 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaEvolve: Adaptive LLM Driven Zeroth-Order Optimization
Feb 23, 2026The paradigm of automated program generation is shifting from one-shot generation to inference-time search, where Large Language Models (LLMs) function as semantic mutation operators within evolutionary loops. While effective, these systems are currently governed by static schedules that fail to account for the non-stationary dynamics of the search process. This rigidity results in substantial computational waste, as resources are indiscriminately allocated to stagnating populations while promising frontiers remain under-exploited. We introduce AdaEvolve, a framework that reformulates LLM-driven evolution as a hierarchical adaptive optimization problem. AdaEvolve uses an "accumulated improvement signal" to unify decisions across three levels: Local Adaptation, which dynamically modulates the exploration intensity within a population of solution candidates; Global Adaptation, which routes the global resource budget via bandit-based scheduling across different solution candidate populations; and Meta-Guidance which generates novel solution tactics based on the previously generated solutions and their corresponding improvements when the progress stalls. We demonstrate that AdaEvolve consistently outperforms the open-sourced baselines across 185 different open-ended optimization problems including combinatorial, systems optimization and algorithm design problems.
Challenging Gradient Boosted Decision Trees with Tabular Transformers for Fraud Detection at Booking.com
May 22, 2024Transformer-based neural networks, empowered by Self-Supervised Learning (SSL), have demonstrated unprecedented performance across various domains. However, related literature suggests that tabular Transformers may struggle to outperform classical Machine Learning algorithms, such as Gradient Boosted Decision Trees (GBDT). In this paper, we aim to challenge GBDTs with tabular Transformers on a typical task faced in e-commerce, namely fraud detection. Our study is additionally motivated by the problem of selection bias, often occurring in real-life fraud detection systems. It is caused by the production system affecting which subset of traffic becomes labeled. This issue is typically addressed by sampling randomly a small part of the whole production data, referred to as a Control Group. This subset follows a target distribution of production data and therefore is usually preferred for training classification models with standard ML algorithms. Our methodology leverages the capabilities of Transformers to learn transferable representations using all available data by means of SSL, giving it an advantage over classical methods. Furthermore, we conduct large-scale experiments, pre-training tabular Transformers on vast amounts of data instances and fine-tuning them on smaller target datasets. The proposed approach outperforms heavily tuned GBDTs by a considerable margin of the Average Precision (AP) score. Pre-trained models show more consistent performance than the ones trained from scratch when fine-tuning data is limited. Moreover, they require noticeably less labeled data for reaching performance comparable to their GBDT competitor that utilizes the whole dataset.
Deep Learning Based Named Entity Recognition Models for Recipes
Feb 27, 2024
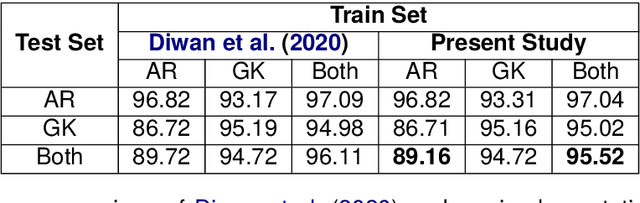


Food touches our lives through various endeavors, including flavor, nourishment, health, and sustainability. Recipes are cultural capsules transmitted across generations via unstructured text. Automated protocols for recognizing named entities, the building blocks of recipe text, are of immense value for various applications ranging from information extraction to novel recipe generation. Named entity recognition is a technique for extracting information from unstructured or semi-structured data with known labels. Starting with manually-annotated data of 6,611 ingredient phrases, we created an augmented dataset of 26,445 phrases cumulatively. Simultaneously, we systematically cleaned and analyzed ingredient phrases from RecipeDB, the gold-standard recipe data repository, and annotated them using the Stanford NER. Based on the analysis, we sampled a subset of 88,526 phrases using a clustering-based approach while preserving the diversity to create the machine-annotated dataset. A thorough investigation of NER approaches on these three datasets involving statistical, fine-tuning of deep learning-based language models and few-shot prompting on large language models (LLMs) provides deep insights. We conclude that few-shot prompting on LLMs has abysmal performance, whereas the fine-tuned spaCy-transformer emerges as the best model with macro-F1 scores of 95.9%, 96.04%, and 95.71% for the manually-annotated, augmented, and machine-annotated datasets, respectively.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
ONNXExplainer: an ONNX Based Generic Framework to Explain Neural Networks Using Shapley Values
Oct 03, 2023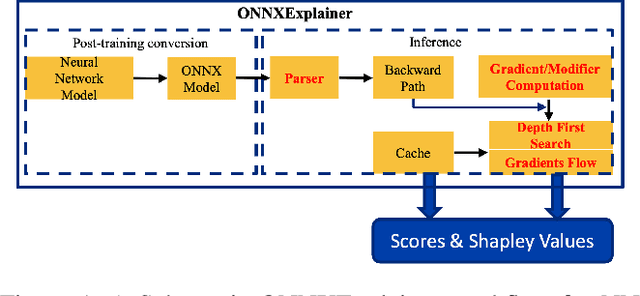
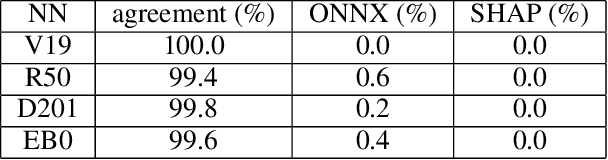

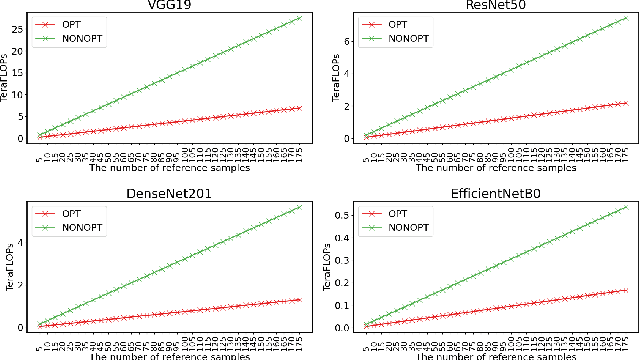
Understanding why a neural network model makes certain decisions can be as important as the inference performance. Various methods have been proposed to help practitioners explain the prediction of a neural network model, of which Shapley values are most popular. SHAP package is a leading implementation of Shapley values to explain neural networks implemented in TensorFlow or PyTorch but lacks cross-platform support, one-shot deployment and is highly inefficient. To address these problems, we present the ONNXExplainer, which is a generic framework to explain neural networks using Shapley values in the ONNX ecosystem. In ONNXExplainer, we develop its own automatic differentiation and optimization approach, which not only enables One-Shot Deployment of neural networks inference and explanations, but also significantly improves the efficiency to compute explanation with less memory consumption. For fair comparison purposes, we also implement the same optimization in TensorFlow and PyTorch and measure its performance against the current state of the art open-source counterpart, SHAP. Extensive benchmarks demonstrate that the proposed optimization approach improves the explanation latency of VGG19, ResNet50, DenseNet201, and EfficientNetB0 by as much as 500%.
RICo: Rotate-Inpaint-Complete for Generalizable Scene Reconstruction
Jul 21, 2023
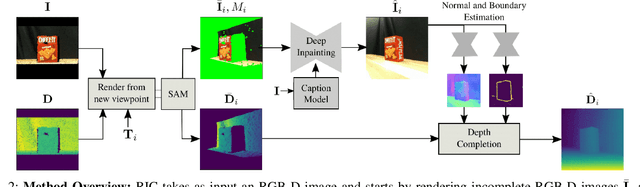
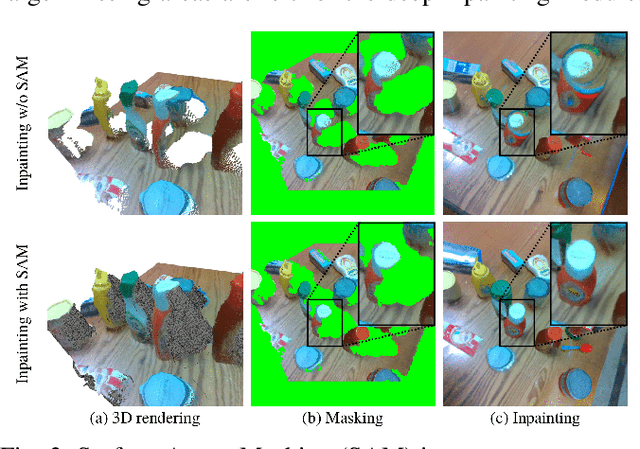
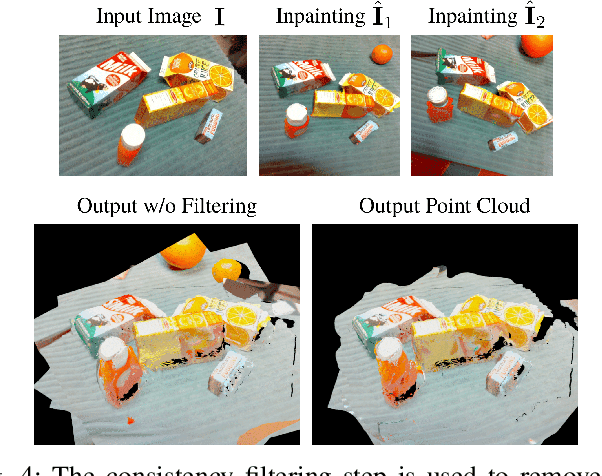
General scene reconstruction refers to the task of estimating the full 3D geometry and texture of a scene containing previously unseen objects. In many practical applications such as AR/VR, autonomous navigation, and robotics, only a single view of the scene may be available, making the scene reconstruction a very challenging task. In this paper, we present a method for scene reconstruction by structurally breaking the problem into two steps: rendering novel views via inpainting and 2D to 3D scene lifting. Specifically, we leverage the generalization capability of large language models to inpaint the missing areas of scene color images rendered from different views. Next, we lift these inpainted images to 3D by predicting normals of the inpainted image and solving for the missing depth values. By predicting for normals instead of depth directly, our method allows for robustness to changes in depth distributions and scale. With rigorous quantitative evaluation, we show that our method outperforms multiple baselines while providing generalization to novel objects and scenes.
Real-time Simultaneous Multi-Object 3D Shape Reconstruction, 6DoF Pose Estimation and Dense Grasp Prediction
May 16, 2023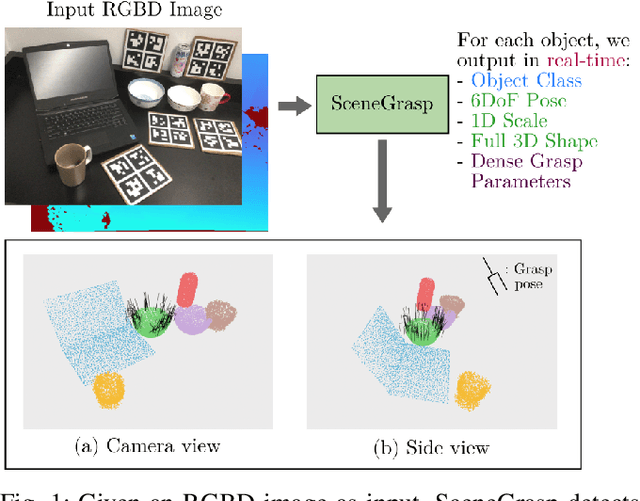
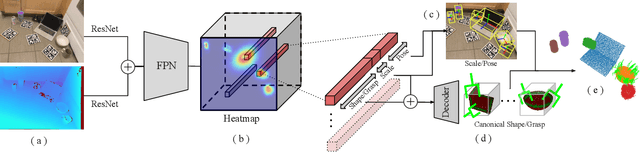
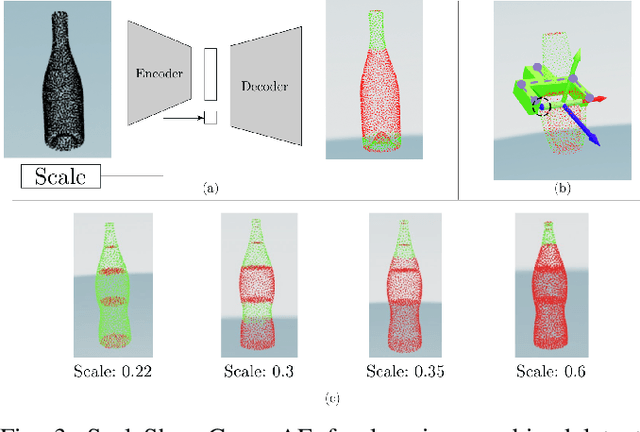
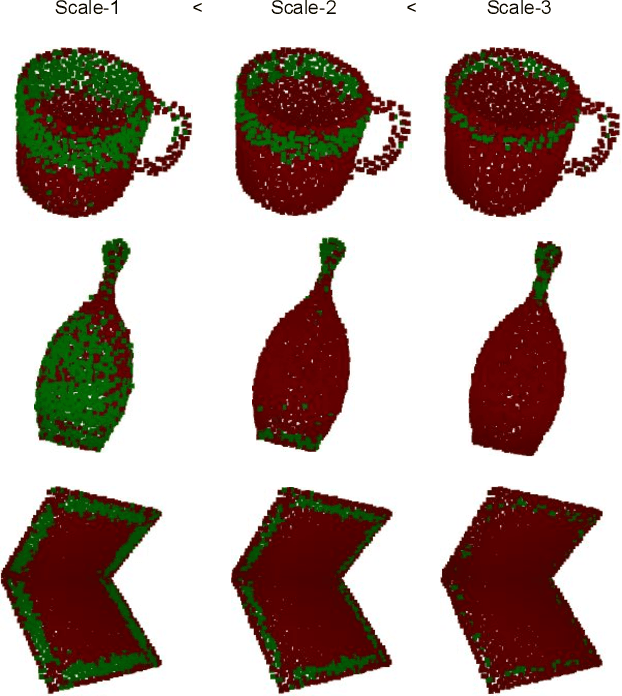
Robotic manipulation systems operating in complex environments rely on perception systems that provide information about the geometry (pose and 3D shape) of the objects in the scene along with other semantic information such as object labels. This information is then used for choosing the feasible grasps on relevant objects. In this paper, we present a novel method to provide this geometric and semantic information of all objects in the scene as well as feasible grasps on those objects simultaneously. The main advantage of our method is its speed as it avoids sequential perception and grasp planning steps. With detailed quantitative analysis, we show that our method delivers competitive performance compared to the state-of-the-art dedicated methods for object shape, pose, and grasp predictions while providing fast inference at 30 frames per second speed.
Joint Liver and Hepatic Lesion Segmentation using a Hybrid CNN with Transformer Layers
Jan 26, 2022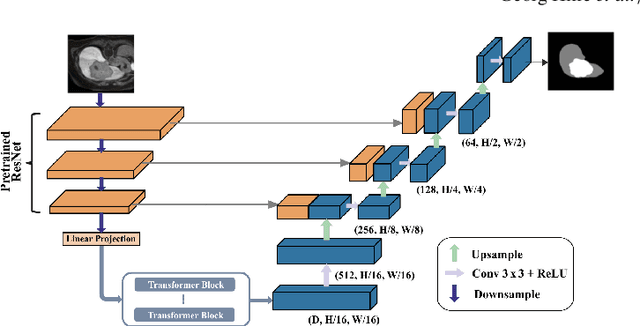
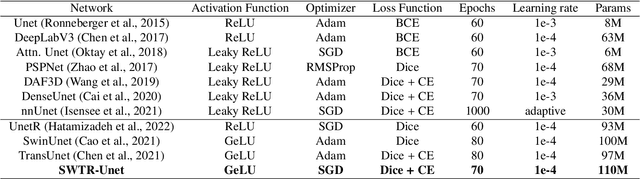
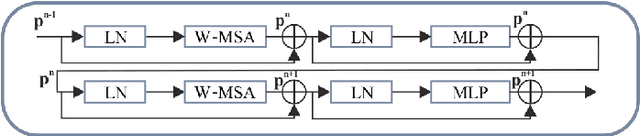
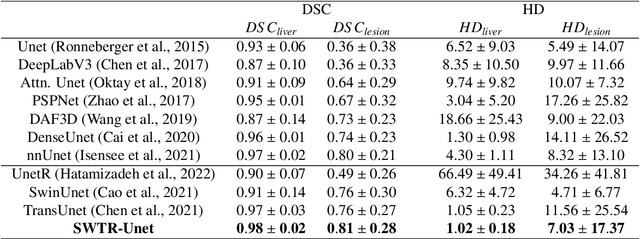
Deep learning-based segmentation of the liver and hepatic lesions therein steadily gains relevance in clinical practice due to the increasing incidence of liver cancer each year. Whereas various network variants with overall promising results in the field of medical image segmentation have been developed over the last years, almost all of them struggle with the challenge of accurately segmenting hepatic lesions. This lead to the idea of combining elements of convolutional and transformerbased architectures to overcome the existing limitations. This work presents a hybrid network called SWTR-Unet, consisting of a pretrained ResNet, transformer blocks as well as a common Unet-style decoder path. This network was applied to clinical liver MRI, as well as to the publicly available CT data of the liver tumor segmentation (LiTS) challenge. Additionally, multiple state-of-the-art networks were implemented and applied to both datasets, ensuring a direct comparability. Furthermore, correlation analysis and an ablation study were carried out, to investigate various influencing factors on the segmentation accuracy of our presented method. With Dice similarity scores of averaged 98 +- 2 % for liver and 81 +- 28 % lesion segmentation on the MRI dataset and 97 +- 2 % and 79 +- 25 %, respectively on the CT dataset, the proposed SWTR-Unet outperforms each of the additionally implemented state-of-the-art networks. The achieved segmentation accuracy was found to be on par with manually performed expert segmentations as indicated by interobserver variabilities for liver lesion segmentation. In conclusion, the presented method could save valuable time and resources in clinical practice.
Scene Editing as Teleoperation: A Case Study in 6DoF Kit Assembly
Oct 09, 2021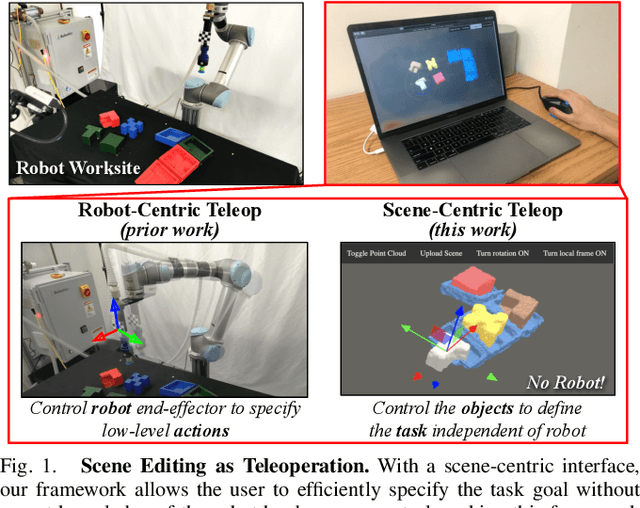



Studies in robot teleoperation have been centered around action specifications -- from continuous joint control to discrete end-effector pose control. However, these robot-centric interfaces often require skilled operators with extensive robotics expertise. To make teleoperation accessible to non-expert users, we propose the framework "Scene Editing as Teleoperation" (SEaT), where the key idea is to transform the traditional "robot-centric" interface into a "scene-centric" interface -- instead of controlling the robot, users focus on specifying the task's goal by manipulating digital twins of the real-world objects. As a result, a user can perform teleoperation without any expert knowledge of the robot hardware. To achieve this goal, we utilize a category-agnostic scene-completion algorithm that translates the real-world workspace (with unknown objects) into a manipulable virtual scene representation and an action-snapping algorithm that refines the user input before generating the robot's action plan. To train the algorithms, we procedurally generated a large-scale, diverse kit-assembly dataset that contains object-kit pairs that mimic real-world object-kitting tasks. Our experiments in simulation and on a real-world system demonstrate that our framework improves both the efficiency and success rate for 6DoF kit-assembly tasks. A user study demonstrates that SEaT framework participants achieve a higher task success rate and report a lower subjective workload compared to an alternative robot-centric interface. Video can be found at https://www.youtube.com/watch?v=-NdR3mkPbQQ .
Object Shell Reconstruction: Camera-centric Object Representation for Robotic Grasping
Sep 14, 2021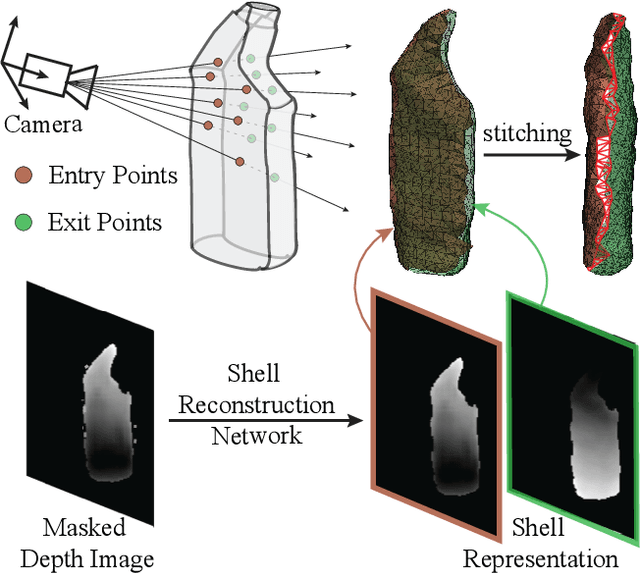

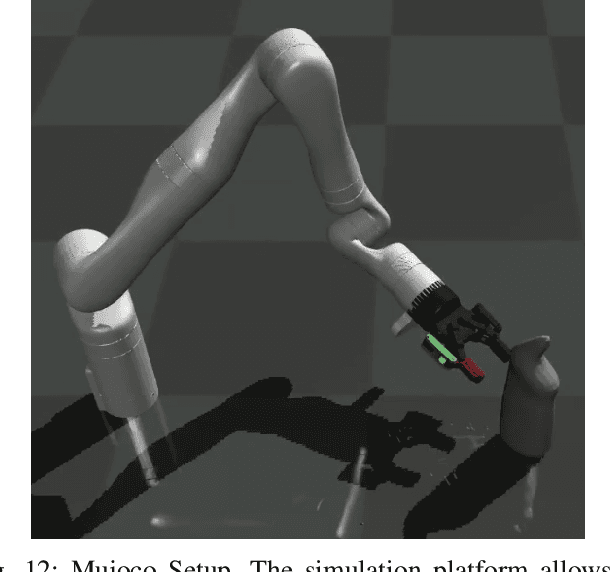
Robots can effectively grasp and manipulate objects using their 3D models. In this paper, we propose a simple shape representation and a reconstruction method that outperforms state-of-the-art methods in terms of geometric metrics and enables grasp generation with high precision and success. Our reconstruction method models the object geometry as a pair of depth images, composing the "shell" of the object. This representation allows using image-to-image residual ConvNet architectures for 3D reconstruction, generates object reconstruction directly in the camera frame, and generalizes well to novel object types. Moreover, an object shell can be converted into an object mesh in a fraction of a second, providing time and memory efficient alternative to voxel or implicit representations. We explore the application of shell representation for grasp planning. With rigorous experimental validation, both in simulation and on a real setup, we show that shell reconstruction encapsulates sufficient geometric information to generate precise grasps and the associated grasp quality with over 90% accuracy. Diverse grasps computed on shell reconstructions allow the robot to select and execute grasps in cluttered scenes with more than 93% success rate.