 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multimodal LLMs Ability In Geometry Problem Solving, Reasoning, And Multistep Scoring
Dec 01, 2024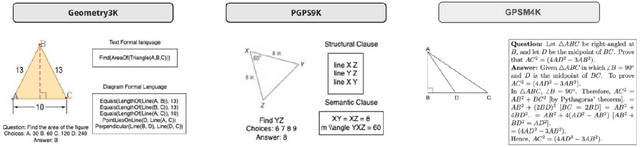
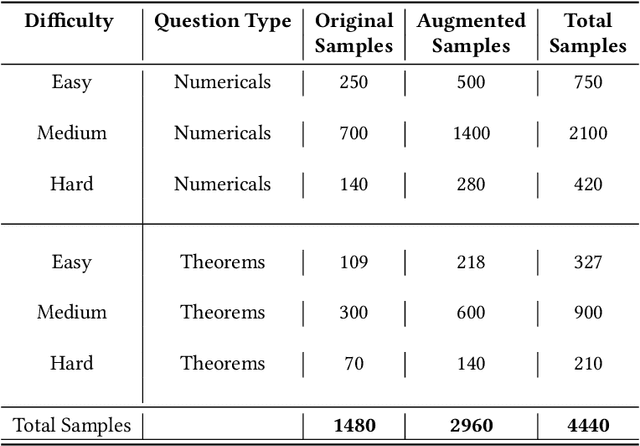
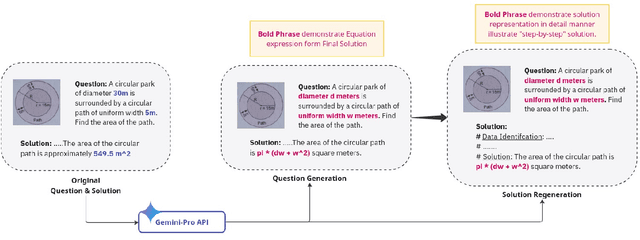
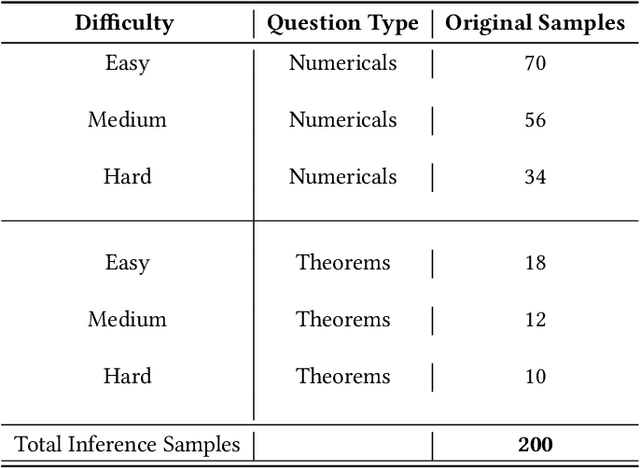
This paper presents GPSM4K, a comprehensive geometry multimodal dataset tailored to augment the problem-solving capabilities of Large Vision Language Models (LVLMs). GPSM4K encompasses 2157 multimodal question-answer pairs manually extracted from mathematics textbooks spanning grades 7-12 and is further augmented to 5340 problems, consisting of both numerical and theorem-proving questions. In contrast to PGPS9k, Geometry3K, and Geo170K which feature only objective-type questions, GPSM4K offers detailed step-by-step solutions in a consistent format, facilitating a comprehensive evaluation of problem-solving approaches. This dataset serves as an excellent benchmark for assessing the geometric reasoning capabilities of LVLMs. Evaluation of our test set shows that there is scope for improvement needed in open-source language models in geometry problem-solving. Finetuning on our training set increases the geometry problem-solving capabilities of models. Further, We also evaluate the effectiveness of techniques such as image captioning and Retrieval Augmentation generation (RAG) on model performance. We leveraged LLM to automate the task of final answer evaluation by providing ground truth and predicted solutions. This research will help to assess and improve the geometric reasoning capabilities of LVLMs.
Improving Physics Reasoning in Large Language Models Using Mixture of Refinement Agents
Dec 01, 2024



Large Language Models (LLMs) demonstrate remarkable capabilities in various reasoning tasks. However, they encounter significant challenges when it comes to scientific reasoning, particularly in physics, which requires not only mathematical reasoning but also factual and conceptual understanding. When addressing complex physics problems, LLMs typically face three key issues: problem miscomprehension, incorrect concept application, and computational errors. While each of these problems can be addressed individually, there is a need for a generalized approach that can tackle all three issues simultaneously. To address this, we introduce Mixture of Refinement Agents (MoRA), a novel agentic refinement framework that iteratively refines the LLM generated base solution by correcting the aforementioned errors, resulting in a significant performance improvement for open-source LLMs. Our approach aims to bridge the gap between opensource LLMs and GPT-4o by utilizing the latter as error identifier to guide these refinement agents. We evaluate our approach on the SciEval and MMLU subsets along with our own physics dataset (PhysicsQA). MoRA significantly improves the performance of Llama-3-70B and Gemma-2-27B on these datasets, achieving up to a 16% increase in final answer accuracy.