 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEURS-ASL: Including American Sign Language in Massively Multilingual Multitask Evaluation
Aug 24, 2024Sign language translation has historically been peripheral to mainstream machine translation research. In order to help converge the fields, we introduce FLEURS-ASL, an extension of the multiway parallel benchmarks FLORES (for text) and FLEURS (for speech) to support their first sign language (as video), American Sign Language, translated by 5 Certified Deaf Interpreters. FLEURS-ASL can be used to evaluate a variety of tasks -- primarily sentence- and discourse-level translation -- between ASL and 200 other languages as text, or 102 languages as speech. We provide baselines for tasks from ASL to English text using a unified modeling approach that incorporates timestamp tokens and previous text tokens in a 34-second context window, trained on random video clips from YouTube-ASL. This model meets or exceeds the performance of phrase-level baselines while supporting a multitude of new tasks. We also use FLEURS-ASL to show that multimodal frontier models have virtually no understanding of ASL, underscoring the importance of including sign languages in standard evaluation suites.
Fingerspelling within Sign Language Translation
Aug 13, 2024Fingerspelling poses challenges for sign language processing due to its high-frequency motion and use for open-vocabulary terms. While prior work has studied fingerspelling recognition, there has been little attention to evaluating how well sign language translation models understand fingerspelling in the context of entire sentences -- and improving this capability. We manually annotate instances of fingerspelling within FLEURS-ASL and use them to evaluate the effect of two simple measures to improve fingerspelling recognition within American Sign Language to English translation: 1) use a model family (ByT5) with character- rather than subword-level tokenization, and 2) mix fingerspelling recognition data into the translation training mixture. We find that 1) substantially improves understanding of fingerspelling (and therefore translation quality overall), but the effect of 2) is mixed.
FSboard: Over 3 million characters of ASL fingerspelling collected via smartphones
Jul 22, 2024Progress in machine understanding of sign languages has been slow and hampered by limited data. In this paper, we present FSboard, an American Sign Language fingerspelling dataset situated in a mobile text entry use case, collected from 147 paid and consenting Deaf signers using Pixel 4A selfie cameras in a variety of environments. Fingerspelling recognition is an incomplete solution that is only one small part of sign language translation, but it could provide some immediate benefit to Deaf/Hard of Hearing signers as more broadly capable technology develops. At >3 million characters in length and >250 hours in duration, FSboard is the largest fingerspelling recognition dataset to date by a factor of >10x. As a simple baseline, we finetune 30 Hz MediaPipe Holistic landmark inputs into ByT5-Small and achieve 11.1% Character Error Rate (CER) on a test set with unique phrases and signers. This quality degrades gracefully when decreasing frame rate and excluding face/body landmarks: plausible optimizations to help models run on device in real time.
Scaling Sign Language Translation
Jul 16, 2024



Sign language translation (SLT) addresses the problem of translating information from a sign language in video to a spoken language in text. Existing studies, while showing progress, are often limited to narrow domains and/or few sign languages and struggle with open-domain tasks. In this paper, we push forward the frontier of SLT by scaling pretraining data, model size, and number of translation directions. We perform large-scale SLT pretraining on different data including 1) noisy multilingual YouTube SLT data, 2) parallel text corpora, and 3) SLT data augmented by translating video captions to other languages with off-the-shelf machine translation models. We unify different pretraining tasks with task-specific prompts under the encoder-decoder architecture, and initialize the SLT model with pretrained (m/By)T5 models across model sizes. SLT pretraining results on How2Sign and FLEURS-ASL#0 (ASL to 42 spoken languages) demonstrate the significance of data/model scaling and cross-lingual cross-modal transfer, as well as the feasibility of zero-shot SLT. We finetune the pretrained SLT models on 5 downstream open-domain SLT benchmarks covering 5 sign languages. Experiments show substantial quality improvements over the vanilla baselines, surpassing the previous state-of-the-art (SOTA) by wide margins.
YouTube-SL-25: A Large-Scale, Open-Domain Multilingual Sign Language Parallel Corpus
Jul 15, 2024



Even for better-studied sign languages like American Sign Language (ASL), data is the bottleneck for machine learning research. The situation is worse yet for the many other sign languages used by Deaf/Hard of Hearing communities around the world. In this paper, we present YouTube-SL-25, a large-scale, open-domain multilingual corpus of sign language videos with seemingly well-aligned captions drawn from YouTube. With >3000 hours of videos across >25 sign languages, YouTube-SL-25 is a) >3x the size of YouTube-ASL, b) the largest parallel sign language dataset to date, and c) the first or largest parallel dataset for many of its component languages. We provide baselines for sign-to-text tasks using a unified multilingual multitask model based on T5 and report scores on benchmarks across 4 sign languages. The results demonstrate that multilingual transfer benefits both higher- and lower-resource sign languages within YouTube-SL-25.
Reconsidering Sentence-Level Sign Language Translation
Jun 16, 2024Historically, sign language machine translation has been posed as a sentence-level task: datasets consisting of continuous narratives are chopped up and presented to the model as isolated clips. In this work, we explore the limitations of this task framing. First, we survey a number of linguistic phenomena in sign languages that depend on discourse-level context. Then as a case study, we perform the first human baseline for sign language translation that actually substitutes a human into the machine learning task framing, rather than provide the human with the entire document as context. This human baseline -- for ASL to English translation on the How2Sign dataset -- shows that for 33% of sentences in our sample, our fluent Deaf signer annotators were only able to understand key parts of the clip in light of additional discourse-level context. These results underscore the importance of understanding and sanity checking examples when adapting machine learning to new domains.
Modeling Real-Time Interactive Conversations as Timed Diarized Transcripts
May 21, 2024
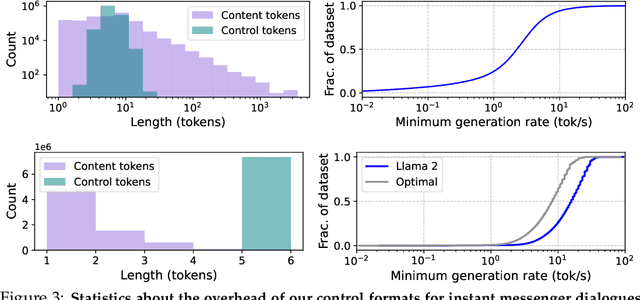


Chatbots built upon language models have exploded in popularity, but they have largely been limited to synchronous, turn-by-turn dialogues. In this paper we present a simple yet general method to simulate real-time interactive conversations using pretrained text-only language models, by modeling timed diarized transcripts and decoding them with causal rejection sampling. We demonstrate the promise of this method with two case studies: instant messenger dialogues and spoken conversations, which require generation at about 30 tok/s and 20 tok/s respectively to maintain real-time interactivity. These capabilities can be added into language models using relatively little data and run on commodity hardware.
DOCCI: Descriptions of Connected and Contrasting Images
Apr 30, 2024



Vision-language datasets are vital for both text-to-image (T2I) and image-to-text (I2T) research. However, current datasets lack descriptions with fine-grained detail that would allow for richer associations to be learned by models. To fill the gap, we introduce Descriptions of Connected and Contrasting Images (DOCCI), a dataset with long, human-annotated English descriptions for 15k images that were taken, curated and donated by a single researcher intent on capturing key challenges such as spatial relations, counting, text rendering, world knowledge, and more. We instruct human annotators to create comprehensive descriptions for each image; these average 136 words in length and are crafted to clearly distinguish each image from those that are related or similar. Each description is highly compositional and typically encompasses multiple challenges. Through both quantitative and qualitative analyses, we demonstrate that DOCCI serves as an effective training resource for image-to-text generation -- a PaLI 5B model finetuned on DOCCI shows equal or superior results compared to highly-performant larger models like LLaVA-1.5 7B and InstructBLIP 7B. Furthermore, we show that DOCCI is a useful testbed for text-to-image generation, highlighting the limitations of current text-to-image models in capturing long descriptions and fine details.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
A Benchmark for Learning to Translate a New Language from One Grammar Book
Sep 28, 2023



Large language models (LLMs) can perform impressive feats with in-context learning or lightweight finetuning. It is natural to wonder how well these models adapt to genuinely new tasks, but how does one find tasks that are unseen in internet-scale training sets? We turn to a field that is explicitly motivated and bottlenecked by a scarcity of web data: low-resource languages. In this paper, we introduce MTOB (Machine Translation from One Book), a benchmark for learning to translate between English and Kalamang -- a language with less than 200 speakers and therefore virtually no presence on the web -- using several hundred pages of field linguistics reference materials. This task framing is novel in that it asks a model to learn a language from a single human-readable book of grammar explanations, rather than a large mined corpus of in-domain data, more akin to L2 learning than L1 acquisition. We demonstrate that baselines using current LLMs are promising but fall short of human performance, achieving 44.7 chrF on Kalamang to English translation and 45.8 chrF on English to Kalamang translation, compared to 51.6 and 57.0 chrF by a human who learned Kalamang from the same reference materials. We hope that MTOB will help measure LLM capabilities along a new dimension, and that the methods developed to solve it could help expand access to language technology for underserved communities by leveraging qualitatively different kinds of data than traditional machine translation.