 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineControlNet: Fine-level Text Control for Image Generation with Spatially Aligned Text Control Injection
Dec 14, 2023Recently introduced ControlNet has the ability to steer the text-driven image generation process with geometric input such as human 2D pose, or edge features. While ControlNet provides control over the geometric form of the instances in the generated image, it lacks the capability to dictate the visual appearance of each instance. We present FineControlNet to provide fine control over each instance's appearance while maintaining the precise pose control capability. Specifically, we develop and demonstrate FineControlNet with geometric control via human pose images and appearance control via instance-level text prompts. The spatial alignment of instance-specific text prompts and 2D poses in latent space enables the fine control capabilities of FineControlNet. We evaluate the performance of FineControlNet with rigorous comparison against state-of-the-art pose-conditioned text-to-image diffusion models. FineControlNet achieves superior performance in generating images that follow the user-provided instance-specific text prompts and poses compared with existing methods. Project webpage: https://samsunglabs.github.io/FineControlNet-project-page
VioLA: Aligning Videos to 2D LiDAR Scans
Nov 08, 2023



We study the problem of aligning a video that captures a local portion of an environment to the 2D LiDAR scan of the entire environment. We introduce a method (VioLA) that starts with building a semantic map of the local scene from the image sequence, then extracts points at a fixed height for registering to the LiDAR map. Due to reconstruction errors or partial coverage of the camera scan, the reconstructed semantic map may not contain sufficient information for registration. To address this problem, VioLA makes use of a pre-trained text-to-image inpainting model paired with a depth completion model for filling in the missing scene content in a geometrically consistent fashion to support pose registration. We evaluate VioLA on two real-world RGB-D benchmarks, as well as a self-captured dataset of a large office scene. Notably, our proposed scene completion module improves the pose registration performance by up to 20%.
HandNeRF: Learning to Reconstruct Hand-Object Interaction Scene from a Single RGB Image
Sep 14, 2023



This paper presents a method to learn hand-object interaction prior for reconstructing a 3D hand-object scene from a single RGB image. The inference as well as training-data generation for 3D hand-object scene reconstruction is challenging due to the depth ambiguity of a single image and occlusions by the hand and object. We turn this challenge into an opportunity by utilizing the hand shape to constrain the possible relative configuration of the hand and object geometry. We design a generalizable implicit function, HandNeRF, that explicitly encodes the correlation of the 3D hand shape features and 2D object features to predict the hand and object scene geometry. With experiments on real-world datasets, we show that HandNeRF is able to reconstruct hand-object scenes of novel grasp configurations more accurately than comparable methods. Moreover, we demonstrate that object reconstruction from HandNeRF ensures more accurate execution of a downstream task, such as grasping for robotic hand-over.
simPLE: a visuotactile method learned in simulation to precisely pick, localize, regrasp, and place objects
Jul 24, 2023
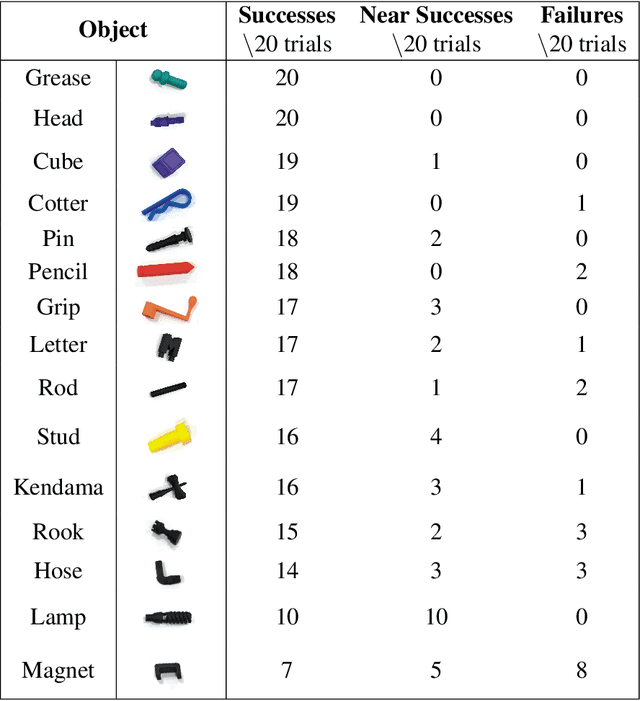
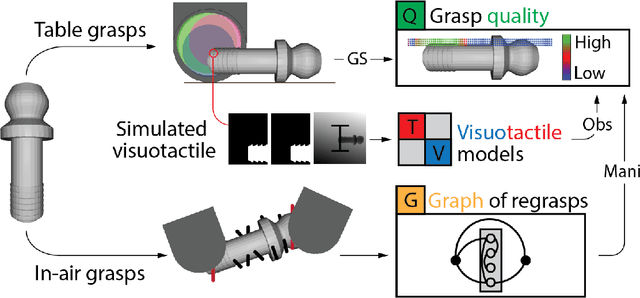
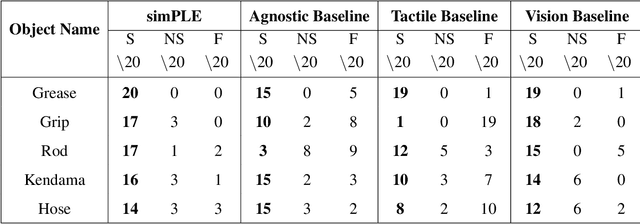
Existing robotic systems have a clear tension between generality and precision. Deployed solutions for robotic manipulation tend to fall into the paradigm of one robot solving a single task, lacking precise generalization, i.e., the ability to solve many tasks without compromising on precision. This paper explores solutions for precise and general pick-and-place. In precise pick-and-place, i.e. kitting, the robot transforms an unstructured arrangement of objects into an organized arrangement, which can facilitate further manipulation. We propose simPLE (simulation to Pick Localize and PLacE) as a solution to precise pick-and-place. simPLE learns to pick, regrasp and place objects precisely, given only the object CAD model and no prior experience. We develop three main components: task-aware grasping, visuotactile perception, and regrasp planning. Task-aware grasping computes affordances of grasps that are stable, observable, and favorable to placing. The visuotactile perception model relies on matching real observations against a set of simulated ones through supervised learning. Finally, we compute the desired robot motion by solving a shortest path problem on a graph of hand-to-hand regrasps. On a dual-arm robot equipped with visuotactile sensing, we demonstrate pick-and-place of 15 diverse objects with simPLE. The objects span a wide range of shapes and simPLE achieves successful placements into structured arrangements with 1mm clearance over 90% of the time for 6 objects, and over 80% of the time for 11 objects. Videos are available at http://mcube.mit.edu/research/simPLE.html .
RICo: Rotate-Inpaint-Complete for Generalizable Scene Reconstruction
Jul 21, 2023
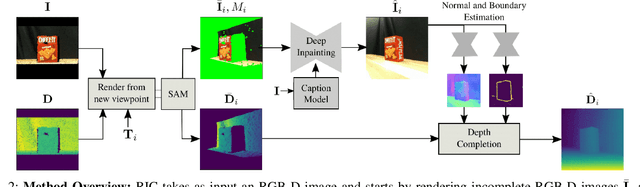
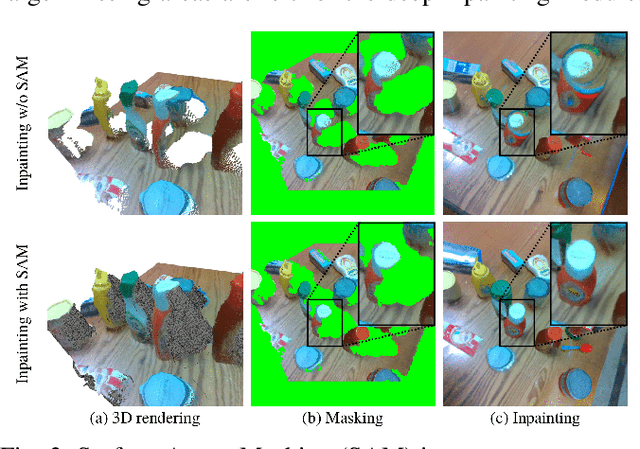
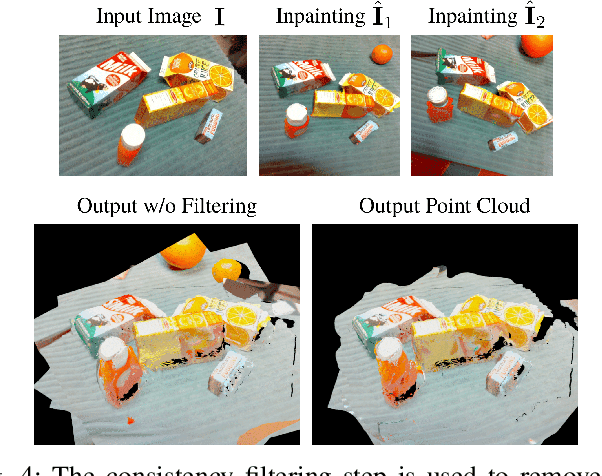
General scene reconstruction refers to the task of estimating the full 3D geometry and texture of a scene containing previously unseen objects. In many practical applications such as AR/VR, autonomous navigation, and robotics, only a single view of the scene may be available, making the scene reconstruction a very challenging task. In this paper, we present a method for scene reconstruction by structurally breaking the problem into two steps: rendering novel views via inpainting and 2D to 3D scene lifting. Specifically, we leverage the generalization capability of large language models to inpaint the missing areas of scene color images rendered from different views. Next, we lift these inpainted images to 3D by predicting normals of the inpainted image and solving for the missing depth values. By predicting for normals instead of depth directly, our method allows for robustness to changes in depth distributions and scale. With rigorous quantitative evaluation, we show that our method outperforms multiple baselines while providing generalization to novel objects and scenes.
Real-time Simultaneous Multi-Object 3D Shape Reconstruction, 6DoF Pose Estimation and Dense Grasp Prediction
May 16, 2023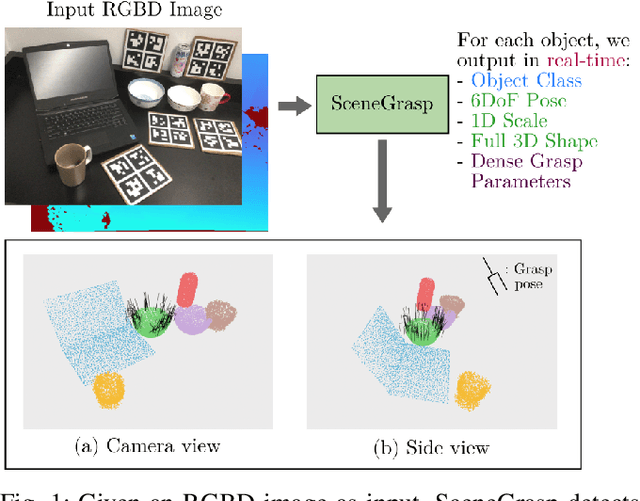
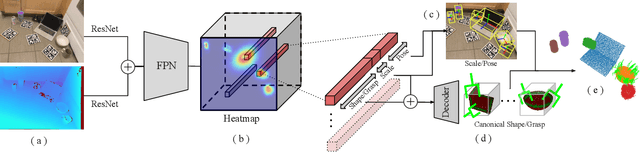
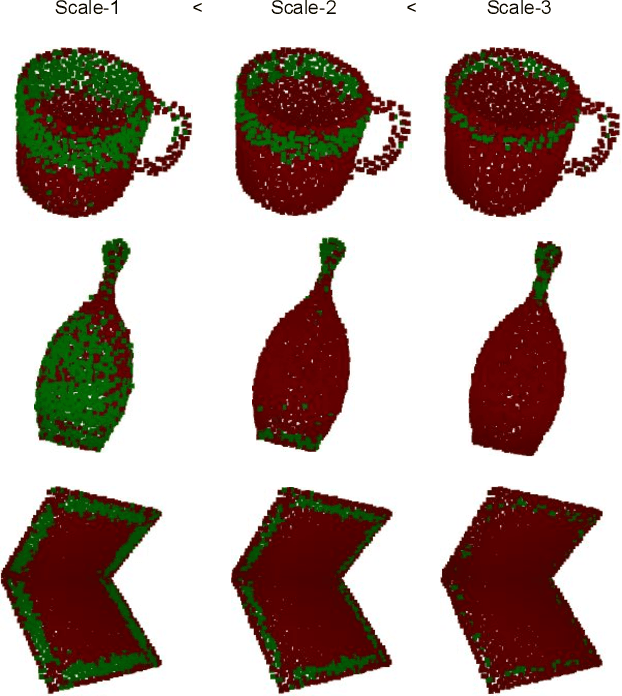
Robotic manipulation systems operating in complex environments rely on perception systems that provide information about the geometry (pose and 3D shape) of the objects in the scene along with other semantic information such as object labels. This information is then used for choosing the feasible grasps on relevant objects. In this paper, we present a novel method to provide this geometric and semantic information of all objects in the scene as well as feasible grasps on those objects simultaneously. The main advantage of our method is its speed as it avoids sequential perception and grasp planning steps. With detailed quantitative analysis, we show that our method delivers competitive performance compared to the state-of-the-art dedicated methods for object shape, pose, and grasp predictions while providing fast inference at 30 frames per second speed.
Pick2Place: Task-aware 6DoF Grasp Estimation via Object-Centric Perspective Affordance
Apr 08, 2023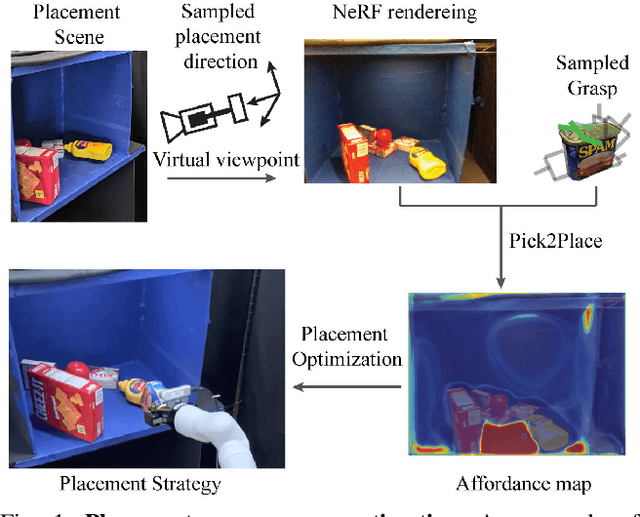
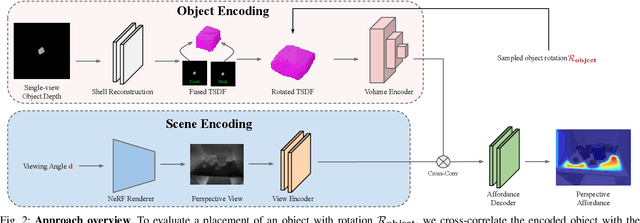

The choice of a grasp plays a critical role in the success of downstream manipulation tasks. Consider a task of placing an object in a cluttered scene; the majority of possible grasps may not be suitable for the desired placement. In this paper, we study the synergy between the picking and placing of an object in a cluttered scene to develop an algorithm for task-aware grasp estimation. We present an object-centric action space that encodes the relationship between the geometry of the placement scene and the object to be placed in order to provide placement affordance maps directly from perspective views of the placement scene. This action space enables the computation of a one-to-one mapping between the placement and picking actions allowing the robot to generate a diverse set of pick-and-place proposals and to optimize for a grasp under other task constraints such as robot kinematics and collision avoidance. With experiments both in simulation and on a real robot we demonstrate that with our method, the robot is able to successfully complete the task of placement-aware grasping with over 89% accuracy in such a way that generalizes to novel objects and scenes.
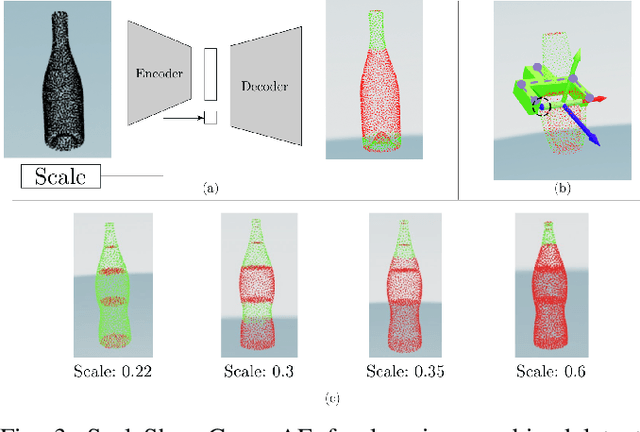
Object Shell Reconstruction: Camera-centric Object Representation for Robotic Grasping
Sep 14, 2021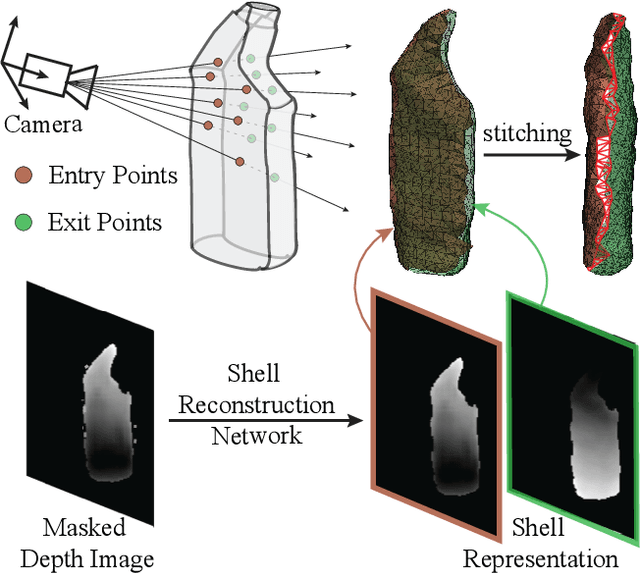
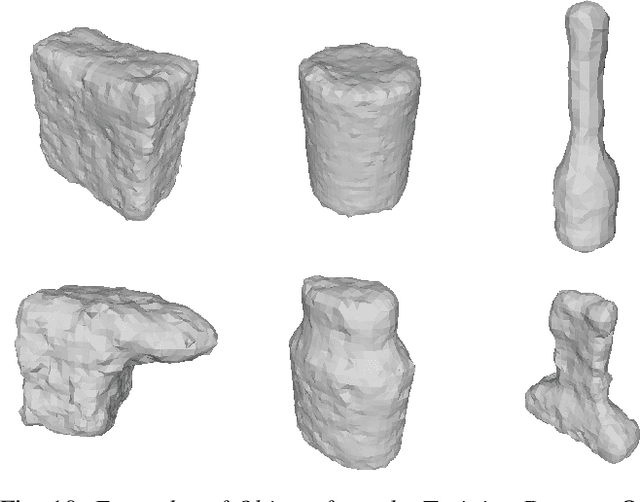

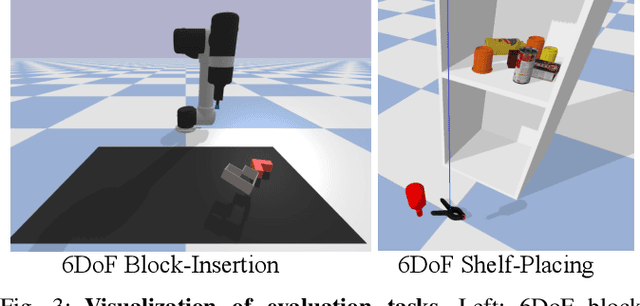
Robots can effectively grasp and manipulate objects using their 3D models. In this paper, we propose a simple shape representation and a reconstruction method that outperforms state-of-the-art methods in terms of geometric metrics and enables grasp generation with high precision and success. Our reconstruction method models the object geometry as a pair of depth images, composing the "shell" of the object. This representation allows using image-to-image residual ConvNet architectures for 3D reconstruction, generates object reconstruction directly in the camera frame, and generalizes well to novel object types. Moreover, an object shell can be converted into an object mesh in a fraction of a second, providing time and memory efficient alternative to voxel or implicit representations. We explore the application of shell representation for grasp planning. With rigorous experimental validation, both in simulation and on a real setup, we show that shell reconstruction encapsulates sufficient geometric information to generate precise grasps and the associated grasp quality with over 90% accuracy. Diverse grasps computed on shell reconstructions allow the robot to select and execute grasps in cluttered scenes with more than 93% success rate.
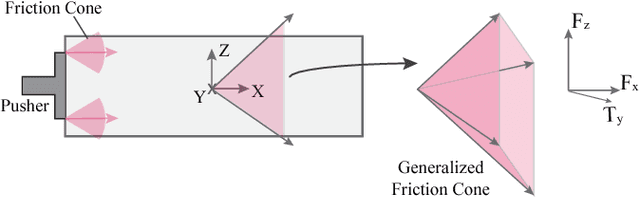
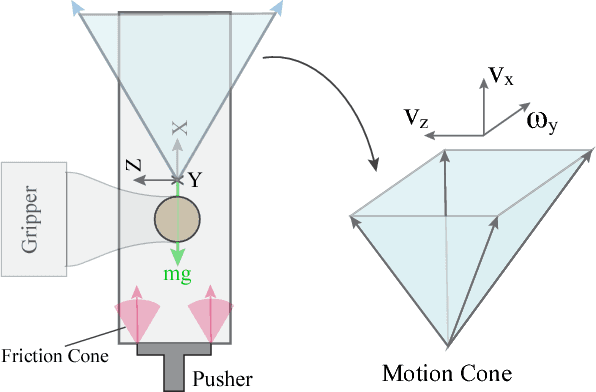
In-Hand Manipulation via Motion Cones
Feb 23, 2019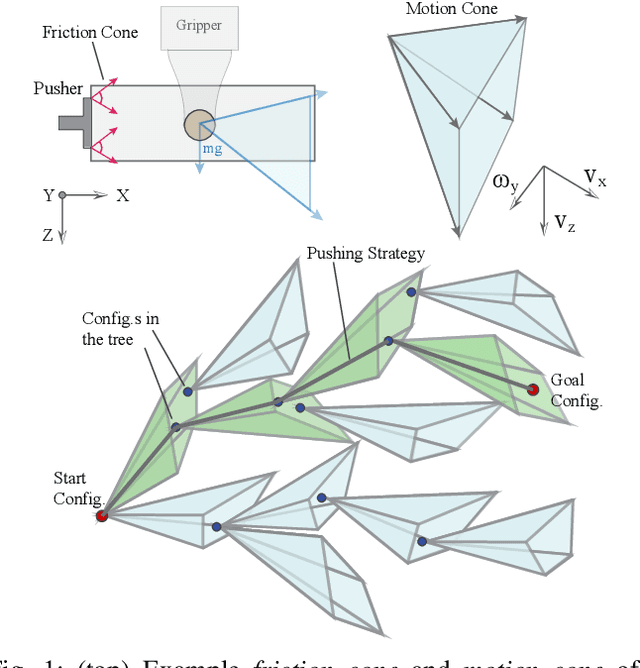

In this paper, we present the mechanics and algorithms to compute the set of feasible motions of an object pushed in a plane. This set is known as the motion cone and was previously described for non-prehensile manipulation tasks in the horizontal plane. We generalize its geometric construction to a broader set of planar tasks, where external forces such as gravity influence the dynamics of pushing, and prehensile tasks, where there are complex interactions between the gripper, object, and pusher. We show that the motion cone is defined by a set of low-curvature surfaces and provide a polyhedral cone approximation to it. We verify its validity with 2000 pushing experiments recorded with motion tracking system. Motion cones abstract the algebra involved in simulating frictional pushing by providing bounds on the set of feasible motions and by characterizing which pushes will stick or slip. We demonstrate their use for the dynamic propagation step in a sampling-based planning algorithm for in-hand manipulation. The planner generates trajectories that involve sequences of continuous pushes with 5-1000x speed improvements to equivalent algorithms. Video Summary -- https://youtu.be/tVDO8QMuYhc
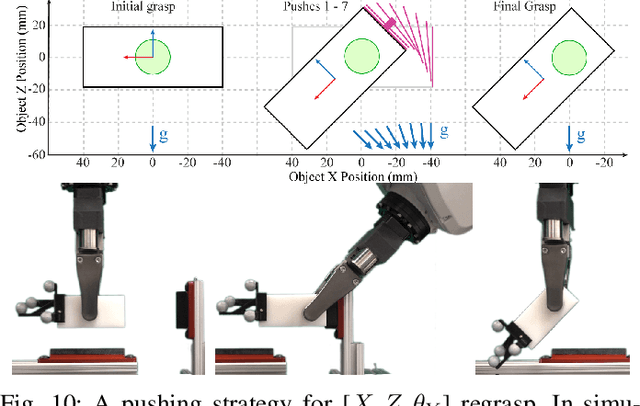
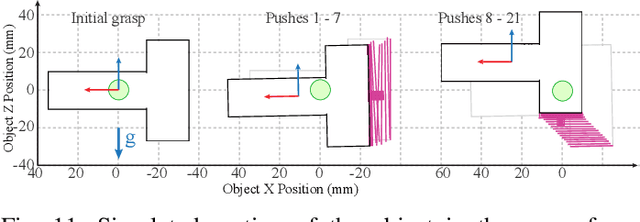
Regrasping by Fixtureless Fixturing
Sep 25, 2018
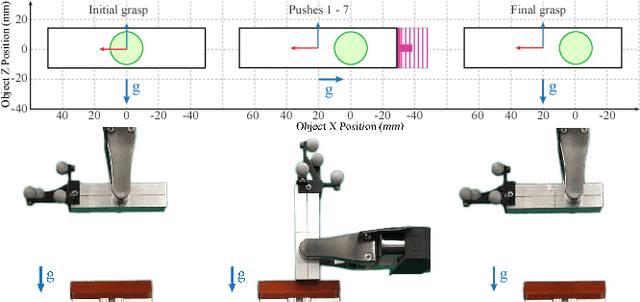
This paper presents a fixturing strategy for regrasping that does not require a physical fixture. To regrasp an object in a gripper, a robot pushes the object against external contact/s in the environment such that the external contact keeps the object stationary while the fingers slide over the object. We call this manipulation technique fixtureless fixturing. Exploiting the mechanics of pushing, we characterize a convex polyhedral set of pushes that results in fixtureless fixturing. These pushes are robust against uncertainty in the object inertia, grasping force, and the friction at the contacts. We propose a sampling-based planner that uses the sets of robust pushes to rapidly build a tree of reachable grasps. A path in this tree is a pushing strategy, possibly involving pushes from different sides, to regrasp the object. We demonstrate the experimental validity and robustness of the proposed manipulation technique with different regrasp examples on a manipulation platform. Such a fast and flexible regrasp planner facilitates versatile and flexible automation solutions.