 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus-N-Fix: Region-Aware Fine-Tuning for Text-to-Image Generation
Jan 11, 2025

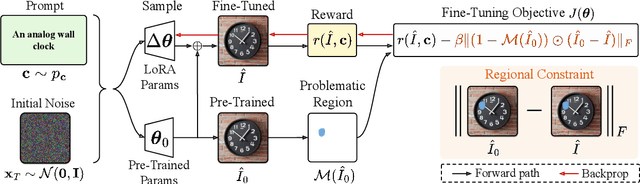
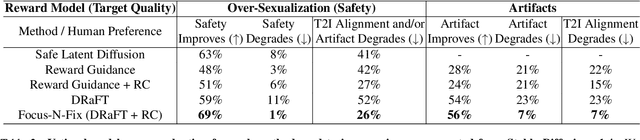
Text-to-image (T2I) generation has made significant advances in recent years, but challenges still remain in the generation of perceptual artifacts, misalignment with complex prompts, and safety. The prevailing approach to address these issues involves collecting human feedback on generated images, training reward models to estimate human feedback, and then fine-tuning T2I models based on the reward models to align them with human preferences. However, while existing reward fine-tuning methods can produce images with higher rewards, they may change model behavior in unexpected ways. For example, fine-tuning for one quality aspect (e.g., safety) may degrade other aspects (e.g., prompt alignment), or may lead to reward hacking (e.g., finding a way to increase rewards without having the intended effect). In this paper, we propose Focus-N-Fix, a region-aware fine-tuning method that trains models to correct only previously problematic image regions. The resulting fine-tuned model generates images with the same high-level structure as the original model but shows significant improvements in regions where the original model was deficient in safety (over-sexualization and violence), plausibility, or other criteria. Our experiments demonstrate that Focus-N-Fix improves these localized quality aspects with little or no degradation to others and typically imperceptible changes in the rest of the image. Disclaimer: This paper contains images that may be overly sexual, violent, offensive, or harmful.
Rich Human Feedback for Text-to-Image Generation
Dec 15, 2023
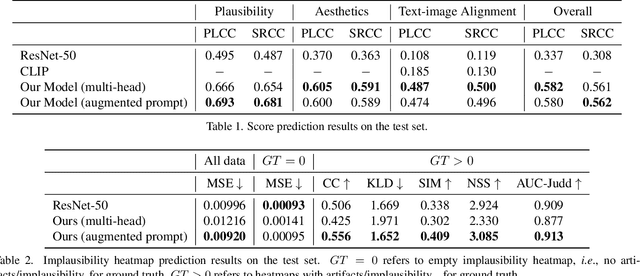
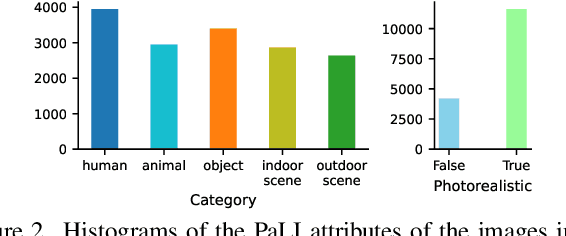
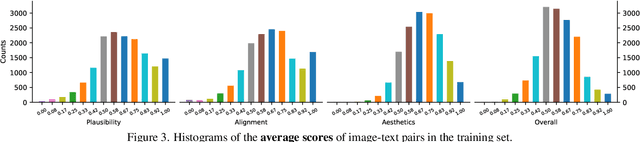
Recent Text-to-Image (T2I) generation models such as Stable Diffusion and Imagen have made significant progress in generating high-resolution images based on text descriptions. However, many generated images still suffer from issues such as artifacts/implausibility, misalignment with text descriptions, and low aesthetic quality. Inspired by the success of Reinforcement Learning with Human Feedback (RLHF) for large language models, prior works collected human-provided scores as feedback on generated images and trained a reward model to improve the T2I generation. In this paper, we enrich the feedback signal by (i) marking image regions that are implausible or misaligned with the text, and (ii) annotating which words in the text prompt are misrepresented or missing on the image. We collect such rich human feedback on 18K generated images and train a multimodal transformer to predict the rich feedback automatically. We show that the predicted rich human feedback can be leveraged to improve image generation, for example, by selecting high-quality training data to finetune and improve the generative models, or by creating masks with predicted heatmaps to inpaint the problematic regions. Notably, the improvements generalize to models (Muse) beyond those used to generate the images on which human feedback data were collected (Stable Diffusion variants).
Playful Interactions for Representation Learning
Jul 19, 2021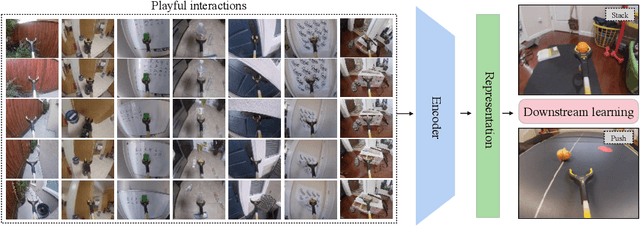


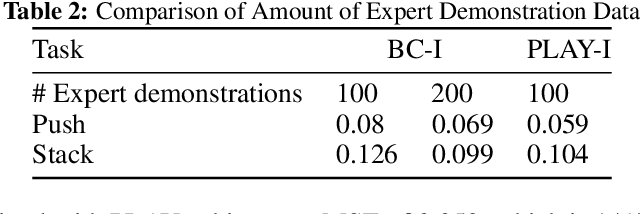
One of the key challenges in visual imitation learning is collecting large amounts of expert demonstrations for a given task. While methods for collecting human demonstrations are becoming easier with teleoperation methods and the use of low-cost assistive tools, we often still require 100-1000 demonstrations for every task to learn a visual representation and policy. To address this, we turn to an alternate form of data that does not require task-specific demonstrations -- play. Playing is a fundamental method children use to learn a set of skills and behaviors and visual representations in early learning. Importantly, play data is diverse, task-agnostic, and relatively cheap to obtain. In this work, we propose to use playful interactions in a self-supervised manner to learn visual representations for downstream tasks. We collect 2 hours of playful data in 19 diverse environments and use self-predictive learning to extract visual representations. Given these representations, we train policies using imitation learning for two downstream tasks: Pushing and Stacking. We demonstrate that our visual representations generalize better than standard behavior cloning and can achieve similar performance with only half the number of required demonstrations. Our representations, which are trained from scratch, compare favorably against ImageNet pretrained representations. Finally, we provide an experimental analysis on the effects of different pretraining modes on downstream task learning.
Visual Imitation Made Easy
Aug 11, 2020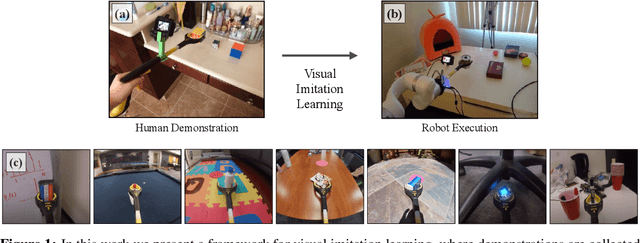



Visual imitation learning provides a framework for learning complex manipulation behaviors by leveraging human demonstrations. However, current interfaces for imitation such as kinesthetic teaching or teleoperation prohibitively restrict our ability to efficiently collect large-scale data in the wild. Obtaining such diverse demonstration data is paramount for the generalization of learned skills to novel scenarios. In this work, we present an alternate interface for imitation that simplifies the data collection process while allowing for easy transfer to robots. We use commercially available reacher-grabber assistive tools both as a data collection device and as the robot's end-effector. To extract action information from these visual demonstrations, we use off-the-shelf Structure from Motion (SfM) techniques in addition to training a finger detection network. We experimentally evaluate on two challenging tasks: non-prehensile pushing and prehensile stacking, with 1000 diverse demonstrations for each task. For both tasks, we use standard behavior cloning to learn executable policies from the previously collected offline demonstrations. To improve learning performance, we employ a variety of data augmentations and provide an extensive analysis of its effects. Finally, we demonstrate the utility of our interface by evaluating on real robotic scenarios with previously unseen objects and achieve a 87% success rate on pushing and a 62% success rate on stacking. Robot videos are available at https://dhiraj100892.github.io/Visual-Imitation-Made-Easy.