 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRIS: Interleaved Reinforcement with Incremental Staged Curriculum for Cross-Lingual Mathematical Reasoning
Apr 27, 2026Curriculum learning helps language models tackle complex reasoning by gradually increasing task difficulty. However, it often fails to generate consistent step-by-step reasoning, especially in multilingual and low-resource settings where cross-lingual transfer from English to Indian languages remains limited. We propose IRIS: Interleaved Reinforcement with Incremental Staged Curriculum, a two-axis framework that combines Supervised Fine-Tuning on progressively harder problems (vertical axis) with Reverse Curriculum Reinforcement Learning to reduce reliance on step-by-step guidance (horizontal axis). We design a composite reward combining correctness, step-wise alignment, continuity, and numeric incentives, optimized via Group Relative Policy Optimization (GRPO). We release CL-Math, a dataset of 29k problems with step-level annotations in English, Hindi, and Marathi. Across standard benchmarks and curated multilingual test sets, IRIS consistently improves performance, with strong results on math reasoning tasks and substantial gains in low-resource and bilingual settings, alongside modest improvements in high-resource languages.
Multilingual Mathematical Reasoning: Advancing Open-Source LLMs in Hindi and English
Dec 24, 2024



Large Language Models (LLMs) excel in linguistic tasks but struggle with mathematical reasoning, particularly in non English languages like Hindi. This research aims to enhance the mathematical reasoning skills of smaller, resource efficient open-source LLMs in both Hindi and English. We evaluate models like OpenHathi 7B, LLaMA-2 7B, WizardMath 7B, Mistral 7B, LLeMMa 7B, MAmmoTH 7B, Gemini Pro, and GPT-4 using zero-shot, few-shot chain-of-thought (CoT) methods, and supervised fine-tuning. Our approach incorporates curriculum learning, progressively training models on increasingly difficult problems, a novel Decomposition Strategy to simplify complex arithmetic operations, and a Structured Solution Design that divides solutions into phases. Our experiments result in notable performance enhancements. WizardMath 7B exceeds Gemini's accuracy on English datasets by +6% and matches Gemini's performance on Hindi datasets. Adopting a bilingual approach that combines English and Hindi samples achieves results comparable to individual language models, demonstrating the capability to learn mathematical reasoning in both languages. This research highlights the potential for improving mathematical reasoning in open-source LLMs.
Knowledge Graphs are all you need: Leveraging KGs in Physics Question Answering
Dec 06, 2024



This study explores the effectiveness of using knowledge graphs generated by large language models to decompose high school-level physics questions into sub-questions. We introduce a pipeline aimed at enhancing model response quality for Question Answering tasks. By employing LLMs to construct knowledge graphs that capture the internal logic of the questions, these graphs then guide the generation of subquestions. We hypothesize that this method yields sub-questions that are more logically consistent with the original questions compared to traditional decomposition techniques. Our results show that sub-questions derived from knowledge graphs exhibit significantly improved fidelity to the original question's logic. This approach not only enhances the learning experience by providing clearer and more contextually appropriate sub-questions but also highlights the potential of LLMs to transform educational methodologies. The findings indicate a promising direction for applying AI to improve the quality and effectiveness of educational content.
Steps are all you need: Rethinking STEM Education with Prompt Engineering
Dec 06, 2024Few shot and Chain-of-Thought prompting have shown promise when applied to Physics Question Answering Tasks, but are limited by the lack of mathematical ability inherent to LLMs, and are prone to hallucination. By utilizing a Mixture of Experts (MoE) Model, along with analogical prompting, we are able to show improved model performance when compared to the baseline on standard LLMs. We also survey the limits of these prompting techniques and the effects they have on model performance. Additionally, we propose Analogical CoT prompting, a prompting technique designed to allow smaller, open source models to leverage Analogical prompting, something they have struggled with, possibly due to a lack of specialist training data.
Enhancing LLMs for Physics Problem-Solving using Reinforcement Learning with Human-AI Feedback
Dec 06, 2024
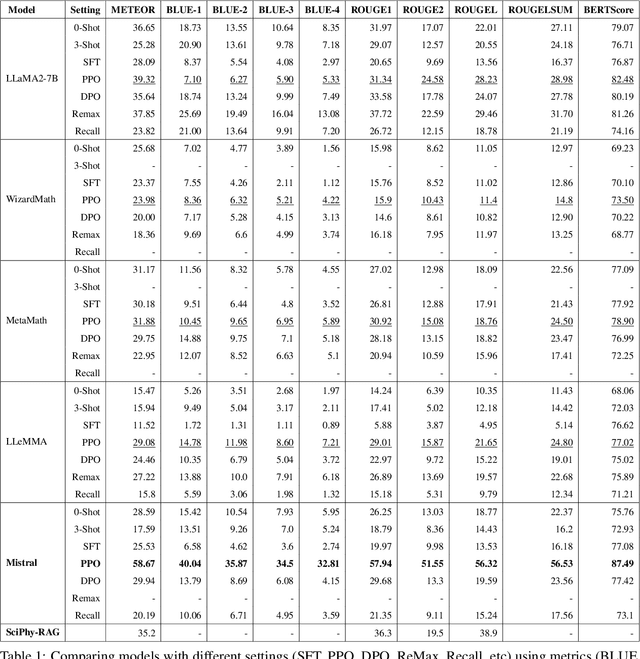
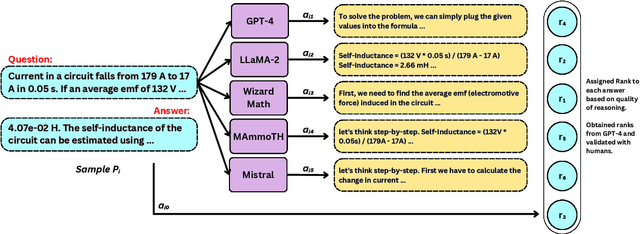
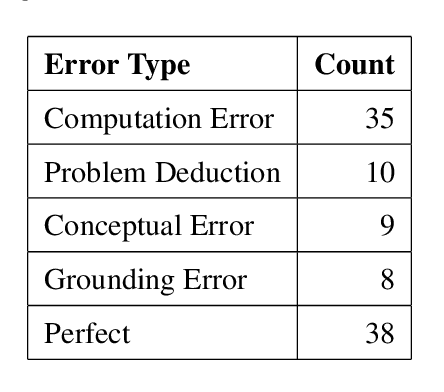
Large Language Models (LLMs) have demonstrated strong capabilities in text-based tasks but struggle with the complex reasoning required for physics problems, particularly in advanced arithmetic and conceptual understanding. While some research has explored ways to enhance LLMs in physics education using techniques such as prompt engineering and Retrieval Augmentation Generation (RAG), not enough effort has been made in addressing their limitations in physics reasoning. This paper presents a novel approach to improving LLM performance on physics questions using Reinforcement Learning with Human and Artificial Intelligence Feedback (RLHAIF). We evaluate several reinforcement learning methods, including Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO), and Remax optimization. These methods are chosen to investigate RL policy performance with different settings on the PhyQA dataset, which includes challenging physics problems from high school textbooks. Our RLHAIF model, tested on leading LLMs like LLaMA2 and Mistral, achieved superior results, notably with the MISTRAL-PPO model, demonstrating marked improvements in reasoning and accuracy. It achieved high scores, with a 58.67 METEOR score and a 0.74 Reasoning score, making it a strong example for future physics reasoning research in this area.
MM-PhyRLHF: Reinforcement Learning Framework for Multimodal Physics Question-Answering
Apr 19, 2024



Recent advancements in LLMs have shown their significant potential in tasks like text summarization and generation. Yet, they often encounter difficulty while solving complex physics problems that require arithmetic calculation and a good understanding of concepts. Moreover, many physics problems include images that contain important details required to understand the problem's context. We propose an LMM-based chatbot to answer multimodal physics MCQs. For domain adaptation, we utilize the MM-PhyQA dataset comprising Indian high school-level multimodal physics problems. To improve the LMM's performance, we experiment with two techniques, RLHF (Reinforcement Learning from Human Feedback) and Image Captioning. In image captioning, we add a detailed explanation of the diagram in each image, minimizing hallucinations and image processing errors. We further explore the integration of Reinforcement Learning from Human Feedback (RLHF) methodology inspired by the ranking approach in RLHF to enhance the human-like problem-solving abilities of the models. The RLHF approach incorporates human feedback into the learning process of LLMs, improving the model's problem-solving skills, truthfulness, and reasoning capabilities, minimizing the hallucinations in the answers, and improving the quality instead of using vanilla-supervised fine-tuned models. We employ the LLaVA open-source model to answer multimodal physics MCQs and compare the performance with and without using RLHF.