 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceAgentBench: Are Voice Assistants ready for agentic tasks?
Oct 09, 2025
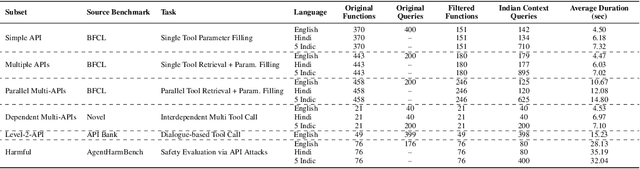
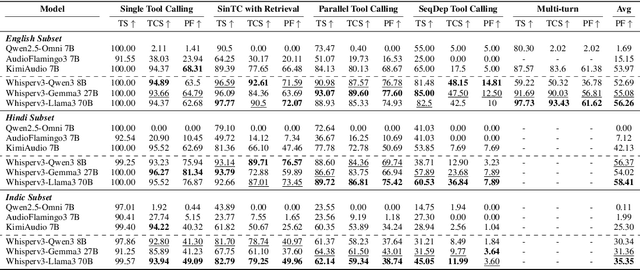
Large-scale Speech Language Models (SpeechLMs) have enabled voice assistants capable of understanding natural spoken queries and performing complex tasks. However, existing speech benchmarks primarily focus on isolated capabilities such as transcription, or question-answering, and do not systematically evaluate agentic scenarios encompassing multilingual and cultural understanding, as well as adversarial robustness. To address this, we introduce VoiceAgentBench, a comprehensive benchmark designed to evaluate SpeechLMs in realistic spoken agentic settings. It comprises over 5,500 synthetic spoken queries, including dialogues grounded in Indian context, covering single-tool invocations, multi-tool workflows, multi-turn interactions, and safety evaluations. The benchmark supports English, Hindi, and 5 other Indian languages, reflecting real-world linguistic and cultural diversity. We simulate speaker variability using a novel sampling algorithm that selects audios for TTS voice conversion based on its speaker embeddings, maximizing acoustic and speaker diversity. Our evaluation measures tool selection accuracy, structural consistency, and the correctness of tool invocations, including adversarial robustness. Our experiments reveal significant gaps in contextual tool orchestration tasks, Indic generalization, and adversarial robustness, exposing critical limitations of current SpeechLMs.
EvolveCaptions: Empowering DHH Users Through Real-Time Collaborative Captioning
Oct 02, 2025Automatic Speech Recognition (ASR) systems often fail to accurately transcribe speech from Deaf and Hard of Hearing (DHH) individuals, especially during real-time conversations. Existing personalization approaches typically require extensive pre-recorded data and place the burden of adaptation on the DHH speaker. We present EvolveCaptions, a real-time, collaborative ASR adaptation system that supports in-situ personalization with minimal effort. Hearing participants correct ASR errors during live conversations. Based on these corrections, the system generates short, phonetically targeted prompts for the DHH speaker to record, which are then used to fine-tune the ASR model. In a study with 12 DHH and six hearing participants, EvolveCaptions reduced Word Error Rate (WER) across all DHH users within one hour of use, using only five minutes of recording time on average. Participants described the system as intuitive, low-effort, and well-integrated into communication. These findings demonstrate the promise of collaborative, real-time ASR adaptation for more equitable communication.
Predicting Patient Survival with Airway Biomarkers using nn-Unet/Radiomics
Jun 13, 2025The primary objective of the AIIB 2023 competition is to evaluate the predictive significance of airway-related imaging biomarkers in determining the survival outcomes of patients with lung fibrosis.This study introduces a comprehensive three-stage approach. Initially, a segmentation network, namely nn-Unet, is employed to delineate the airway's structural boundaries. Subsequently, key features are extracted from the radiomic images centered around the trachea and an enclosing bounding box around the airway. This step is motivated by the potential presence of critical survival-related insights within the tracheal region as well as pertinent information encoded in the structure and dimensions of the airway. Lastly, radiomic features obtained from the segmented areas are integrated into an SVM classifier. We could obtain an overall-score of 0.8601 for the segmentation in Task 1 while 0.7346 for the classification in Task 2.
Knowledge Graphs are all you need: Leveraging KGs in Physics Question Answering
Dec 06, 2024



This study explores the effectiveness of using knowledge graphs generated by large language models to decompose high school-level physics questions into sub-questions. We introduce a pipeline aimed at enhancing model response quality for Question Answering tasks. By employing LLMs to construct knowledge graphs that capture the internal logic of the questions, these graphs then guide the generation of subquestions. We hypothesize that this method yields sub-questions that are more logically consistent with the original questions compared to traditional decomposition techniques. Our results show that sub-questions derived from knowledge graphs exhibit significantly improved fidelity to the original question's logic. This approach not only enhances the learning experience by providing clearer and more contextually appropriate sub-questions but also highlights the potential of LLMs to transform educational methodologies. The findings indicate a promising direction for applying AI to improve the quality and effectiveness of educational content.
Improving Physics Reasoning in Large Language Models Using Mixture of Refinement Agents
Dec 01, 2024



Large Language Models (LLMs) demonstrate remarkable capabilities in various reasoning tasks. However, they encounter significant challenges when it comes to scientific reasoning, particularly in physics, which requires not only mathematical reasoning but also factual and conceptual understanding. When addressing complex physics problems, LLMs typically face three key issues: problem miscomprehension, incorrect concept application, and computational errors. While each of these problems can be addressed individually, there is a need for a generalized approach that can tackle all three issues simultaneously. To address this, we introduce Mixture of Refinement Agents (MoRA), a novel agentic refinement framework that iteratively refines the LLM generated base solution by correcting the aforementioned errors, resulting in a significant performance improvement for open-source LLMs. Our approach aims to bridge the gap between opensource LLMs and GPT-4o by utilizing the latter as error identifier to guide these refinement agents. We evaluate our approach on the SciEval and MMLU subsets along with our own physics dataset (PhysicsQA). MoRA significantly improves the performance of Llama-3-70B and Gemma-2-27B on these datasets, achieving up to a 16% increase in final answer accuracy.
SwissNYF: Tool Grounded LLM Agents for Black Box Setting
Feb 15, 2024



While Large Language Models (LLMs) have demonstrated enhanced capabilities in function-calling, these advancements primarily rely on accessing the functions' responses. This methodology is practical for simpler APIs but faces scalability issues with irreversible APIs that significantly impact the system, such as a database deletion API. Similarly, processes requiring extensive time for each API call and those necessitating forward planning, like automated action pipelines, present complex challenges. Furthermore, scenarios often arise where a generalized approach is needed because algorithms lack direct access to the specific implementations of these functions or secrets to use them. Traditional tool planning methods are inadequate in these cases, compelling the need to operate within black-box environments. Unlike their performance in tool manipulation, LLMs excel in black-box tasks, such as program synthesis. Therefore, we harness the program synthesis capabilities of LLMs to strategize tool usage in black-box settings, ensuring solutions are verified prior to implementation. We introduce TOPGUN, an ingeniously crafted approach leveraging program synthesis for black box tool planning. Accompanied by SwissNYF, a comprehensive suite that integrates black-box algorithms for planning and verification tasks, addressing the aforementioned challenges and enhancing the versatility and effectiveness of LLMs in complex API interactions. The public code for SwissNYF is available at https://github.com/iclr-dummy-user/SwissNYF.
Sound Unblending: Exploring Sound Manipulations for Accessible Mixed-Reality Awareness
Jan 20, 2024



Mixed-reality (MR) soundscapes blend real-world sound with virtual audio from hearing devices, presenting intricate auditory information that is hard to discern and differentiate. This is particularly challenging for blind or visually impaired individuals, who rely on sounds and descriptions in their everyday lives. To understand how complex audio information is consumed, we analyzed online forum posts within the blind community, identifying prevailing challenges, needs, and desired solutions. We synthesized the results and proposed Sound Unblending for increasing MR sound awareness, which includes six sound manipulations: Ambience Builder, Feature Shifter, Earcon Generator, Prioritizer, Spatializer, and Stylizer. To evaluate the effectiveness of sound unblending, we conducted a user study with 18 blind participants across three simulated MR scenarios, where participants identified specific sounds within intricate soundscapes. We found that sound unblending increased MR sound awareness and minimized cognitive load. Finally, we developed three real-world example applications to demonstrate the practicality of sound unblending.
Hunting imaging biomarkers in pulmonary fibrosis: Benchmarks of the AIIB23 challenge
Dec 21, 2023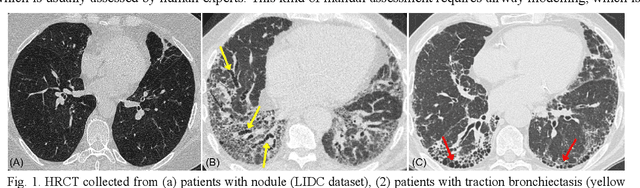
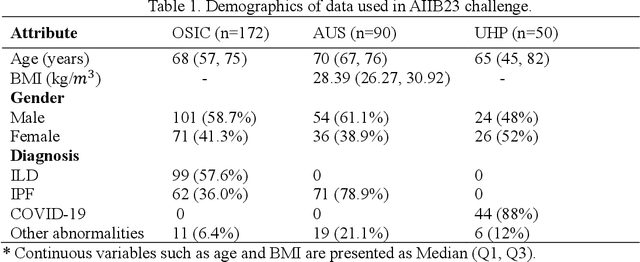
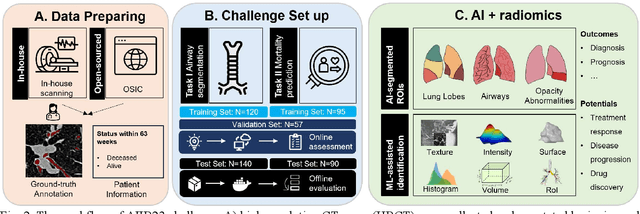
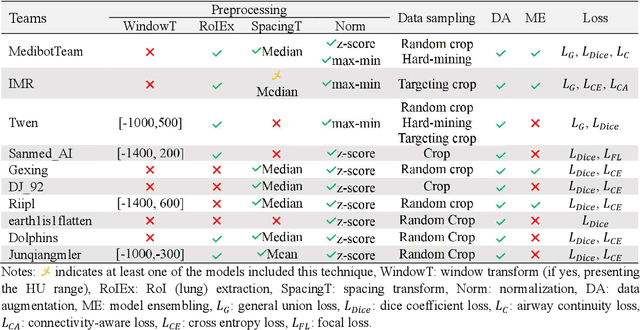
Airway-related quantitative imaging biomarkers are crucial for examination, diagnosis, and prognosis in pulmonary diseases. However, the manual delineation of airway trees remains prohibitively time-consuming. While significant efforts have been made towards enhancing airway modelling, current public-available datasets concentrate on lung diseases with moderate morphological variations. The intricate honeycombing patterns present in the lung tissues of fibrotic lung disease patients exacerbate the challenges, often leading to various prediction errors. To address this issue, the 'Airway-Informed Quantitative CT Imaging Biomarker for Fibrotic Lung Disease 2023' (AIIB23) competition was organized in conjunction with the official 2023 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). The airway structures were meticulously annotated by three experienced radiologists. Competitors were encouraged to develop automatic airway segmentation models with high robustness and generalization abilities, followed by exploring the most correlated QIB of mortality prediction. A training set of 120 high-resolution computerised tomography (HRCT) scans were publicly released with expert annotations and mortality status. The online validation set incorporated 52 HRCT scans from patients with fibrotic lung disease and the offline test set included 140 cases from fibrosis and COVID-19 patients. The results have shown that the capacity of extracting airway trees from patients with fibrotic lung disease could be enhanced by introducing voxel-wise weighted general union loss and continuity loss. In addition to the competitive image biomarkers for prognosis, a strong airway-derived biomarker (Hazard ratio>1.5, p<0.0001) was revealed for survival prognostication compared with existing clinical measurements, clinician assessment and AI-based biomarkers.
ProtoSound: A Personalized and Scalable Sound Recognition System for Deaf and Hard-of-Hearing Users
Feb 22, 2022

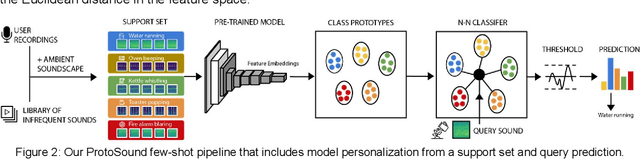
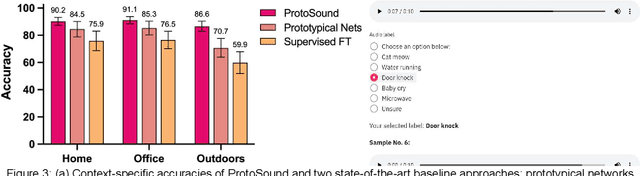
Recent advances have enabled automatic sound recognition systems for deaf and hard of hearing (DHH) users on mobile devices. However, these tools use pre-trained, generic sound recognition models, which do not meet the diverse needs of DHH users. We introduce ProtoSound, an interactive system for customizing sound recognition models by recording a few examples, thereby enabling personalized and fine-grained categories. ProtoSound is motivated by prior work examining sound awareness needs of DHH people and by a survey we conducted with 472 DHH participants. To evaluate ProtoSound, we characterized performance on two real-world sound datasets, showing significant improvement over state-of-the-art (e.g., +9.7% accuracy on the first dataset). We then deployed ProtoSound's end-user training and real-time recognition through a mobile application and recruited 19 hearing participants who listened to the real-world sounds and rated the accuracy across 56 locations (e.g., homes, restaurants, parks). Results show that ProtoSound personalized the model on-device in real-time and accurately learned sounds across diverse acoustic contexts. We close by discussing open challenges in personalizable sound recognition, including the need for better recording interfaces and algorithmic improvements.
Nonverbal Sound Detection for Disordered Speech
Feb 15, 2022
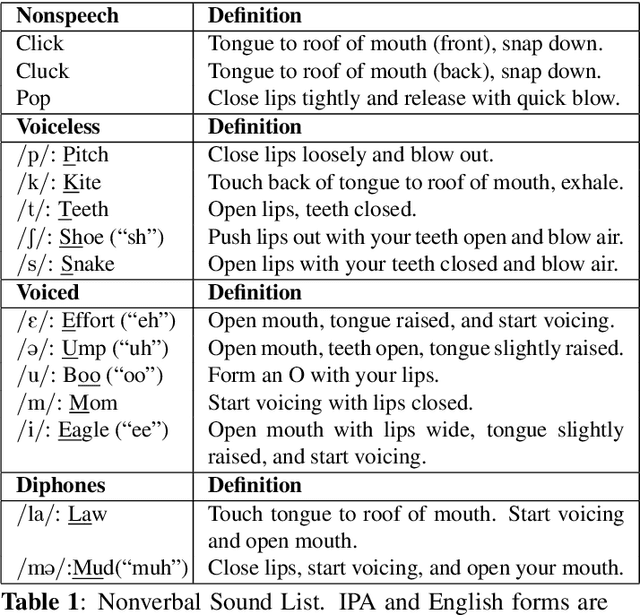


Voice assistants have become an essential tool for people with various disabilities because they enable complex phone- or tablet-based interactions without the need for fine-grained motor control, such as with touchscreens. However, these systems are not tuned for the unique characteristics of individuals with speech disorders, including many of those who have a motor-speech disorder, are deaf or hard of hearing, have a severe stutter, or are minimally verbal. We introduce an alternative voice-based input system which relies on sound event detection using fifteen nonverbal mouth sounds like "pop," "click," or "eh." This system was designed to work regardless of ones' speech abilities and allows full access to existing technology. In this paper, we describe the design of a dataset, model considerations for real-world deployment, and efforts towards model personalization. Our fully-supervised model achieves segment-level precision and recall of 88.6% and 88.4% on an internal dataset of 710 adults, while achieving 0.31 false positives per hour on aggressors such as speech. Five-shot personalization enables satisfactory performance in 84.5% of cases where the generic model fails.