 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Few-shot Crack Segmentation and its Precise 3D Automatic Measurement in Concrete Structures
Jan 15, 2025
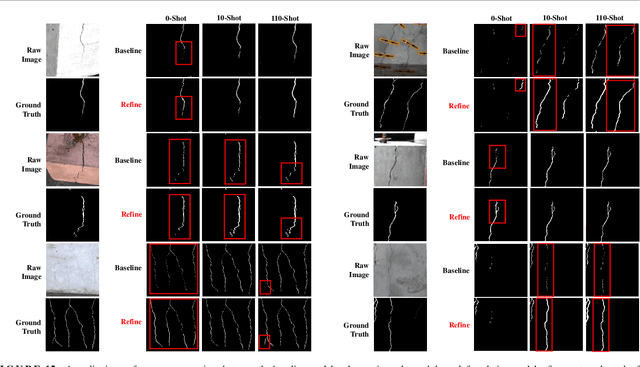

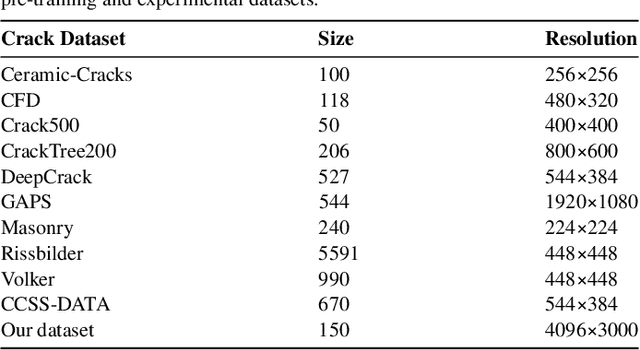
Visual-Spatial Systems has become increasingly essential in concrete crack inspection. However, existing methods often lacks adaptability to diverse scenarios, exhibits limited robustness in image-based approaches, and struggles with curved or complex geometries. To address these limitations, an innovative framework for two-dimensional (2D) crack detection, three-dimensional (3D) reconstruction, and 3D automatic crack measurement was proposed by integrating computer vision technologies and multi-modal Simultaneous localization and mapping (SLAM) in this study. Firstly, building on a base DeepLabv3+ segmentation model, and incorporating specific refinements utilizing foundation model Segment Anything Model (SAM), we developed a crack segmentation method with strong generalization across unfamiliar scenarios, enabling the generation of precise 2D crack masks. To enhance the accuracy and robustness of 3D reconstruction, Light Detection and Ranging (LiDAR) point clouds were utilized together with image data and segmentation masks. By leveraging both image- and LiDAR-SLAM, we developed a multi-frame and multi-modal fusion framework that produces dense, colorized point clouds, effectively capturing crack semantics at a 3D real-world scale. Furthermore, the crack geometric attributions were measured automatically and directly within 3D dense point cloud space, surpassing the limitations of conventional 2D image-based measurements. This advancement makes the method suitable for structural components with curved and complex 3D geometries. Experimental results across various concrete structures highlight the significant improvements and unique advantages of the proposed method, demonstrating its effectiveness, accuracy, and robustness in real-world applications.
Decentralized Federated Learning with Gradient Tracking over Time-Varying Directed Networks
Sep 25, 2024



We investigate the problem of agent-to-agent interaction in decentralized (federated) learning over time-varying directed graphs, and, in doing so, propose a consensus-based algorithm called DSGTm-TV. The proposed algorithm incorporates gradient tracking and heavy-ball momentum to distributively optimize a global objective function, while preserving local data privacy. Under DSGTm-TV, agents will update local model parameters and gradient estimates using information exchange with neighboring agents enabled through row- and column-stochastic mixing matrices, which we show guarantee both consensus and optimality. Our analysis establishes that DSGTm-TV exhibits linear convergence to the exact global optimum when exact gradient information is available, and converges in expectation to a neighborhood of the global optimum when employing stochastic gradients. Moreover, in contrast to existing methods, DSGTm-TV preserves convergence for networks with uncoordinated stepsizes and momentum parameters, for which we provide explicit bounds. These results enable agents to operate in a fully decentralized manner, independently optimizing their local hyper-parameters. We demonstrate the efficacy of our approach via comparisons with state-of-the-art baselines on real-world image classification and natural language processing tasks.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Evaluating Numerical Reasoning in Text-to-Image Models
Jun 20, 2024



Text-to-image generative models are capable of producing high-quality images that often faithfully depict concepts described using natural language. In this work, we comprehensively evaluate a range of text-to-image models on numerical reasoning tasks of varying difficulty, and show that even the most advanced models have only rudimentary numerical skills. Specifically, their ability to correctly generate an exact number of objects in an image is limited to small numbers, it is highly dependent on the context the number term appears in, and it deteriorates quickly with each successive number. We also demonstrate that models have poor understanding of linguistic quantifiers (such as "a few" or "as many as"), the concept of zero, and struggle with more advanced concepts such as partial quantities and fractional representations. We bundle prompts, generated images and human annotations into GeckoNum, a novel benchmark for evaluation of numerical reasoning.
Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
May 27, 2024



We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
DOCCI: Descriptions of Connected and Contrasting Images
Apr 30, 2024



Vision-language datasets are vital for both text-to-image (T2I) and image-to-text (I2T) research. However, current datasets lack descriptions with fine-grained detail that would allow for richer associations to be learned by models. To fill the gap, we introduce Descriptions of Connected and Contrasting Images (DOCCI), a dataset with long, human-annotated English descriptions for 15k images that were taken, curated and donated by a single researcher intent on capturing key challenges such as spatial relations, counting, text rendering, world knowledge, and more. We instruct human annotators to create comprehensive descriptions for each image; these average 136 words in length and are crafted to clearly distinguish each image from those that are related or similar. Each description is highly compositional and typically encompasses multiple challenges. Through both quantitative and qualitative analyses, we demonstrate that DOCCI serves as an effective training resource for image-to-text generation -- a PaLI 5B model finetuned on DOCCI shows equal or superior results compared to highly-performant larger models like LLaVA-1.5 7B and InstructBLIP 7B. Furthermore, we show that DOCCI is a useful testbed for text-to-image generation, highlighting the limitations of current text-to-image models in capturing long descriptions and fine details.
Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings
Apr 25, 2024While text-to-image (T2I) generative models have become ubiquitous, they do not necessarily generate images that align with a given prompt. While previous work has evaluated T2I alignment by proposing metrics, benchmarks, and templates for collecting human judgements, the quality of these components is not systematically measured. Human-rated prompt sets are generally small and the reliability of the ratings -- and thereby the prompt set used to compare models -- is not evaluated. We address this gap by performing an extensive study evaluating auto-eval metrics and human templates. We provide three main contributions: (1) We introduce a comprehensive skills-based benchmark that can discriminate models across different human templates. This skills-based benchmark categorises prompts into sub-skills, allowing a practitioner to pinpoint not only which skills are challenging, but at what level of complexity a skill becomes challenging. (2) We gather human ratings across four templates and four T2I models for a total of >100K annotations. This allows us to understand where differences arise due to inherent ambiguity in the prompt and where they arise due to differences in metric and model quality. (3) Finally, we introduce a new QA-based auto-eval metric that is better correlated with human ratings than existing metrics for our new dataset, across different human templates, and on TIFA160.
Communication-Efficient Multimodal Federated Learning: Joint Modality and Client Selection
Jan 30, 2024



Multimodal federated learning (FL) aims to enrich model training in FL settings where clients are collecting measurements across multiple modalities. However, key challenges to multimodal FL remain unaddressed, particularly in heterogeneous network settings where: (i) the set of modalities collected by each client will be diverse, and (ii) communication limitations prevent clients from uploading all their locally trained modality models to the server. In this paper, we propose multimodal Federated learning with joint Modality and Client selection (mmFedMC), a new FL methodology that can tackle the above-mentioned challenges in multimodal settings. The joint selection algorithm incorporates two main components: (a) A modality selection methodology for each client, which weighs (i) the impact of the modality, gauged by Shapley value analysis, (ii) the modality model size as a gauge of communication overhead, against (iii) the frequency of modality model updates, denoted recency, to enhance generalizability. (b) A client selection strategy for the server based on the local loss of modality model at each client. Experiments on five real-world datasets demonstrate the ability of mmFedMC to achieve comparable accuracy to several baselines while reducing the communication overhead by over 20x. A demo video of our methodology is available at https://liangqiy.com/mmfedmc/.
DreamSync: Aligning Text-to-Image Generation with Image Understanding Feedback
Nov 29, 2023



Despite their wide-spread success, Text-to-Image models (T2I) still struggle to produce images that are both aesthetically pleasing and faithful to the user's input text. We introduce DreamSync, a model-agnostic training algorithm by design that improves T2I models to be faithful to the text input. DreamSync builds off a recent insight from TIFA's evaluation framework -- that large vision-language models (VLMs) can effectively identify the fine-grained discrepancies between generated images and the text inputs. DreamSync uses this insight to train T2I models without any labeled data; it improves T2I models using its own generations. First, it prompts the model to generate several candidate images for a given input text. Then, it uses two VLMs to select the best generation: a Visual Question Answering model that measures the alignment of generated images to the text, and another that measures the generation's aesthetic quality. After selection, we use LoRA to iteratively finetune the T2I model to guide its generation towards the selected best generations. DreamSync does not need any additional human annotation. model architecture changes, or reinforcement learning. Despite its simplicity, DreamSync improves both the semantic alignment and aesthetic appeal of two diffusion-based T2I models, evidenced by multiple benchmarks (+1.7% on TIFA, +2.9% on DSG1K, +3.4% on VILA aesthetic) and human evaluation.
Device Sampling and Resource Optimization for Federated Learning in Cooperative Edge Networks
Nov 07, 2023The conventional federated learning (FedL) architecture distributes machine learning (ML) across worker devices by having them train local models that are periodically aggregated by a server. FedL ignores two important characteristics of contemporary wireless networks, however: (i) the network may contain heterogeneous communication/computation resources, and (ii) there may be significant overlaps in devices' local data distributions. In this work, we develop a novel optimization methodology that jointly accounts for these factors via intelligent device sampling complemented by device-to-device (D2D) offloading. Our optimization methodology aims to select the best combination of sampled nodes and data offloading configuration to maximize FedL training accuracy while minimizing data processing and D2D communication resource consumption subject to realistic constraints on the network topology and device capabilities. Theoretical analysis of the D2D offloading subproblem leads to new FedL convergence bounds and an efficient sequential convex optimizer. Using these results, we develop a sampling methodology based on graph convolutional networks (GCNs) which learns the relationship between network attributes, sampled nodes, and D2D data offloading to maximize FedL accuracy. Through evaluation on popular datasets and real-world network measurements from our edge testbed, we find that our methodology outperforms popular device sampling methodologies from literature in terms of ML model performance, data processing overhead, and energy consumption.