 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoSound: A Personalized and Scalable Sound Recognition System for Deaf and Hard-of-Hearing Users
Feb 22, 2022

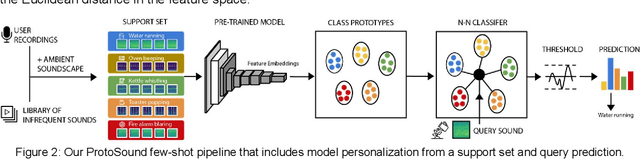
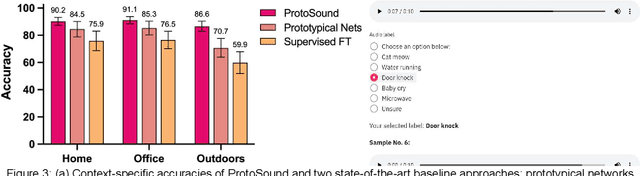
Recent advances have enabled automatic sound recognition systems for deaf and hard of hearing (DHH) users on mobile devices. However, these tools use pre-trained, generic sound recognition models, which do not meet the diverse needs of DHH users. We introduce ProtoSound, an interactive system for customizing sound recognition models by recording a few examples, thereby enabling personalized and fine-grained categories. ProtoSound is motivated by prior work examining sound awareness needs of DHH people and by a survey we conducted with 472 DHH participants. To evaluate ProtoSound, we characterized performance on two real-world sound datasets, showing significant improvement over state-of-the-art (e.g., +9.7% accuracy on the first dataset). We then deployed ProtoSound's end-user training and real-time recognition through a mobile application and recruited 19 hearing participants who listened to the real-world sounds and rated the accuracy across 56 locations (e.g., homes, restaurants, parks). Results show that ProtoSound personalized the model on-device in real-time and accurately learned sounds across diverse acoustic contexts. We close by discussing open challenges in personalizable sound recognition, including the need for better recording interfaces and algorithmic improvements.
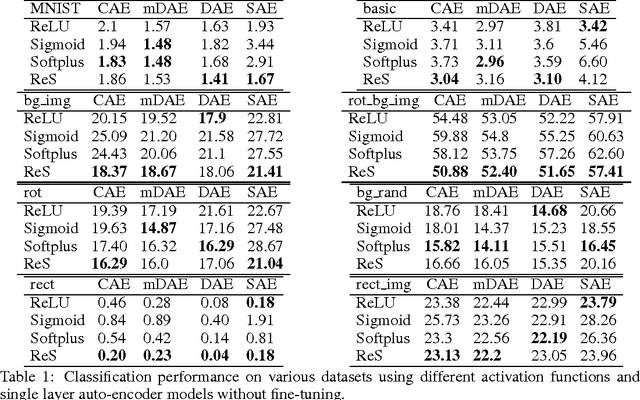
Why Regularized Auto-Encoders learn Sparse Representation?
Jun 17, 2016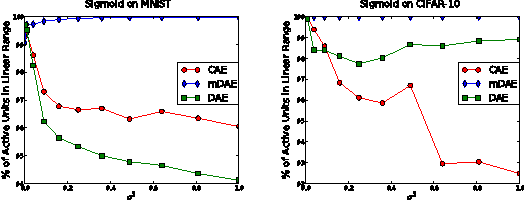
While the authors of Batch Normalization (BN) identify and address an important problem involved in training deep networks-- \textit{Internal Covariate Shift}-- the current solution has certain drawbacks. For instance, BN depends on batch statistics for layerwise input normalization during training which makes the estimates of mean and standard deviation of input (distribution) to hidden layers inaccurate due to shifting parameter values (especially during initial training epochs). Another fundamental problem with BN is that it cannot be used with batch-size $ 1 $ during training. We address these drawbacks of BN by proposing a non-adaptive normalization technique for removing covariate shift, that we call \textit{Normalization Propagation}. Our approach does not depend on batch statistics, but rather uses a data-independent parametric estimate of mean and standard-deviation in every layer thus being computationally faster compared with BN. We exploit the observation that the pre-activation before Rectified Linear Units follow Gaussian distribution in deep networks, and that once the first and second order statistics of any given dataset are normalized, we can forward propagate this normalization without the need for recalculating the approximate statistics for hidden layers.