Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity-depth Tradeoff in Infinitely Wide Deep Neural Networks
Paper and Code
May 17, 2023


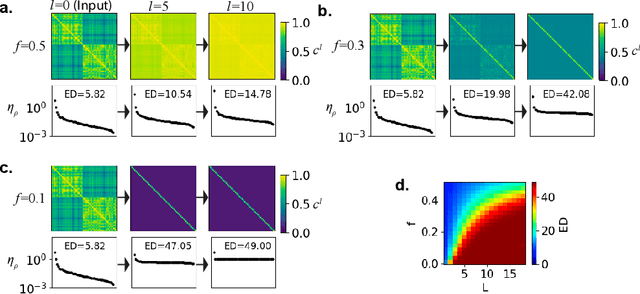
We investigate how sparse neural activity affects the generalization performance of a deep Bayesian neural network at the large width limit. To this end, we derive a neural network Gaussian Process (NNGP) kernel with rectified linear unit (ReLU) activation and a predetermined fraction of active neurons. Using the NNGP kernel, we observe that the sparser networks outperform the non-sparse networks at shallow depths on a variety of datasets. We validate this observation by extending the existing theory on the generalization error of kernel-ridge regression.
View paper on