 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Mathematical Reasoning: Advancing Open-Source LLMs in Hindi and English
Dec 24, 2024



Large Language Models (LLMs) excel in linguistic tasks but struggle with mathematical reasoning, particularly in non English languages like Hindi. This research aims to enhance the mathematical reasoning skills of smaller, resource efficient open-source LLMs in both Hindi and English. We evaluate models like OpenHathi 7B, LLaMA-2 7B, WizardMath 7B, Mistral 7B, LLeMMa 7B, MAmmoTH 7B, Gemini Pro, and GPT-4 using zero-shot, few-shot chain-of-thought (CoT) methods, and supervised fine-tuning. Our approach incorporates curriculum learning, progressively training models on increasingly difficult problems, a novel Decomposition Strategy to simplify complex arithmetic operations, and a Structured Solution Design that divides solutions into phases. Our experiments result in notable performance enhancements. WizardMath 7B exceeds Gemini's accuracy on English datasets by +6% and matches Gemini's performance on Hindi datasets. Adopting a bilingual approach that combines English and Hindi samples achieves results comparable to individual language models, demonstrating the capability to learn mathematical reasoning in both languages. This research highlights the potential for improving mathematical reasoning in open-source LLMs.
Su-RoBERTa: A Semi-supervised Approach to Predicting Suicide Risk through Social Media using Base Language Models
Dec 02, 2024



In recent times, more and more people are posting about their mental states across various social media platforms. Leveraging this data, AI-based systems can be developed that help in assessing the mental health of individuals, such as suicide risk. This paper is a study done on suicidal risk assessments using Reddit data leveraging Base language models to identify patterns from social media posts. We have demonstrated that using smaller language models, i.e., less than 500M parameters, can also be effective in contrast to LLMs with greater than 500M parameters. We propose Su-RoBERTa, a fine-tuned RoBERTa on suicide risk prediction task that utilized both the labeled and unlabeled Reddit data and tackled class imbalance by data augmentation using GPT-2 model. Our Su-RoBERTa model attained a 69.84% weighted F1 score during the Final evaluation. This paper demonstrates the effectiveness of Base language models for the analysis of the risk factors related to mental health with an efficient computation pipeline
Improving Physics Reasoning in Large Language Models Using Mixture of Refinement Agents
Dec 01, 2024



Large Language Models (LLMs) demonstrate remarkable capabilities in various reasoning tasks. However, they encounter significant challenges when it comes to scientific reasoning, particularly in physics, which requires not only mathematical reasoning but also factual and conceptual understanding. When addressing complex physics problems, LLMs typically face three key issues: problem miscomprehension, incorrect concept application, and computational errors. While each of these problems can be addressed individually, there is a need for a generalized approach that can tackle all three issues simultaneously. To address this, we introduce Mixture of Refinement Agents (MoRA), a novel agentic refinement framework that iteratively refines the LLM generated base solution by correcting the aforementioned errors, resulting in a significant performance improvement for open-source LLMs. Our approach aims to bridge the gap between opensource LLMs and GPT-4o by utilizing the latter as error identifier to guide these refinement agents. We evaluate our approach on the SciEval and MMLU subsets along with our own physics dataset (PhysicsQA). MoRA significantly improves the performance of Llama-3-70B and Gemma-2-27B on these datasets, achieving up to a 16% increase in final answer accuracy.
Improving Multimodal LLMs Ability In Geometry Problem Solving, Reasoning, And Multistep Scoring
Dec 01, 2024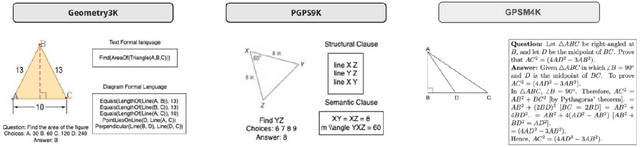
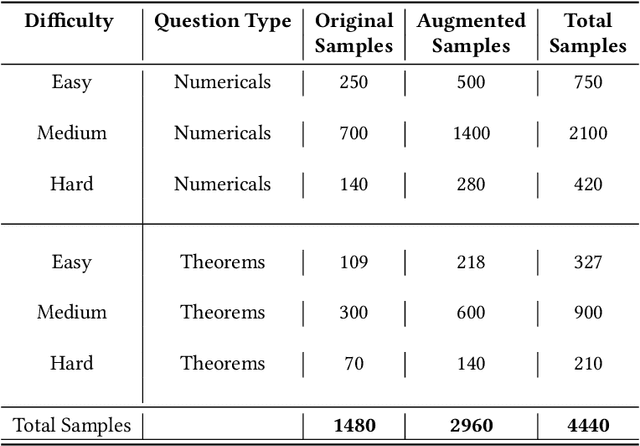
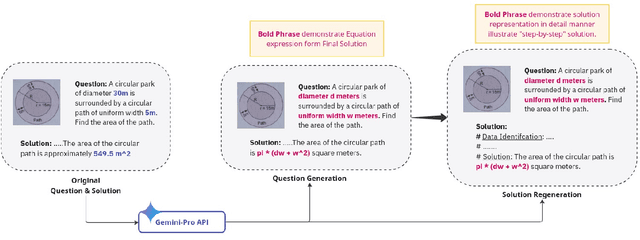
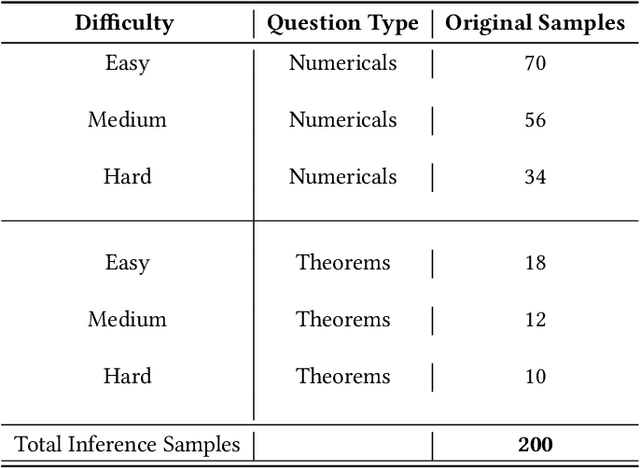
This paper presents GPSM4K, a comprehensive geometry multimodal dataset tailored to augment the problem-solving capabilities of Large Vision Language Models (LVLMs). GPSM4K encompasses 2157 multimodal question-answer pairs manually extracted from mathematics textbooks spanning grades 7-12 and is further augmented to 5340 problems, consisting of both numerical and theorem-proving questions. In contrast to PGPS9k, Geometry3K, and Geo170K which feature only objective-type questions, GPSM4K offers detailed step-by-step solutions in a consistent format, facilitating a comprehensive evaluation of problem-solving approaches. This dataset serves as an excellent benchmark for assessing the geometric reasoning capabilities of LVLMs. Evaluation of our test set shows that there is scope for improvement needed in open-source language models in geometry problem-solving. Finetuning on our training set increases the geometry problem-solving capabilities of models. Further, We also evaluate the effectiveness of techniques such as image captioning and Retrieval Augmentation generation (RAG) on model performance. We leveraged LLM to automate the task of final answer evaluation by providing ground truth and predicted solutions. This research will help to assess and improve the geometric reasoning capabilities of LVLMs.
TC-OCR: TableCraft OCR for Efficient Detection & Recognition of Table Structure & Content
Apr 19, 2024



The automatic recognition of tabular data in document images presents a significant challenge due to the diverse range of table styles and complex structures. Tables offer valuable content representation, enhancing the predictive capabilities of various systems such as search engines and Knowledge Graphs. Addressing the two main problems, namely table detection (TD) and table structure recognition (TSR), has traditionally been approached independently. In this research, we propose an end-to-end pipeline that integrates deep learning models, including DETR, CascadeTabNet, and PP OCR v2, to achieve comprehensive image-based table recognition. This integrated approach effectively handles diverse table styles, complex structures, and image distortions, resulting in improved accuracy and efficiency compared to existing methods like Table Transformers. Our system achieves simultaneous table detection (TD), table structure recognition (TSR), and table content recognition (TCR), preserving table structures and accurately extracting tabular data from document images. The integration of multiple models addresses the intricacies of table recognition, making our approach a promising solution for image-based table understanding, data extraction, and information retrieval applications. Our proposed approach achieves an IOU of 0.96 and an OCR Accuracy of 78%, showcasing a remarkable improvement of approximately 25% in the OCR Accuracy compared to the previous Table Transformer approach.
RanLayNet: A Dataset for Document Layout Detection used for Domain Adaptation and Generalization
Apr 15, 2024



Large ground-truth datasets and recent advances in deep learning techniques have been useful for layout detection. However, because of the restricted layout diversity of these datasets, training on them requires a sizable number of annotated instances, which is both expensive and time-consuming. As a result, differences between the source and target domains may significantly impact how well these models function. To solve this problem, domain adaptation approaches have been developed that use a small quantity of labeled data to adjust the model to the target domain. In this research, we introduced a synthetic document dataset called RanLayNet, enriched with automatically assigned labels denoting spatial positions, ranges, and types of layout elements. The primary aim of this endeavor is to develop a versatile dataset capable of training models with robustness and adaptability to diverse document formats. Through empirical experimentation, we demonstrate that a deep layout identification model trained on our dataset exhibits enhanced performance compared to a model trained solely on actual documents. Moreover, we conduct a comparative analysis by fine-tuning inference models using both PubLayNet and IIIT-AR-13K datasets on the Doclaynet dataset. Our findings emphasize that models enriched with our dataset are optimal for tasks such as achieving 0.398 and 0.588 mAP95 score in the scientific document domain for the TABLE class.