 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoCast: Forecasting Egocentric Human Pose in the Wild
Dec 03, 2024



Accurately estimating and forecasting human body pose is important for enhancing the user's sense of immersion in Augmented Reality. Addressing this need, our paper introduces EgoCast, a bimodal method for 3D human pose forecasting using egocentric videos and proprioceptive data. We study the task of human pose forecasting in a realistic setting, extending the boundaries of temporal forecasting in dynamic scenes and building on the current framework for current pose estimation in the wild. We introduce a current-frame estimation module that generates pseudo-groundtruth poses for inference, eliminating the need for past groundtruth poses typically required by current methods during forecasting. Our experimental results on the recent Ego-Exo4D and Aria Digital Twin datasets validate EgoCast for real-life motion estimation. On the Ego-Exo4D Body Pose 2024 Challenge, our method significantly outperforms the state-of-the-art approaches, laying the groundwork for future research in human pose estimation and forecasting in unscripted activities with egocentric inputs.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Evaluating Numerical Reasoning in Text-to-Image Models
Jun 20, 2024



Text-to-image generative models are capable of producing high-quality images that often faithfully depict concepts described using natural language. In this work, we comprehensively evaluate a range of text-to-image models on numerical reasoning tasks of varying difficulty, and show that even the most advanced models have only rudimentary numerical skills. Specifically, their ability to correctly generate an exact number of objects in an image is limited to small numbers, it is highly dependent on the context the number term appears in, and it deteriorates quickly with each successive number. We also demonstrate that models have poor understanding of linguistic quantifiers (such as "a few" or "as many as"), the concept of zero, and struggle with more advanced concepts such as partial quantities and fractional representations. We bundle prompts, generated images and human annotations into GeckoNum, a novel benchmark for evaluation of numerical reasoning.
Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
May 27, 2024



We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
DOCCI: Descriptions of Connected and Contrasting Images
Apr 30, 2024



Vision-language datasets are vital for both text-to-image (T2I) and image-to-text (I2T) research. However, current datasets lack descriptions with fine-grained detail that would allow for richer associations to be learned by models. To fill the gap, we introduce Descriptions of Connected and Contrasting Images (DOCCI), a dataset with long, human-annotated English descriptions for 15k images that were taken, curated and donated by a single researcher intent on capturing key challenges such as spatial relations, counting, text rendering, world knowledge, and more. We instruct human annotators to create comprehensive descriptions for each image; these average 136 words in length and are crafted to clearly distinguish each image from those that are related or similar. Each description is highly compositional and typically encompasses multiple challenges. Through both quantitative and qualitative analyses, we demonstrate that DOCCI serves as an effective training resource for image-to-text generation -- a PaLI 5B model finetuned on DOCCI shows equal or superior results compared to highly-performant larger models like LLaVA-1.5 7B and InstructBLIP 7B. Furthermore, we show that DOCCI is a useful testbed for text-to-image generation, highlighting the limitations of current text-to-image models in capturing long descriptions and fine details.
Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings
Apr 25, 2024While text-to-image (T2I) generative models have become ubiquitous, they do not necessarily generate images that align with a given prompt. While previous work has evaluated T2I alignment by proposing metrics, benchmarks, and templates for collecting human judgements, the quality of these components is not systematically measured. Human-rated prompt sets are generally small and the reliability of the ratings -- and thereby the prompt set used to compare models -- is not evaluated. We address this gap by performing an extensive study evaluating auto-eval metrics and human templates. We provide three main contributions: (1) We introduce a comprehensive skills-based benchmark that can discriminate models across different human templates. This skills-based benchmark categorises prompts into sub-skills, allowing a practitioner to pinpoint not only which skills are challenging, but at what level of complexity a skill becomes challenging. (2) We gather human ratings across four templates and four T2I models for a total of >100K annotations. This allows us to understand where differences arise due to inherent ambiguity in the prompt and where they arise due to differences in metric and model quality. (3) Finally, we introduce a new QA-based auto-eval metric that is better correlated with human ratings than existing metrics for our new dataset, across different human templates, and on TIFA160.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Rich Human Feedback for Text-to-Image Generation
Dec 15, 2023
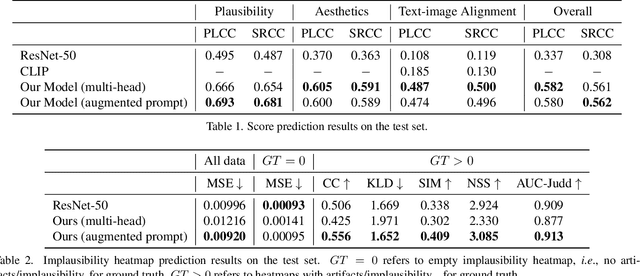
Recent Text-to-Image (T2I) generation models such as Stable Diffusion and Imagen have made significant progress in generating high-resolution images based on text descriptions. However, many generated images still suffer from issues such as artifacts/implausibility, misalignment with text descriptions, and low aesthetic quality. Inspired by the success of Reinforcement Learning with Human Feedback (RLHF) for large language models, prior works collected human-provided scores as feedback on generated images and trained a reward model to improve the T2I generation. In this paper, we enrich the feedback signal by (i) marking image regions that are implausible or misaligned with the text, and (ii) annotating which words in the text prompt are misrepresented or missing on the image. We collect such rich human feedback on 18K generated images and train a multimodal transformer to predict the rich feedback automatically. We show that the predicted rich human feedback can be leveraged to improve image generation, for example, by selecting high-quality training data to finetune and improve the generative models, or by creating masks with predicted heatmaps to inpaint the problematic regions. Notably, the improvements generalize to models (Muse) beyond those used to generate the images on which human feedback data were collected (Stable Diffusion variants).
Davidsonian Scene Graph: Improving Reliability in Fine-grained Evaluation for Text-to-Image Generation
Oct 30, 2023
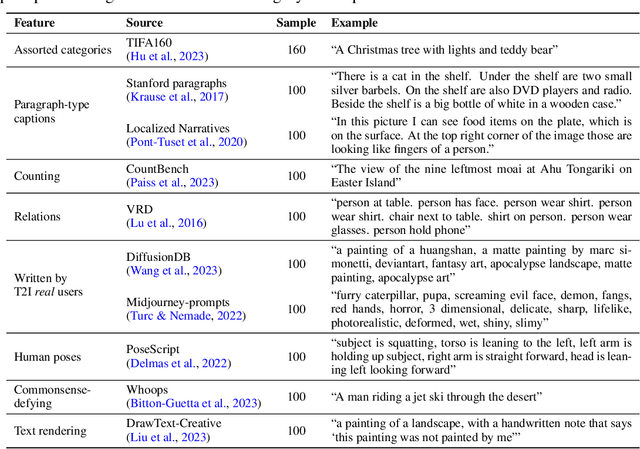

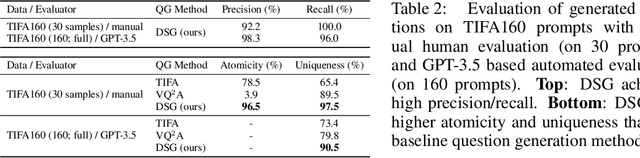
Evaluating text-to-image models is notoriously difficult. A strong recent approach for assessing text-image faithfulness is based on QG/A (question generation and answering), which uses pre-trained foundational models to automatically generate a set of questions and answers from the prompt, and output images are scored based on whether these answers extracted with a visual question answering model are consistent with the prompt-based answers. This kind of evaluation is naturally dependent on the quality of the underlying QG and QA models. We identify and address several reliability challenges in existing QG/A work: (a) QG questions should respect the prompt (avoiding hallucinations, duplications, and omissions) and (b) VQA answers should be consistent (not asserting that there is no motorcycle in an image while also claiming the motorcycle is blue). We address these issues with Davidsonian Scene Graph (DSG), an empirically grounded evaluation framework inspired by formal semantics. DSG is an automatic, graph-based QG/A that is modularly implemented to be adaptable to any QG/A module. DSG produces atomic and unique questions organized in dependency graphs, which (i) ensure appropriate semantic coverage and (ii) sidestep inconsistent answers. With extensive experimentation and human evaluation on a range of model configurations (LLM, VQA, and T2I), we empirically demonstrate that DSG addresses the challenges noted above. Finally, we present DSG-1k, an open-sourced evaluation benchmark that includes 1,060 prompts, covering a wide range of fine-grained semantic categories with a balanced distribution. We release the DSG-1k prompts and the corresponding DSG questions.
EgoCOL: Egocentric Camera pose estimation for Open-world 3D object Localization @Ego4D challenge 2023
Jun 29, 2023



We present EgoCOL, an egocentric camera pose estimation method for open-world 3D object localization. Our method leverages sparse camera pose reconstructions in a two-fold manner, video and scan independently, to estimate the camera pose of egocentric frames in 3D renders with high recall and precision. We extensively evaluate our method on the Visual Query (VQ) 3D object localization Ego4D benchmark. EgoCOL can estimate 62% and 59% more camera poses than the Ego4D baseline in the Ego4D Visual Queries 3D Localization challenge at CVPR 2023 in the val and test sets, respectively. Our code is publicly available at https://github.com/BCV-Uniandes/EgoCOL