 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTune to Learn: How Controller Gains Shape Robot Policy Learning
Apr 02, 2026Position controllers have become the dominant interface for executing learned manipulation policies. Yet a critical design decision remains understudied: how should we choose controller gains for policy learning? The conventional wisdom is to select gains based on desired task compliance or stiffness. However, this logic breaks down when controllers are paired with state-conditioned policies: effective stiffness emerges from the interplay between learned reactions and control dynamics, not from gains alone. We argue that gain selection should instead be guided by learnability: how amenable different gain settings are to the learning algorithm in use. In this work, we systematically investigate how position controller gains affect three core components of modern robot learning pipelines: behavior cloning, reinforcement learning from scratch, and sim-to-real transfer. Through extensive experiments across multiple tasks and robot embodiments, we find that: (1) behavior cloning benefits from compliant and overdamped gain regimes, (2) reinforcement learning can succeed across all gain regimes given compatible hyperparameter tuning, and (3) sim-to-real transfer is harmed by stiff and overdamped gain regimes. These findings reveal that optimal gain selection depends not on the desired task behavior, but on the learning paradigm employed. Project website: https://younghyopark.me/tune-to-learn
ExoStart: Efficient learning for dexterous manipulation with sensorized exoskeleton demonstrations
Jun 13, 2025



Recent advancements in teleoperation systems have enabled high-quality data collection for robotic manipulators, showing impressive results in learning manipulation at scale. This progress suggests that extending these capabilities to robotic hands could unlock an even broader range of manipulation skills, especially if we could achieve the same level of dexterity that human hands exhibit. However, teleoperating robotic hands is far from a solved problem, as it presents a significant challenge due to the high degrees of freedom of robotic hands and the complex dynamics occurring during contact-rich settings. In this work, we present ExoStart, a general and scalable learning framework that leverages human dexterity to improve robotic hand control. In particular, we obtain high-quality data by collecting direct demonstrations without a robot in the loop using a sensorized low-cost wearable exoskeleton, capturing the rich behaviors that humans can demonstrate with their own hands. We also propose a simulation-based dynamics filter that generates dynamically feasible trajectories from the collected demonstrations and use the generated trajectories to bootstrap an auto-curriculum reinforcement learning method that relies only on simple sparse rewards. The ExoStart pipeline is generalizable and yields robust policies that transfer zero-shot to the real robot. Our results demonstrate that ExoStart can generate dexterous real-world hand skills, achieving a success rate above 50% on a wide range of complex tasks such as opening an AirPods case or inserting and turning a key in a lock. More details and videos can be found in https://sites.google.com/view/exostart.
Few-Shot Task Learning through Inverse Generative Modeling
Nov 07, 2024



Learning the intents of an agent, defined by its goals or motion style, is often extremely challenging from just a few examples. We refer to this problem as task concept learning and present our approach, Few-Shot Task Learning through Inverse Generative Modeling (FTL-IGM), which learns new task concepts by leveraging invertible neural generative models. The core idea is to pretrain a generative model on a set of basic concepts and their demonstrations. Then, given a few demonstrations of a new concept (such as a new goal or a new action), our method learns the underlying concepts through backpropagation without updating the model weights, thanks to the invertibility of the generative model. We evaluate our method in five domains -- object rearrangement, goal-oriented navigation, motion caption of human actions, autonomous driving, and real-world table-top manipulation. Our experimental results demonstrate that via the pretrained generative model, we successfully learn novel concepts and generate agent plans or motion corresponding to these concepts in (1) unseen environments and (2) in composition with training concepts.
Autonomous Robotic Assembly: From Part Singulation to Precise Assembly
Jun 11, 2024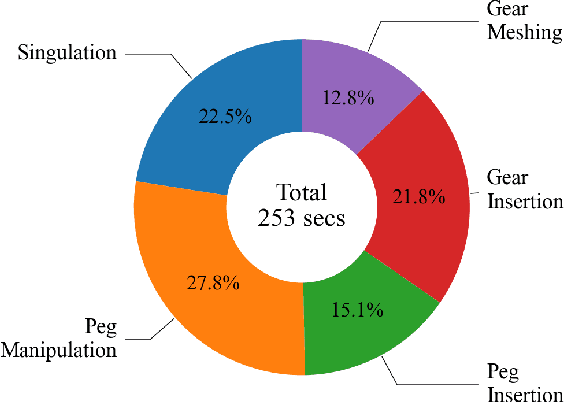
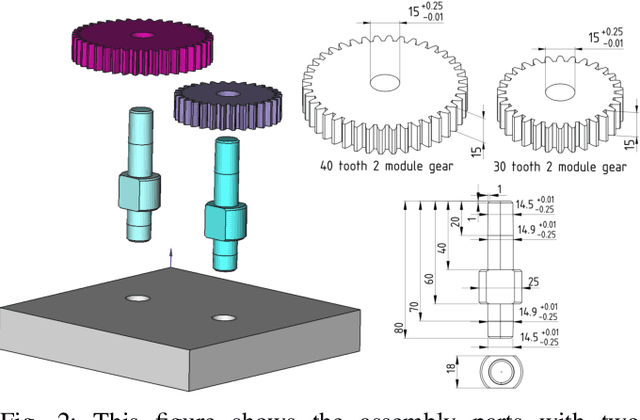


Imagine a robot that can assemble a functional product from the individual parts presented in any configuration to the robot. Designing such a robotic system is a complex problem which presents several open challenges. To bypass these challenges, the current generation of assembly systems is built with a lot of system integration effort to provide the structure and precision necessary for assembly. These systems are mostly responsible for part singulation, part kitting, and part detection, which is accomplished by intelligent system design. In this paper, we present autonomous assembly of a gear box with minimum requirements on structure. The assembly parts are randomly placed in a two-dimensional work environment for the robot. The proposed system makes use of several different manipulation skills such as sliding for grasping, in-hand manipulation, and insertion to assemble the gear box. All these tasks are run in a closed-loop fashion using vision, tactile, and Force-Torque (F/T) sensors. We perform extensive hardware experiments to show the robustness of the proposed methods as well as the overall system. See supplementary video at https://www.youtube.com/watch?v=cZ9M1DQ23OI.
TEXterity -- Tactile Extrinsic deXterity: Simultaneous Tactile Estimation and Control for Extrinsic Dexterity
Mar 04, 2024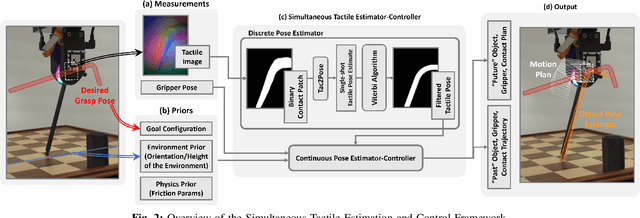
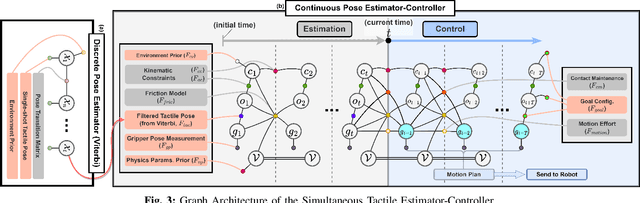
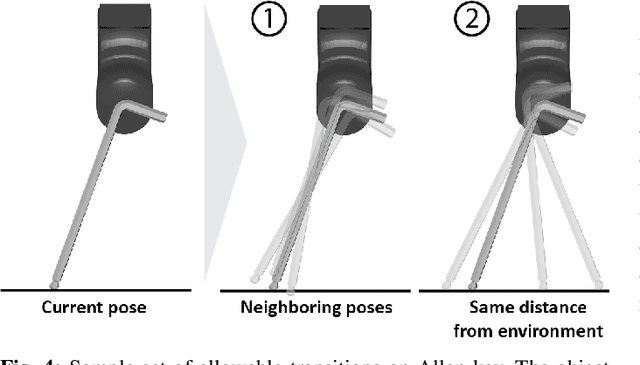
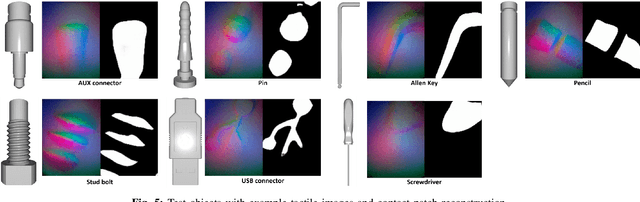
We introduce a novel approach that combines tactile estimation and control for in-hand object manipulation. By integrating measurements from robot kinematics and an image-based tactile sensor, our framework estimates and tracks object pose while simultaneously generating motion plans in a receding horizon fashion to control the pose of a grasped object. This approach consists of a discrete pose estimator that tracks the most likely sequence of object poses in a coarsely discretized grid, and a continuous pose estimator-controller to refine the pose estimate and accurately manipulate the pose of the grasped object. Our method is tested on diverse objects and configurations, achieving desired manipulation objectives and outperforming single-shot methods in estimation accuracy. The proposed approach holds potential for tasks requiring precise manipulation and limited intrinsic in-hand dexterity under visual occlusion, laying the foundation for closed-loop behavior in applications such as regrasping, insertion, and tool use. Please see https://sites.google.com/view/texterity for videos of real-world demonstrations.
TEXterity: Tactile Extrinsic deXterity
Jan 22, 2024



We introduce a novel approach that combines tactile estimation and control for in-hand object manipulation. By integrating measurements from robot kinematics and an image-based tactile sensor, our framework estimates and tracks object pose while simultaneously generating motion plans to control the pose of a grasped object. This approach consists of a discrete pose estimator that uses the Viterbi decoding algorithm to find the most likely sequence of object poses in a coarsely discretized grid, and a continuous pose estimator-controller to refine the pose estimate and accurately manipulate the pose of the grasped object. Our method is tested on diverse objects and configurations, achieving desired manipulation objectives and outperforming single-shot methods in estimation accuracy. The proposed approach holds potential for tasks requiring precise manipulation in scenarios where visual perception is limited, laying the foundation for closed-loop behavior applications such as assembly and tool use. Please see supplementary videos for real-world demonstration at https://sites.google.com/view/texterity.
simPLE: a visuotactile method learned in simulation to precisely pick, localize, regrasp, and place objects
Jul 24, 2023
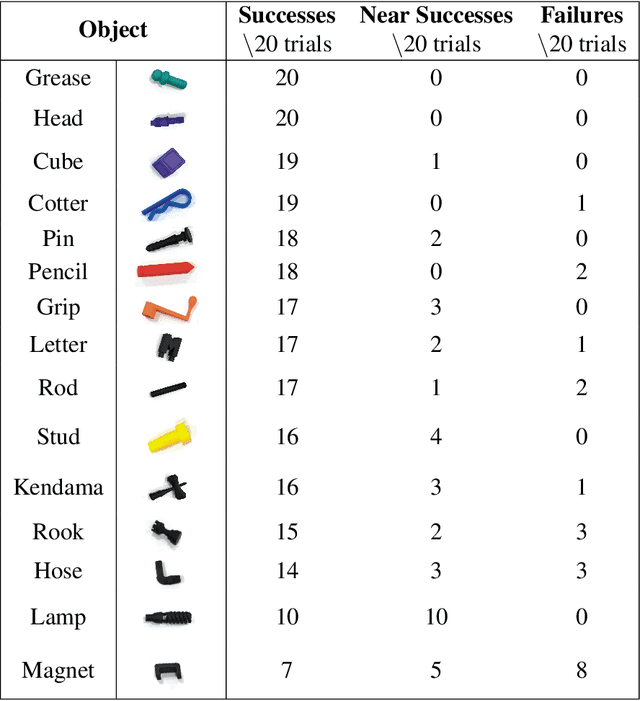
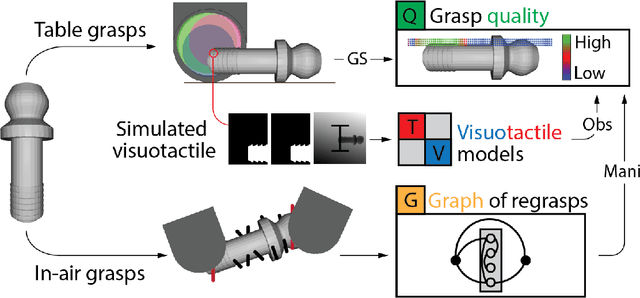
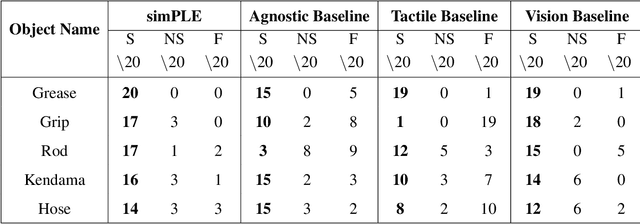
Existing robotic systems have a clear tension between generality and precision. Deployed solutions for robotic manipulation tend to fall into the paradigm of one robot solving a single task, lacking precise generalization, i.e., the ability to solve many tasks without compromising on precision. This paper explores solutions for precise and general pick-and-place. In precise pick-and-place, i.e. kitting, the robot transforms an unstructured arrangement of objects into an organized arrangement, which can facilitate further manipulation. We propose simPLE (simulation to Pick Localize and PLacE) as a solution to precise pick-and-place. simPLE learns to pick, regrasp and place objects precisely, given only the object CAD model and no prior experience. We develop three main components: task-aware grasping, visuotactile perception, and regrasp planning. Task-aware grasping computes affordances of grasps that are stable, observable, and favorable to placing. The visuotactile perception model relies on matching real observations against a set of simulated ones through supervised learning. Finally, we compute the desired robot motion by solving a shortest path problem on a graph of hand-to-hand regrasps. On a dual-arm robot equipped with visuotactile sensing, we demonstrate pick-and-place of 15 diverse objects with simPLE. The objects span a wide range of shapes and simPLE achieves successful placements into structured arrangements with 1mm clearance over 90% of the time for 6 objects, and over 80% of the time for 11 objects. Videos are available at http://mcube.mit.edu/research/simPLE.html .
Tac2Pose: Tactile Object Pose Estimation from the First Touch
Apr 25, 2022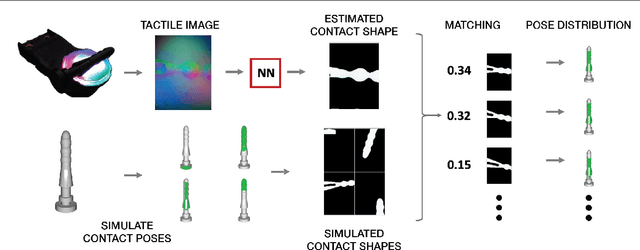
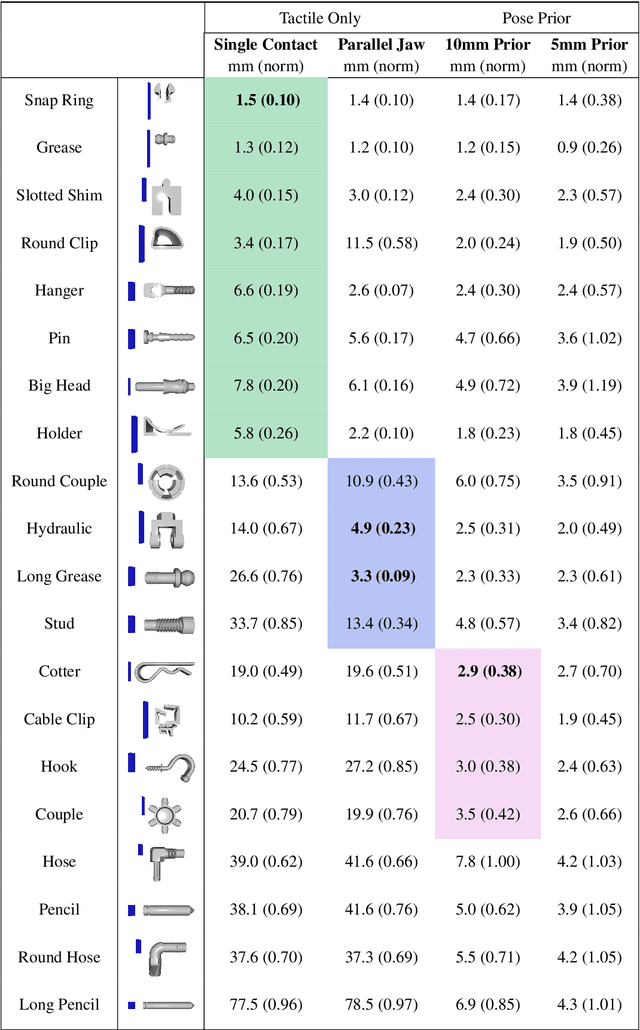
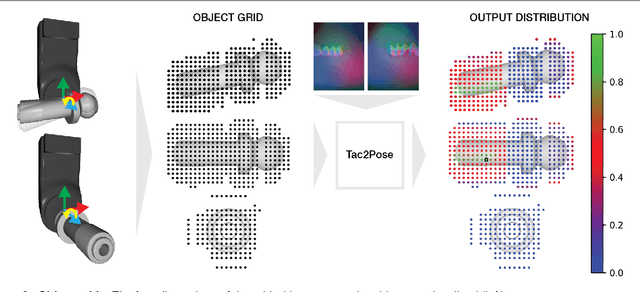
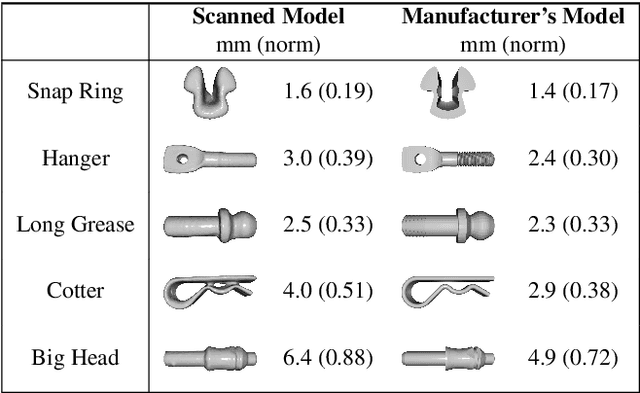
In this paper, we present Tac2Pose, an object-specific approach to tactile pose estimation from the first touch for known objects. Given the object geometry, we learn a tailored perception model in simulation that estimates a probability distribution over possible object poses given a tactile observation. To do so, we simulate the contact shapes that a dense set of object poses would produce on the sensor. Then, given a new contact shape obtained from the sensor, we match it against the pre-computed set using an object-specific embedding learned using contrastive learning. We obtain contact shapes from the sensor with an object-agnostic calibration step that maps RGB tactile observations to binary contact shapes. This mapping, which can be reused across object and sensor instances, is the only step trained with real sensor data. This results in a perception model that localizes objects from the first real tactile observation. Importantly, it produces pose distributions and can incorporate additional pose constraints coming from other perception systems, contacts, or priors. We provide quantitative results for 20 objects. Tac2Pose provides high accuracy pose estimations from distinctive tactile observations while regressing meaningful pose distributions to account for those contact shapes that could result from different object poses. We also test Tac2Pose on object models reconstructed from a 3D scanner, to evaluate the robustness to uncertainty in the object model. Finally, we demonstrate the advantages of Tac2Pose compared with three baseline methods for tactile pose estimation: directly regressing the object pose with a neural network, matching an observed contact to a set of possible contacts using a standard classification neural network, and direct pixel comparison of an observed contact with a set of possible contacts. Website: http://mcube.mit.edu/research/tac2pose.html
Inclined Surface Locomotion Strategies for Spherical Tensegrity Robots
Aug 27, 2017
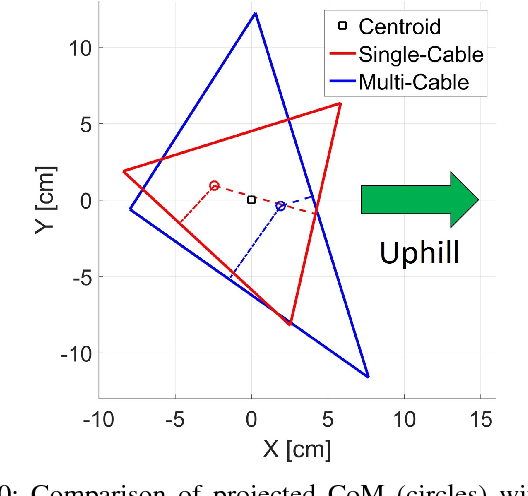
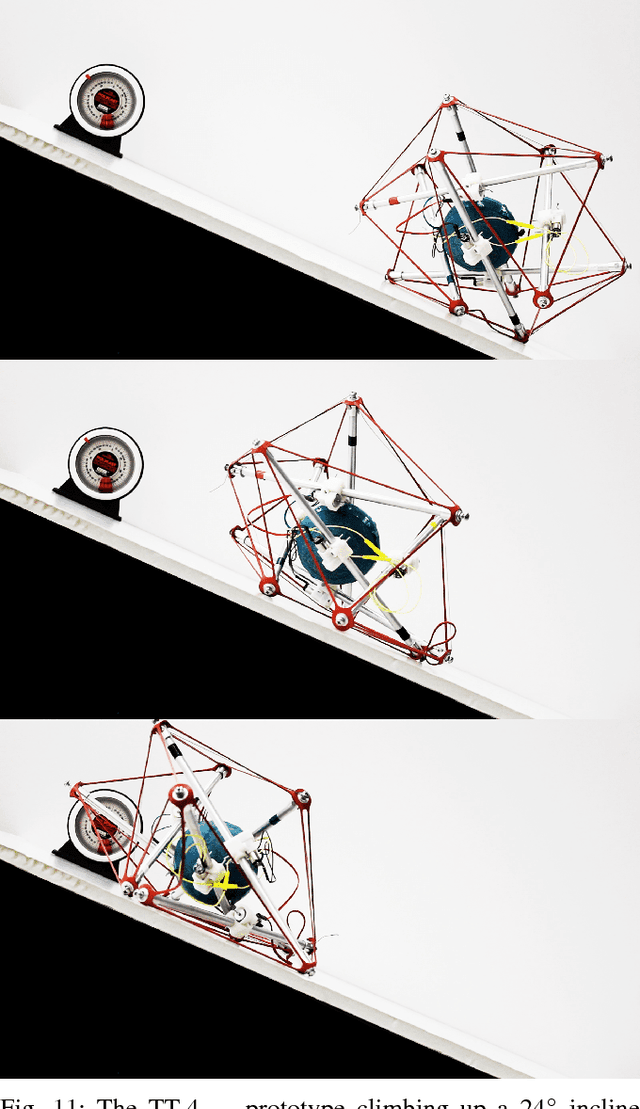
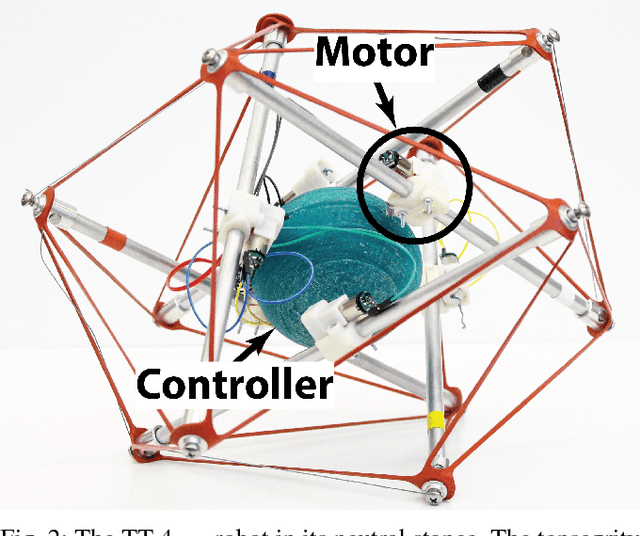
This paper presents a new teleoperated spherical tensegrity robot capable of performing locomotion on steep inclined surfaces. With a novel control scheme centered around the simultaneous actuation of multiple cables, the robot demonstrates robust climbing on inclined surfaces in hardware experiments and speeds significantly faster than previous spherical tensegrity models. This robot is an improvement over other iterations in the TT-series and the first tensegrity to achieve reliable locomotion on inclined surfaces of up to 24\degree. We analyze locomotion in simulation and hardware under single and multi-cable actuation, and introduce two novel multi-cable actuation policies, suited for steep incline climbing and speed, respectively. We propose compelling justifications for the increased dynamic ability of the robot and motivate development of optimization algorithms able to take advantage of the robot's increased control authority.