 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Shell Reconstruction: Camera-centric Object Representation for Robotic Grasping
Sep 14, 2021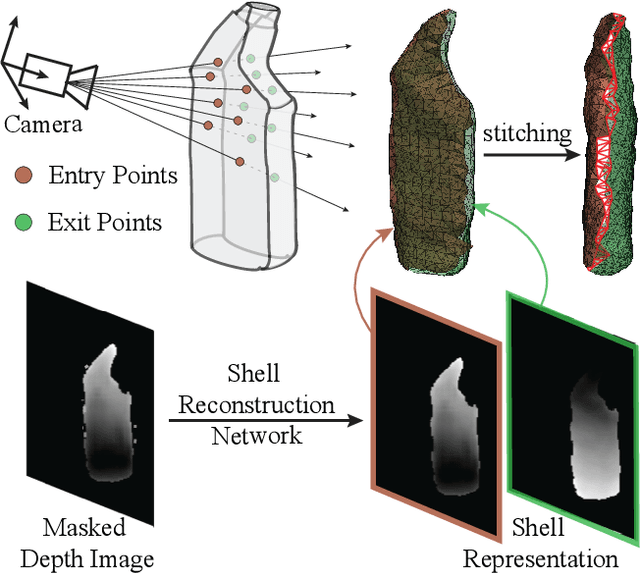

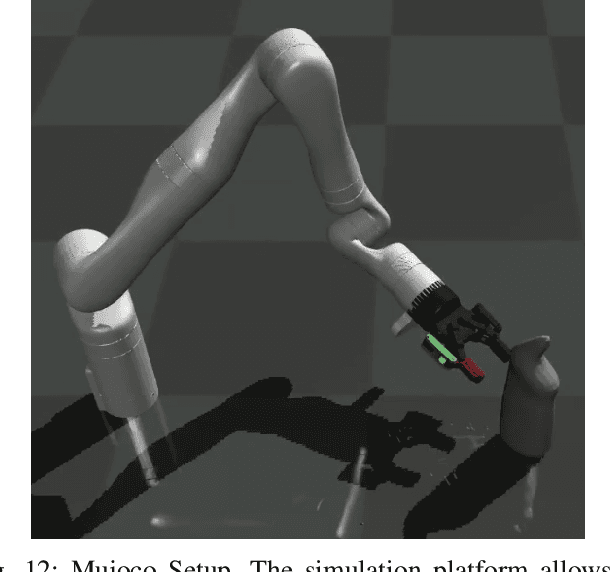
Robots can effectively grasp and manipulate objects using their 3D models. In this paper, we propose a simple shape representation and a reconstruction method that outperforms state-of-the-art methods in terms of geometric metrics and enables grasp generation with high precision and success. Our reconstruction method models the object geometry as a pair of depth images, composing the "shell" of the object. This representation allows using image-to-image residual ConvNet architectures for 3D reconstruction, generates object reconstruction directly in the camera frame, and generalizes well to novel object types. Moreover, an object shell can be converted into an object mesh in a fraction of a second, providing time and memory efficient alternative to voxel or implicit representations. We explore the application of shell representation for grasp planning. With rigorous experimental validation, both in simulation and on a real setup, we show that shell reconstruction encapsulates sufficient geometric information to generate precise grasps and the associated grasp quality with over 90% accuracy. Diverse grasps computed on shell reconstructions allow the robot to select and execute grasps in cluttered scenes with more than 93% success rate.
Siamese Encoding and Alignment by Multiscale Learning with Self-Supervision
Apr 04, 2019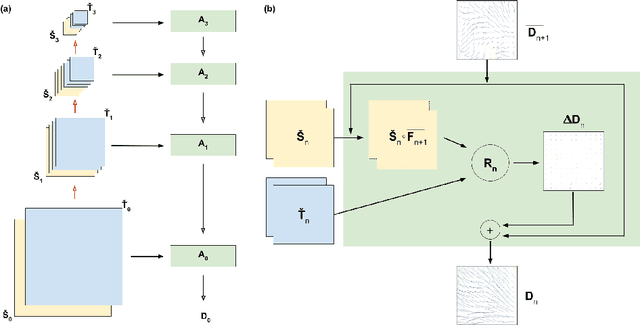
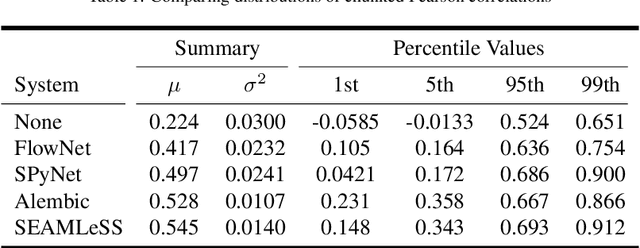
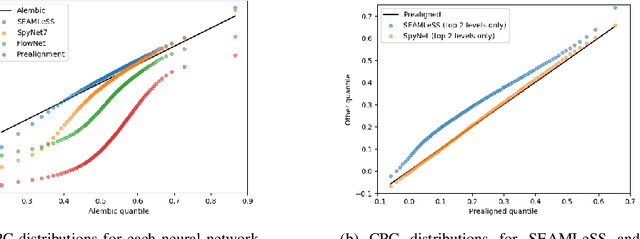

We propose a method of aligning a source image to a target image, where the transform is specified by a dense vector field. The two images are encoded as feature hierarchies by siamese convolutional nets. Then a hierarchy of aligner modules computes the transform in a coarse-to-fine recursion. Each module receives as input the transform that was computed by the module at the level above, aligns the source and target encodings at the same level of the hierarchy, and then computes an improved approximation to the transform using a convolutional net. The entire architecture of encoder and aligner nets is trained in a self-supervised manner to minimize the squared error between source and target remaining after alignment. We show that siamese encoding enables more accurate alignment than the image pyramids of SPyNet, a previous deep learning approach to coarse-to-fine alignment. Furthermore, self-supervision applies even without target values for the transform, unlike the strongly supervised SPyNet. We also show that our approach outperforms one-shot approaches to alignment, because the fine pathways in the latter approach may fail to contribute to alignment accuracy when displacements are large. As shown by previous one-shot approaches, good results from self-supervised learning require that the loss function additionally penalize non-smooth transforms. We demonstrate that "masking out" the penalty function near discontinuities leads to correct recovery of non-smooth transforms. Our claims are supported by empirical comparisons using images from serial section electron microscopy of brain tissue.
PZnet: Efficient 3D ConvNet Inference on Manycore CPUs
Mar 18, 2019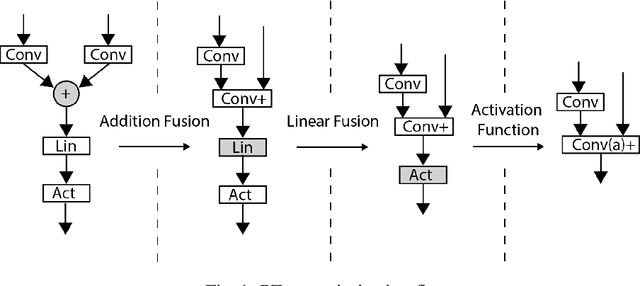
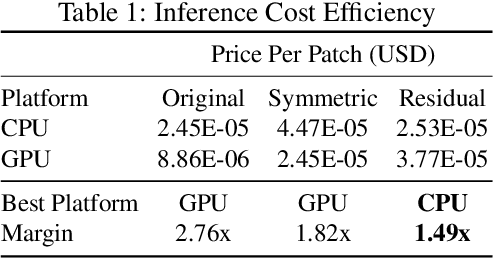

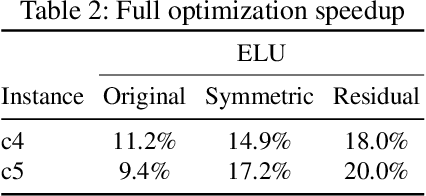
Convolutional nets have been shown to achieve state-of-the-art accuracy in many biomedical image analysis tasks. Many tasks within biomedical analysis domain involve analyzing volumetric (3D) data acquired by CT, MRI and Microscopy acquisition methods. To deploy convolutional nets in practical working systems, it is important to solve the efficient inference problem. Namely, one should be able to apply an already-trained convolutional network to many large images using limited computational resources. In this paper we present PZnet, a CPU-only engine that can be used to perform inference for a variety of 3D convolutional net architectures. PZNet outperforms MKL-based CPU implementations of PyTorch and Tensorflow by more than 3.5x for the popular U-net architecture. Moreover, for 3D convolutions with low featuremap numbers, cloud CPU inference with PZnet outperfroms cloud GPU inference in terms of cost efficiency.