code is available at \url{https://github.com/skyshoumeng/PC-BEV.}