 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Neural Representation Alignment from Limited Inputs and Features
Feb 20, 2025In both artificial and biological systems, the centered kernel alignment (CKA) has become a widely used tool for quantifying neural representation similarity. While current CKA estimators typically correct for the effects of finite stimuli sampling, the effects of sampling a subset of neurons are overlooked, introducing notable bias in standard experimental scenarios. Here, we provide a theoretical analysis showing how this bias is affected by the representation geometry. We then introduce a novel estimator that corrects for both input and feature sampling. We use our method for evaluating both brain-to-brain and model-to-brain alignments and show that it delivers reliable comparisons even with very sparsely sampled neurons. We perform within-animal and across-animal comparisons on electrophysiological data from visual cortical areas V1, V4, and IT data, and use these as benchmarks to evaluate model-to-brain alignment. We also apply our method to reveal how object representations become progressively disentangled across layers in both biological and artificial systems. These findings underscore the importance of correcting feature-sampling biases in CKA and demonstrate that our bias-corrected estimator provides a more faithful measure of representation alignment. The improved estimates increase our understanding of how neural activity is structured across both biological and artificial systems.
Estimating the Spectral Moments of the Kernel Integral Operator from Finite Sample Matrices
Oct 24, 2024Analyzing the structure of sampled features from an input data distribution is challenging when constrained by limited measurements in both the number of inputs and features. Traditional approaches often rely on the eigenvalue spectrum of the sample covariance matrix derived from finite measurement matrices; however, these spectra are sensitive to the size of the measurement matrix, leading to biased insights. In this paper, we introduce a novel algorithm that provides unbiased estimates of the spectral moments of the kernel integral operator in the limit of infinite inputs and features from finitely sampled measurement matrices. Our method, based on dynamic programming, is efficient and capable of estimating the moments of the operator spectrum. We demonstrate the accuracy of our estimator on radial basis function (RBF) kernels, highlighting its consistency with the theoretical spectra. Furthermore, we showcase the practical utility and robustness of our method in understanding the geometry of learned representations in neural networks.
Parametric Matrix Models
Jan 23, 2024



We present a general class of machine learning algorithms called parametric matrix models. Parametric matrix models are based on matrix equations, and the design is motivated by the efficiency of reduced basis methods for approximating solutions of parametric equations. The dependent variables can be defined implicitly or explicitly, and the equations may use algebraic, differential, or integral relations. Parametric matrix models can be trained with empirical data only, and no high-fidelity model calculations are needed. While originally designed for scientific computing, parametric matrix models are universal function approximators that can be applied to general machine learning problems. After introducing the underlying theory, we apply parametric matrix models to a series of different challenges that show their performance for a wide range of problems. For all the challenges tested here, parametric matrix models produce accurate results within a computational framework that allows for parameter extrapolation and interpretability.
TimewarpVAE: Simultaneous Time-Warping and Representation Learning of Trajectories
Oct 24, 2023



Human demonstrations of trajectories are an important source of training data for many machine learning problems. However, the difficulty of collecting human demonstration data for complex tasks makes learning efficient representations of those trajectories challenging. For many problems, such as for handwriting or for quasistatic dexterous manipulation, the exact timings of the trajectories should be factored from their spatial path characteristics. In this work, we propose TimewarpVAE, a fully differentiable manifold-learning algorithm that incorporates Dynamic Time Warping (DTW) to simultaneously learn both timing variations and latent factors of spatial variation. We show how the TimewarpVAE algorithm learns appropriate time alignments and meaningful representations of spatial variations in small handwriting and fork manipulation datasets. Our results have lower spatial reconstruction test error than baseline approaches and the learned low-dimensional representations can be used to efficiently generate semantically meaningful novel trajectories.
Sparsity-depth Tradeoff in Infinitely Wide Deep Neural Networks
May 17, 2023


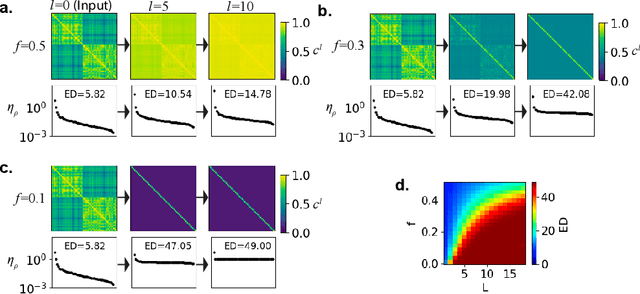
We investigate how sparse neural activity affects the generalization performance of a deep Bayesian neural network at the large width limit. To this end, we derive a neural network Gaussian Process (NNGP) kernel with rectified linear unit (ReLU) activation and a predetermined fraction of active neurons. Using the NNGP kernel, we observe that the sparser networks outperform the non-sparse networks at shallow depths on a variety of datasets. We validate this observation by extending the existing theory on the generalization error of kernel-ridge regression.
EV-Catcher: High-Speed Object Catching Using Low-latency Event-based Neural Networks
Apr 14, 2023



Event-based sensors have recently drawn increasing interest in robotic perception due to their lower latency, higher dynamic range, and lower bandwidth requirements compared to standard CMOS-based imagers. These properties make them ideal tools for real-time perception tasks in highly dynamic environments. In this work, we demonstrate an application where event cameras excel: accurately estimating the impact location of fast-moving objects. We introduce a lightweight event representation called Binary Event History Image (BEHI) to encode event data at low latency, as well as a learning-based approach that allows real-time inference of a confidence-enabled control signal to the robot. To validate our approach, we present an experimental catching system in which we catch fast-flying ping-pong balls. We show that the system is capable of achieving a success rate of 81% in catching balls targeted at different locations, with a velocity of up to 13 m/s even on compute-constrained embedded platforms such as the Nvidia Jetson NX.
Policy-Value Alignment and Robustness in Search-based Multi-Agent Learning
Feb 06, 2023Large-scale AI systems that combine search and learning have reached super-human levels of performance in game-playing, but have also been shown to fail in surprising ways. The brittleness of such models limits their efficacy and trustworthiness in real-world deployments. In this work, we systematically study one such algorithm, AlphaZero, and identify two phenomena related to the nature of exploration. First, we find evidence of policy-value misalignment -- for many states, AlphaZero's policy and value predictions contradict each other, revealing a tension between accurate move-selection and value estimation in AlphaZero's objective. Further, we find inconsistency within AlphaZero's value function, which causes it to generalize poorly, despite its policy playing an optimal strategy. From these insights we derive VISA-VIS: a novel method that improves policy-value alignment and value robustness in AlphaZero. Experimentally, we show that our method reduces policy-value misalignment by up to 76%, reduces value generalization error by up to 50%, and reduces average value error by up to 55%.
Object Shell Reconstruction: Camera-centric Object Representation for Robotic Grasping
Sep 14, 2021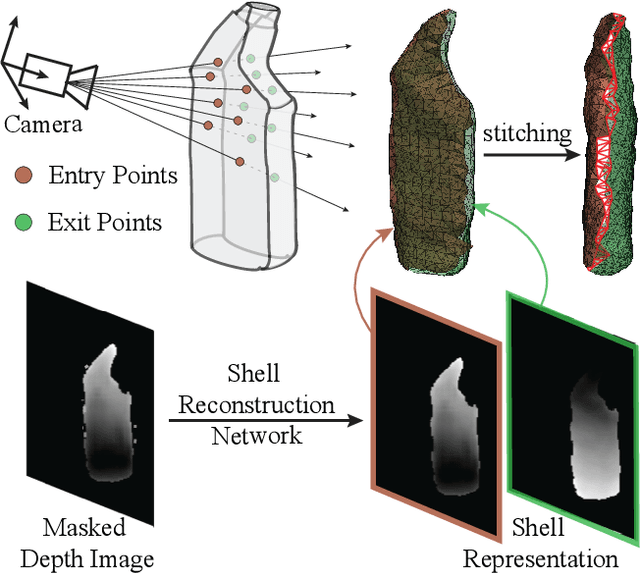

Robots can effectively grasp and manipulate objects using their 3D models. In this paper, we propose a simple shape representation and a reconstruction method that outperforms state-of-the-art methods in terms of geometric metrics and enables grasp generation with high precision and success. Our reconstruction method models the object geometry as a pair of depth images, composing the "shell" of the object. This representation allows using image-to-image residual ConvNet architectures for 3D reconstruction, generates object reconstruction directly in the camera frame, and generalizes well to novel object types. Moreover, an object shell can be converted into an object mesh in a fraction of a second, providing time and memory efficient alternative to voxel or implicit representations. We explore the application of shell representation for grasp planning. With rigorous experimental validation, both in simulation and on a real setup, we show that shell reconstruction encapsulates sufficient geometric information to generate precise grasps and the associated grasp quality with over 90% accuracy. Diverse grasps computed on shell reconstructions allow the robot to select and execute grasps in cluttered scenes with more than 93% success rate.
Curriculum-Driven Multi-Agent Learning and the Role of Implicit Communication in Teamwork
Jun 21, 2021

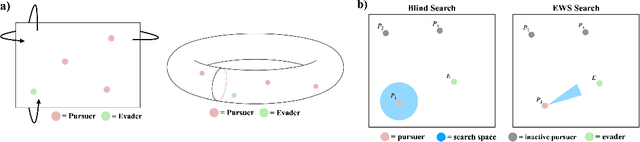
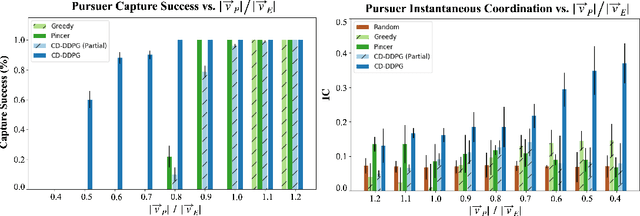
We propose a curriculum-driven learning strategy for solving difficult multi-agent coordination tasks. Our method is inspired by a study of animal communication, which shows that two straightforward design features (mutual reward and decentralization) support a vast spectrum of communication protocols in nature. We highlight the importance of similarly interpreting emergent communication as a spectrum. We introduce a toroidal, continuous-space pursuit-evasion environment and show that naive decentralized learning does not perform well. We then propose a novel curriculum-driven strategy for multi-agent learning. Experiments with pursuit-evasion show that our approach enables decentralized pursuers to learn to coordinate and capture a superior evader, significantly outperforming sophisticated analytical policies. We argue through additional quantitative analysis -- including influence-based measures such as Instantaneous Coordination -- that emergent implicit communication plays a large role in enabling superior levels of coordination.
Fairness for Cooperative Multi-Agent Learning with Equivariant Policies
Jun 10, 2021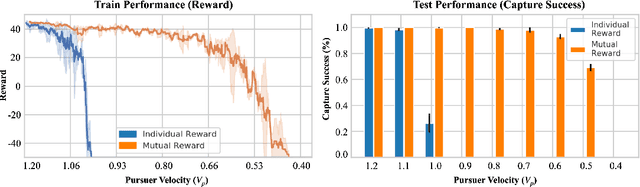
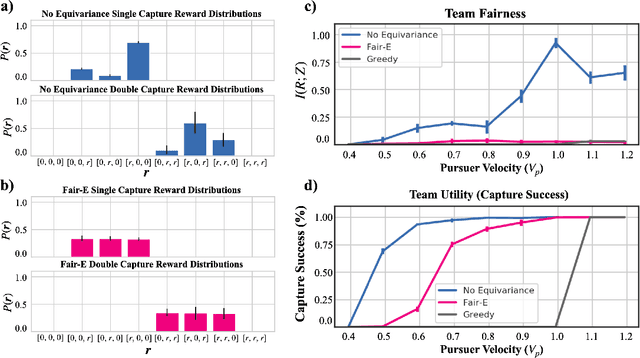
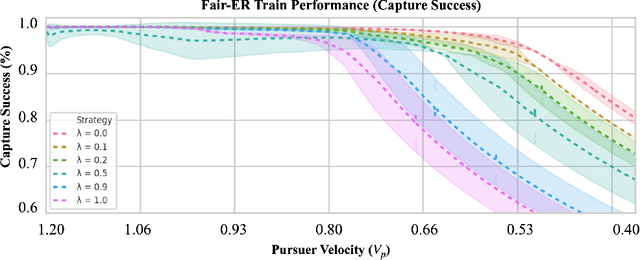
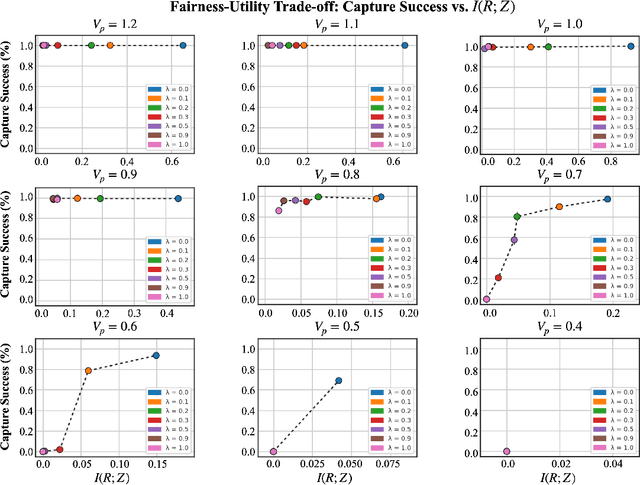
We study fairness through the lens of cooperative multi-agent learning. Our work is motivated by empirical evidence that naive maximization of team reward yields unfair outcomes for individual team members. To address fairness in multi-agent contexts, we introduce team fairness, a group-based fairness measure for multi-agent learning. We then incorporate team fairness into policy optimization -- introducing Fairness through Equivariance (Fair-E), a novel learning strategy that achieves provably fair reward distributions. We then introduce Fairness through Equivariance Regularization (Fair-ER) as a soft-constraint version of Fair-E and show that Fair-ER reaches higher levels of utility than Fair-E and fairer outcomes than policies with no equivariance. Finally, we investigate the fairness-utility trade-off in multi-agent settings.