 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Frame Aggregation-based Transformer for Live Video Comment Generation
Oct 30, 2025Live commenting on video streams has surged in popularity on platforms like Twitch, enhancing viewer engagement through dynamic interactions. However, automatically generating contextually appropriate comments remains a challenging and exciting task. Video streams can contain a vast amount of data and extraneous content. Existing approaches tend to overlook an important aspect of prioritizing video frames that are most relevant to ongoing viewer interactions. This prioritization is crucial for producing contextually appropriate comments. To address this gap, we introduce a novel Semantic Frame Aggregation-based Transformer (SFAT) model for live video comment generation. This method not only leverages CLIP's visual-text multimodal knowledge to generate comments but also assigns weights to video frames based on their semantic relevance to ongoing viewer conversation. It employs an efficient weighted sum of frames technique to emphasize informative frames while focusing less on irrelevant ones. Finally, our comment decoder with a cross-attention mechanism that attends to each modality ensures that the generated comment reflects contextual cues from both chats and video. Furthermore, to address the limitations of existing datasets, which predominantly focus on Chinese-language content with limited video categories, we have constructed a large scale, diverse, multimodal English video comments dataset. Extracted from Twitch, this dataset covers 11 video categories, totaling 438 hours and 3.2 million comments. We demonstrate the effectiveness of our SFAT model by comparing it to existing methods for generating comments from live video and ongoing dialogue contexts.
Spiritual-LLM : Gita Inspired Mental Health Therapy In the Era of LLMs
Jun 23, 2025Traditional mental health support systems often generate responses based solely on the user's current emotion and situations, resulting in superficial interventions that fail to address deeper emotional needs. This study introduces a novel framework by integrating spiritual wisdom from the Bhagavad Gita with advanced large language model GPT-4o to enhance emotional well-being. We present the GITes (Gita Integrated Therapy for Emotional Support) dataset, which enhances the existing ExTES mental health dataset by including 10,729 spiritually guided responses generated by GPT-4o and evaluated by domain experts. We benchmark GITes against 12 state-of-the-art LLMs, including both mental health specific and general purpose models. To evaluate spiritual relevance in generated responses beyond what conventional n-gram based metrics capture, we propose a novel Spiritual Insight metric and automate assessment via an LLM as jury framework using chain-of-thought prompting. Integrating spiritual guidance into AI driven support enhances both NLP and spiritual metrics for the best performing LLM Phi3-Mini 3.2B Instruct, achieving improvements of 122.71% in ROUGE, 126.53% in METEOR, 8.15% in BERT score, 15.92% in Spiritual Insight, 18.61% in Sufficiency and 13.22% in Relevance compared to its zero-shot counterpart. While these results reflect substantial improvements across automated empathy and spirituality metrics, further validation in real world patient populations remains a necessary step. Our findings indicate a strong potential for AI systems enriched with spiritual guidance to enhance user satisfaction and perceived support outcomes. The code and dataset will be publicly available to advance further research in this emerging area.
Exploring the Role of Diversity in Example Selection for In-Context Learning
May 03, 2025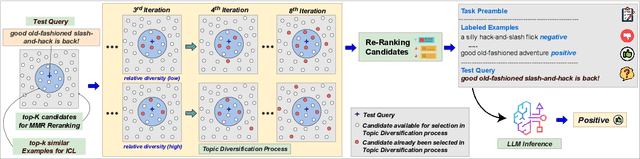
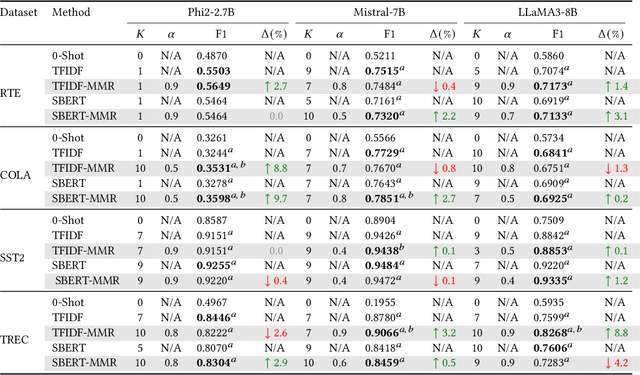
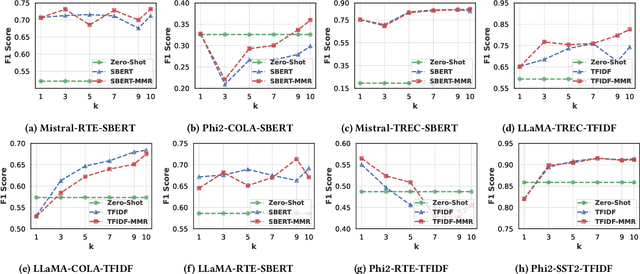
In-Context Learning (ICL) has gained prominence due to its ability to perform tasks without requiring extensive training data and its robustness to noisy labels. A typical ICL workflow involves selecting localized examples relevant to a given input using sparse or dense embedding-based similarity functions. However, relying solely on similarity-based selection may introduce topical biases in the retrieved contexts, potentially leading to suboptimal downstream performance. We posit that reranking the retrieved context to enhance topical diversity can improve downstream task performance. To achieve this, we leverage maximum marginal relevance (MMR) which balances topical similarity with inter-example diversity. Our experimental results demonstrate that diversifying the selected examples leads to consistent improvements in downstream performance across various context sizes and similarity functions. The implementation of our approach is made available at https://github.com/janak11111/Diverse-ICL.
MM-PhyRLHF: Reinforcement Learning Framework for Multimodal Physics Question-Answering
Apr 19, 2024



Recent advancements in LLMs have shown their significant potential in tasks like text summarization and generation. Yet, they often encounter difficulty while solving complex physics problems that require arithmetic calculation and a good understanding of concepts. Moreover, many physics problems include images that contain important details required to understand the problem's context. We propose an LMM-based chatbot to answer multimodal physics MCQs. For domain adaptation, we utilize the MM-PhyQA dataset comprising Indian high school-level multimodal physics problems. To improve the LMM's performance, we experiment with two techniques, RLHF (Reinforcement Learning from Human Feedback) and Image Captioning. In image captioning, we add a detailed explanation of the diagram in each image, minimizing hallucinations and image processing errors. We further explore the integration of Reinforcement Learning from Human Feedback (RLHF) methodology inspired by the ranking approach in RLHF to enhance the human-like problem-solving abilities of the models. The RLHF approach incorporates human feedback into the learning process of LLMs, improving the model's problem-solving skills, truthfulness, and reasoning capabilities, minimizing the hallucinations in the answers, and improving the quality instead of using vanilla-supervised fine-tuned models. We employ the LLaVA open-source model to answer multimodal physics MCQs and compare the performance with and without using RLHF.
MM-PhyQA: Multimodal Physics Question-Answering With Multi-Image CoT Prompting
Apr 11, 2024While Large Language Models (LLMs) can achieve human-level performance in various tasks, they continue to face challenges when it comes to effectively tackling multi-step physics reasoning tasks. To identify the shortcomings of existing models and facilitate further research in this area, we curated a novel dataset, MM-PhyQA, which comprises well-constructed, high schoollevel multimodal physics problems. By evaluating the performance of contemporary LLMs that are publicly available, both with and without the incorporation of multimodal elements in these problems, we aim to shed light on their capabilities. For generating answers for questions consisting of multimodal input (in this case, images and text) we employed Zero-shot prediction using GPT-4 and utilized LLaVA (LLaVA and LLaVA-1.5), the latter of which were fine-tuned on our dataset. For evaluating the performance of LLMs consisting solely of textual input, we tested the performance of the base and fine-tuned versions of the Mistral-7B and LLaMA2-7b models. We also showcased the performance of the novel Multi-Image Chain-of-Thought (MI-CoT) Prompting technique, which when used to train LLaVA-1.5 13b yielded the best results when tested on our dataset, with superior scores in most metrics and the highest accuracy of 71.65% on the test set.
Deep Learning Based Named Entity Recognition Models for Recipes
Feb 27, 2024


Food touches our lives through various endeavors, including flavor, nourishment, health, and sustainability. Recipes are cultural capsules transmitted across generations via unstructured text. Automated protocols for recognizing named entities, the building blocks of recipe text, are of immense value for various applications ranging from information extraction to novel recipe generation. Named entity recognition is a technique for extracting information from unstructured or semi-structured data with known labels. Starting with manually-annotated data of 6,611 ingredient phrases, we created an augmented dataset of 26,445 phrases cumulatively. Simultaneously, we systematically cleaned and analyzed ingredient phrases from RecipeDB, the gold-standard recipe data repository, and annotated them using the Stanford NER. Based on the analysis, we sampled a subset of 88,526 phrases using a clustering-based approach while preserving the diversity to create the machine-annotated dataset. A thorough investigation of NER approaches on these three datasets involving statistical, fine-tuning of deep learning-based language models and few-shot prompting on large language models (LLMs) provides deep insights. We conclude that few-shot prompting on LLMs has abysmal performance, whereas the fine-tuned spaCy-transformer emerges as the best model with macro-F1 scores of 95.9%, 96.04%, and 95.71% for the manually-annotated, augmented, and machine-annotated datasets, respectively.