 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL's Razor: Why Online Reinforcement Learning Forgets Less
Sep 04, 2025Comparison of fine-tuning models with reinforcement learning (RL) and supervised fine-tuning (SFT) reveals that, despite similar performance at a new task, RL preserves prior knowledge and capabilities significantly better. We find that the degree of forgetting is determined by the distributional shift, measured as the KL-divergence between the fine-tuned and base policy evaluated on the new task. Our analysis reveals that on-policy RL is implicitly biased towards KL-minimal solutions among the many that solve the new task, whereas SFT can converge to distributions arbitrarily far from the base model. We validate these findings through experiments with large language models and robotic foundation models and further provide theoretical justification for why on-policy RL updates lead to a smaller KL change. We term this principle $\textit{RL's Razor}$: among all ways to solve a new task, RL prefers those closest in KL to the original model.
Self-Adapting Language Models
Jun 12, 2025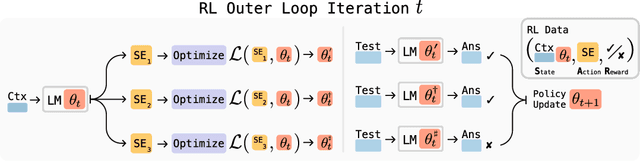


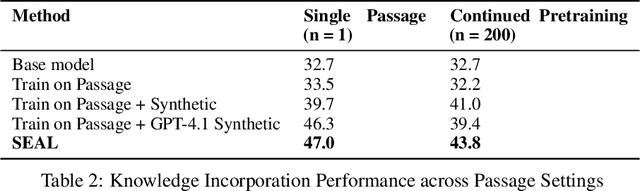
Large language models (LLMs) are powerful but static; they lack mechanisms to adapt their weights in response to new tasks, knowledge, or examples. We introduce Self-Adapting LLMs (SEAL), a framework that enables LLMs to self-adapt by generating their own finetuning data and update directives. Given a new input, the model produces a self-edit-a generation that may restructure the information in different ways, specify optimization hyperparameters, or invoke tools for data augmentation and gradient-based updates. Through supervised finetuning (SFT), these self-edits result in persistent weight updates, enabling lasting adaptation. To train the model to produce effective self-edits, we use a reinforcement learning loop with the downstream performance of the updated model as the reward signal. Unlike prior approaches that rely on separate adaptation modules or auxiliary networks, SEAL directly uses the model's own generation to control its adaptation process. Experiments on knowledge incorporation and few-shot generalization show that SEAL is a promising step toward language models capable of self-directed adaptation. Our website and code is available at https://jyopari.github.io/posts/seal.
General Reasoning Requires Learning to Reason from the Get-go
Feb 26, 2025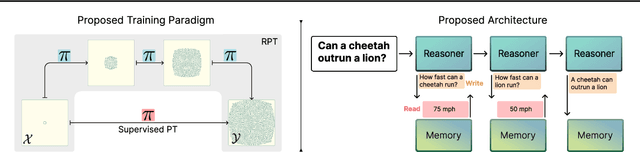
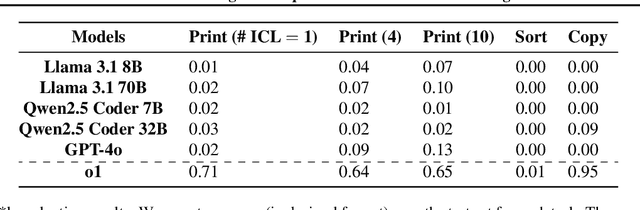
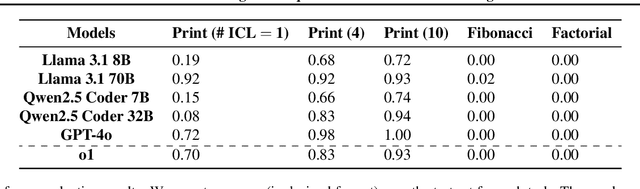
Large Language Models (LLMs) have demonstrated impressive real-world utility, exemplifying artificial useful intelligence (AUI). However, their ability to reason adaptively and robustly -- the hallmarks of artificial general intelligence (AGI) -- remains fragile. While LLMs seemingly succeed in commonsense reasoning, programming, and mathematics, they struggle to generalize algorithmic understanding across novel contexts. Our experiments with algorithmic tasks in esoteric programming languages reveal that LLM's reasoning overfits to the training data and is limited in its transferability. We hypothesize that the core issue underlying such limited transferability is the coupling of reasoning and knowledge in LLMs. To transition from AUI to AGI, we propose disentangling knowledge and reasoning through three key directions: (1) pretaining to reason using RL from scratch as an alternative to the widely used next-token prediction pretraining, (2) using a curriculum of synthetic tasks to ease the learning of a \textit{reasoning prior} for RL that can then be transferred to natural language tasks, and (3) learning more generalizable reasoning functions using a small context window to reduce exploiting spurious correlations between tokens. Such a reasoning system coupled with a trained retrieval system and a large external memory bank as a knowledge store can overcome several limitations of existing architectures at learning to reason in novel scenarios.
Efficient Diffusion Transformer Policies with Mixture of Expert Denoisers for Multitask Learning
Dec 17, 2024Diffusion Policies have become widely used in Imitation Learning, offering several appealing properties, such as generating multimodal and discontinuous behavior. As models are becoming larger to capture more complex capabilities, their computational demands increase, as shown by recent scaling laws. Therefore, continuing with the current architectures will present a computational roadblock. To address this gap, we propose Mixture-of-Denoising Experts (MoDE) as a novel policy for Imitation Learning. MoDE surpasses current state-of-the-art Transformer-based Diffusion Policies while enabling parameter-efficient scaling through sparse experts and noise-conditioned routing, reducing both active parameters by 40% and inference costs by 90% via expert caching. Our architecture combines this efficient scaling with noise-conditioned self-attention mechanism, enabling more effective denoising across different noise levels. MoDE achieves state-of-the-art performance on 134 tasks in four established imitation learning benchmarks (CALVIN and LIBERO). Notably, by pretraining MoDE on diverse robotics data, we achieve 4.01 on CALVIN ABC and 0.95 on LIBERO-90. It surpasses both CNN-based and Transformer Diffusion Policies by an average of 57% across 4 benchmarks, while using 90% fewer FLOPs and fewer active parameters compared to default Diffusion Transformer architectures. Furthermore, we conduct comprehensive ablations on MoDE's components, providing insights for designing efficient and scalable Transformer architectures for Diffusion Policies. Code and demonstrations are available at https://mbreuss.github.io/MoDE_Diffusion_Policy/.
Few-Shot Task Learning through Inverse Generative Modeling
Nov 07, 2024



Learning the intents of an agent, defined by its goals or motion style, is often extremely challenging from just a few examples. We refer to this problem as task concept learning and present our approach, Few-Shot Task Learning through Inverse Generative Modeling (FTL-IGM), which learns new task concepts by leveraging invertible neural generative models. The core idea is to pretrain a generative model on a set of basic concepts and their demonstrations. Then, given a few demonstrations of a new concept (such as a new goal or a new action), our method learns the underlying concepts through backpropagation without updating the model weights, thanks to the invertibility of the generative model. We evaluate our method in five domains -- object rearrangement, goal-oriented navigation, motion caption of human actions, autonomous driving, and real-world table-top manipulation. Our experimental results demonstrate that via the pretrained generative model, we successfully learn novel concepts and generate agent plans or motion corresponding to these concepts in (1) unseen environments and (2) in composition with training concepts.
Collective Model Intelligence Requires Compatible Specialization
Nov 04, 2024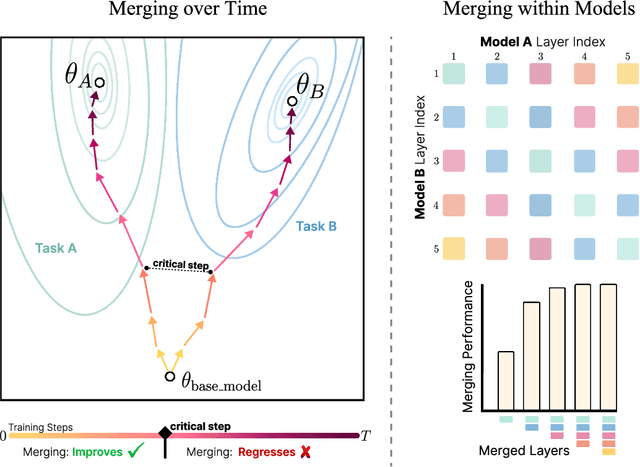

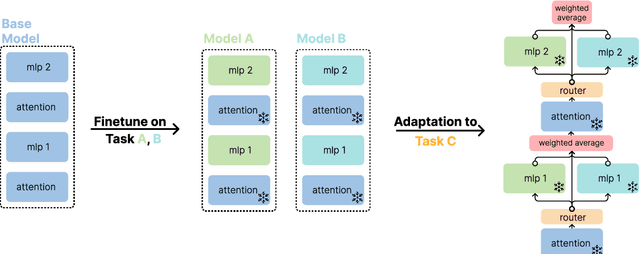

In this work, we explore the limitations of combining models by averaging intermediate features, referred to as model merging, and propose a new direction for achieving collective model intelligence through what we call compatible specialization. Current methods for model merging, such as parameter and feature averaging, struggle to effectively combine specialized models due to representational divergence during fine-tuning. As models specialize to their individual domains, their internal feature representations become increasingly incompatible, leading to poor performance when attempting to merge them for new tasks. We analyze this phenomenon using centered kernel alignment (CKA) and show that as models specialize, the similarity in their feature space structure diminishes, hindering their capacity for collective use. To address these challenges, we investigate routing-based merging strategies, which offer more flexible methods for combining specialized models by dynamically routing across different layers. This allows us to improve on existing methods by combining features from multiple layers rather than relying on fixed, layer-wise combinations. However, we find that these approaches still face limitations when layers within models are representationally incompatible. Our findings highlight the importance of designing new approaches for model merging that operate on well-defined input and output spaces, similar to how humans communicate through language rather than intermediate neural activations.
Train Offline, Test Online: A Real Robot Learning Benchmark
Jun 01, 2023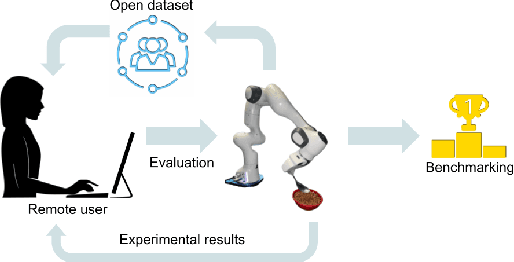
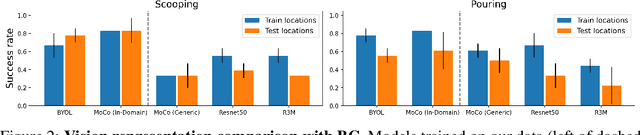
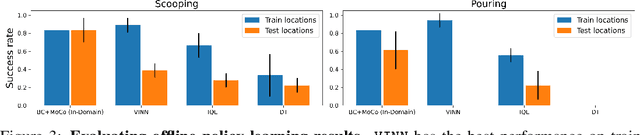

Three challenges limit the progress of robot learning research: robots are expensive (few labs can participate), everyone uses different robots (findings do not generalize across labs), and we lack internet-scale robotics data. We take on these challenges via a new benchmark: Train Offline, Test Online (TOTO). TOTO provides remote users with access to shared robotic hardware for evaluating methods on common tasks and an open-source dataset of these tasks for offline training. Its manipulation task suite requires challenging generalization to unseen objects, positions, and lighting. We present initial results on TOTO comparing five pretrained visual representations and four offline policy learning baselines, remotely contributed by five institutions. The real promise of TOTO, however, lies in the future: we release the benchmark for additional submissions from any user, enabling easy, direct comparison to several methods without the need to obtain hardware or collect data.
Teach a Robot to FISH: Versatile Imitation from One Minute of Demonstrations
Mar 02, 2023


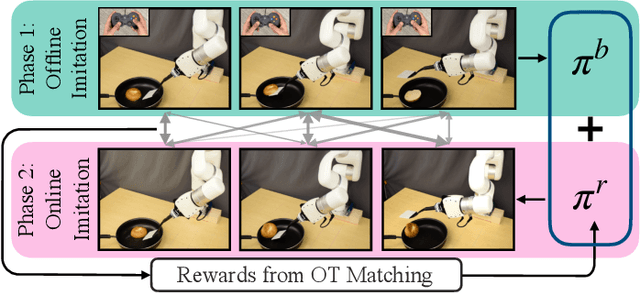
While imitation learning provides us with an efficient toolkit to train robots, learning skills that are robust to environment variations remains a significant challenge. Current approaches address this challenge by relying either on large amounts of demonstrations that span environment variations or on handcrafted reward functions that require state estimates. Both directions are not scalable to fast imitation. In this work, we present Fast Imitation of Skills from Humans (FISH), a new imitation learning approach that can learn robust visual skills with less than a minute of human demonstrations. Given a weak base-policy trained by offline imitation of demonstrations, FISH computes rewards that correspond to the "match" between the robot's behavior and the demonstrations. These rewards are then used to adaptively update a residual policy that adds on to the base-policy. Across all tasks, FISH requires at most twenty minutes of interactive learning to imitate demonstrations on object configurations that were not seen in the demonstrations. Importantly, FISH is constructed to be versatile, which allows it to be used across robot morphologies (e.g. xArm, Allegro, Stretch) and camera configurations (e.g. third-person, eye-in-hand). Our experimental evaluations on 9 different tasks show that FISH achieves an average success rate of 93%, which is around 3.8x higher than prior state-of-the-art methods.
The Surprising Effectiveness of Representation Learning for Visual Imitation
Dec 06, 2021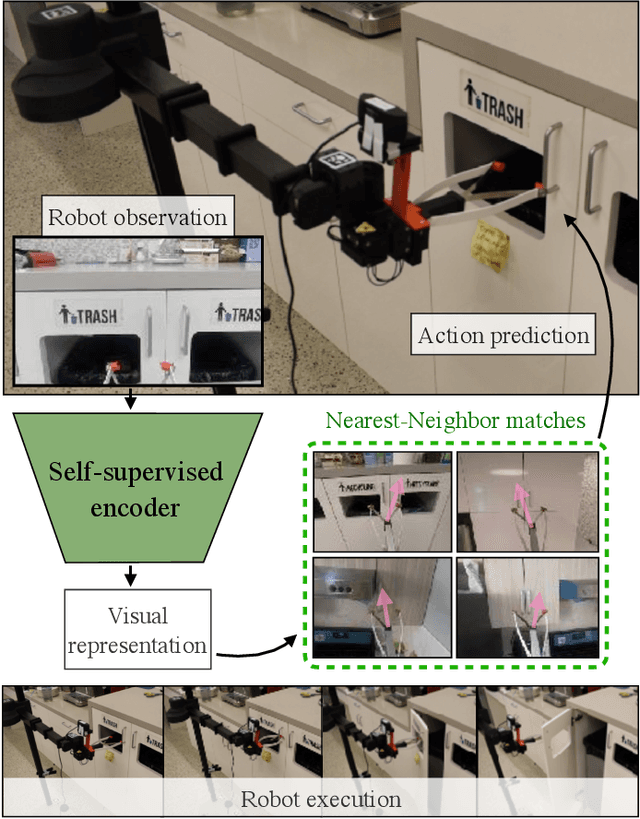
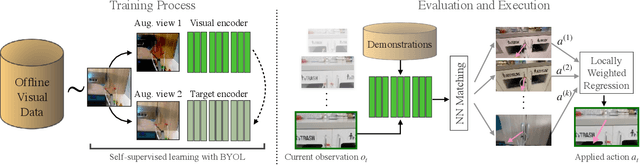

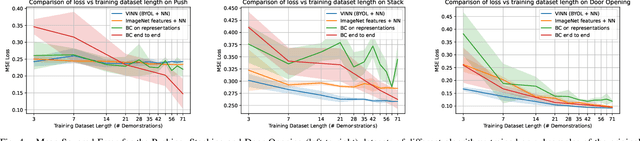
While visual imitation learning offers one of the most effective ways of learning from visual demonstrations, generalizing from them requires either hundreds of diverse demonstrations, task specific priors, or large, hard-to-train parametric models. One reason such complexities arise is because standard visual imitation frameworks try to solve two coupled problems at once: learning a succinct but good representation from the diverse visual data, while simultaneously learning to associate the demonstrated actions with such representations. Such joint learning causes an interdependence between these two problems, which often results in needing large amounts of demonstrations for learning. To address this challenge, we instead propose to decouple representation learning from behavior learning for visual imitation. First, we learn a visual representation encoder from offline data using standard supervised and self-supervised learning methods. Once the representations are trained, we use non-parametric Locally Weighted Regression to predict the actions. We experimentally show that this simple decoupling improves the performance of visual imitation models on both offline demonstration datasets and real-robot door opening compared to prior work in visual imitation. All of our generated data, code, and robot videos are publicly available at https://jyopari.github.io/VINN/.
Playful Interactions for Representation Learning
Jul 19, 2021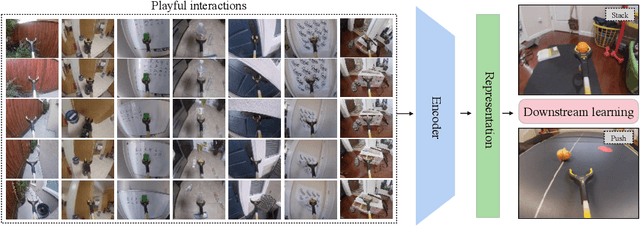


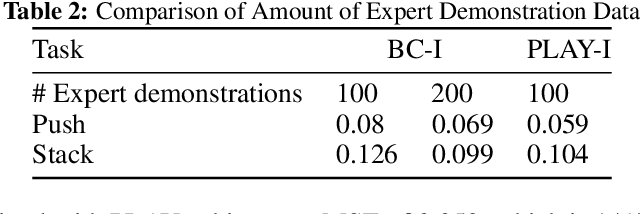
One of the key challenges in visual imitation learning is collecting large amounts of expert demonstrations for a given task. While methods for collecting human demonstrations are becoming easier with teleoperation methods and the use of low-cost assistive tools, we often still require 100-1000 demonstrations for every task to learn a visual representation and policy. To address this, we turn to an alternate form of data that does not require task-specific demonstrations -- play. Playing is a fundamental method children use to learn a set of skills and behaviors and visual representations in early learning. Importantly, play data is diverse, task-agnostic, and relatively cheap to obtain. In this work, we propose to use playful interactions in a self-supervised manner to learn visual representations for downstream tasks. We collect 2 hours of playful data in 19 diverse environments and use self-predictive learning to extract visual representations. Given these representations, we train policies using imitation learning for two downstream tasks: Pushing and Stacking. We demonstrate that our visual representations generalize better than standard behavior cloning and can achieve similar performance with only half the number of required demonstrations. Our representations, which are trained from scratch, compare favorably against ImageNet pretrained representations. Finally, we provide an experimental analysis on the effects of different pretraining modes on downstream task learning.