 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfusionBench: An Expert-Validated Benchmark for Confusion Recognition and Localization in Educational Videos
Mar 18, 2026Recognizing and localizing student confusion from video is an important yet challenging problem in educational AI. Existing confusion datasets suffer from noisy labels, coarse temporal annotations, and limited expert validation, which hinder reliable fine-grained recognition and temporally grounded analysis. To address these limitations, we propose a practical multi-stage filtering pipeline that integrates two stages of model-assisted screening, researcher curation, and expert validation to build a higher-quality benchmark for confusion understanding. Based on this pipeline, we introduce ConfusionBench, a new benchmark for educational videos consisting of a balanced confusion recognition dataset and a video localization dataset. We further provide zero-shot baseline evaluations of a representative open-source model and a proprietary model on clip-level confusion recognition, long-video confusion localization tasks. Experimental results show that the proprietary model performs better overall but tends to over-predict transitional segments, while the open-source model is more conservative and more prone to missed detections. In addition, the proposed student confusion report visualization can support educational experts in making intervention decisions and adapting learning plans accordingly. All datasets and related materials will be made publicly available on our project page.
InterventionLens: A Multi-Agent Framework for Detecting ASD Intervention Strategies in Parent-Child Shared Reading
Mar 14, 2026Home-based interventions like parent-child shared reading provide a cost-effective approach for supporting children with autism spectrum disorder (ASD). However, analyzing caregiver intervention strategies in naturalistic home interactions typically relies on expert annotation, which is costly, time-intensive, and difficult to scale. To address this challenge, we propose InterventionLens, an end-to-end multi-agent system for automatically detecting and temporally segmenting caregiver intervention strategies from shared reading videos. Without task-specific model training or fine-tuning, InterventionLens uses a collaborative multi-agent architecture to integrate multimodal interaction content and perform fine-grained strategy analysis. Experiments on the ASD-HI dataset show that InterventionLens achieves an overall F1 score of 79.44\%, outperforming the baseline by 19.72\%. These results suggest that InterventionLens is a promising system for analyzing caregiver intervention strategies in home-based ASD shared reading settings. Additional resources will be released on the project page.
MistyPilot: An Agentic Fast-Slow Thinking LLM Framework for Misty Social Robots
Mar 04, 2026With the availability of open APIs in social robots, it has become easier to customize general-purpose tools to meet users' needs. However, interpreting high-level user instructions, selecting and configuring appropriate tools, and executing them reliably remain challenging for users without programming experience. To address these challenges, we introduce MistyPilot, an agentic LLM-driven framework for autonomous tool selection, orchestration, and parameter configuration. MistyPilot comprises two core components: a Physically Interactive Agent (PIA) and a Socially Intelligent Agent (SIA). The PIA enables robust sensor-triggered and tool-driven task execution, while the SIA generates socially intelligent and emotionally aligned dialogue. MistyPilot further integrates a fast-slow thinking paradigm to capture user preferences, reduce latency, and improve task efficiency. To comprehensively evaluate MistyPilot, we contribute five benchmark datasets. Extensive experiments demonstrate the effectiveness of our framework in routing correctness, task completeness, fast-slow thinking retrieval efficiency, tool scalability,and emotion alignment. All code, datasets, and experimental videos will be made publicly available on the project webpage.
LLM Augmented Intervenable Multimodal Adaptor for Post-operative Complication Prediction in Lung Cancer Surgery
Jan 20, 2026Postoperative complications remain a critical concern in clinical practice, adversely affecting patient outcomes and contributing to rising healthcare costs. We present MIRACLE, a deep learning architecture for prediction of risk of postoperative complications in lung cancer surgery by integrating preoperative clinical and radiological data. MIRACLE employs a hyperspherical embedding space fusion of heterogeneous inputs, enabling the extraction of robust, discriminative features from both structured clinical records and high-dimensional radiological images. To enhance transparency of prediction and clinical utility, we incorporate an interventional deep learning module in MIRACLE, that not only refines predictions but also provides interpretable and actionable insights, allowing domain experts to interactively adjust recommendations based on clinical expertise. We validate our approach on POC-L, a real-world dataset comprising 3,094 lung cancer patients who underwent surgery at Roswell Park Comprehensive Cancer Center. Our results demonstrate that MIRACLE outperforms various traditional machine learning models and contemporary large language models (LLM) variants alone, for personalized and explainable postoperative risk management.
Learning Action Hierarchies via Hybrid Geometric Diffusion
Jan 05, 2026Temporal action segmentation is a critical task in video understanding, where the goal is to assign action labels to each frame in a video. While recent advances leverage iterative refinement-based strategies, they fail to explicitly utilize the hierarchical nature of human actions. In this work, we propose HybridTAS - a novel framework that incorporates a hybrid of Euclidean and hyperbolic geometries into the denoising process of diffusion models to exploit the hierarchical structure of actions. Hyperbolic geometry naturally provides tree-like relationships between embeddings, enabling us to guide the action label denoising process in a coarse-to-fine manner: higher diffusion timesteps are influenced by abstract, high-level action categories (root nodes), while lower timesteps are refined using fine-grained action classes (leaf nodes). Extensive experiments on three benchmark datasets, GTEA, 50Salads, and Breakfast, demonstrate that our method achieves state-of-the-art performance, validating the effectiveness of hyperbolic-guided denoising for the temporal action segmentation task.
Forget Less by Learning Together through Concept Consolidation
Jan 05, 2026Custom Diffusion Models (CDMs) have gained significant attention due to their remarkable ability to personalize generative processes. However, existing CDMs suffer from catastrophic forgetting when continuously learning new concepts. Most prior works attempt to mitigate this issue under the sequential learning setting with a fixed order of concept inflow and neglect inter-concept interactions. In this paper, we propose a novel framework - Forget Less by Learning Together (FL2T) - that enables concurrent and order-agnostic concept learning while addressing catastrophic forgetting. Specifically, we introduce a set-invariant inter-concept learning module where proxies guide feature selection across concepts, facilitating improved knowledge retention and transfer. By leveraging inter-concept guidance, our approach preserves old concepts while efficiently incorporating new ones. Extensive experiments, across three datasets, demonstrates that our method significantly improves concept retention and mitigates catastrophic forgetting, highlighting the effectiveness of inter-concept catalytic behavior in incremental concept learning of ten tasks with at least 2% gain on average CLIP Image Alignment scores.
Forget Less by Learning from Parents Through Hierarchical Relationships
Jan 05, 2026Custom Diffusion Models (CDMs) offer impressive capabilities for personalization in generative modeling, yet they remain vulnerable to catastrophic forgetting when learning new concepts sequentially. Existing approaches primarily focus on minimizing interference between concepts, often neglecting the potential for positive inter-concept interactions. In this work, we present Forget Less by Learning from Parents (FLLP), a novel framework that introduces a parent-child inter-concept learning mechanism in hyperbolic space to mitigate forgetting. By embedding concept representations within a Lorentzian manifold, naturally suited to modeling tree-like hierarchies, we define parent-child relationships in which previously learned concepts serve as guidance for adapting to new ones. Our method not only preserves prior knowledge but also supports continual integration of new concepts. We validate FLLP on three public datasets and one synthetic benchmark, showing consistent improvements in both robustness and generalization.
SCOT: Self-Supervised Contrastive Pretraining For Zero-Shot Compositional Retrieval
Jan 12, 2025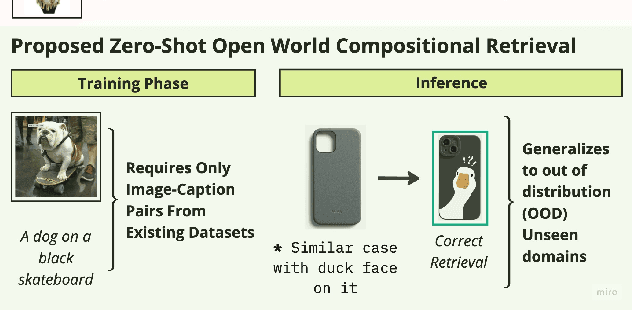
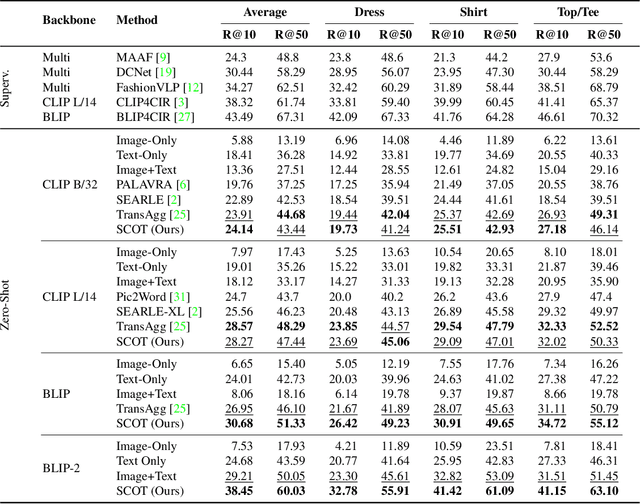
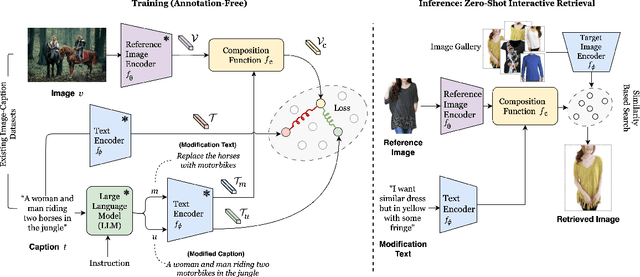
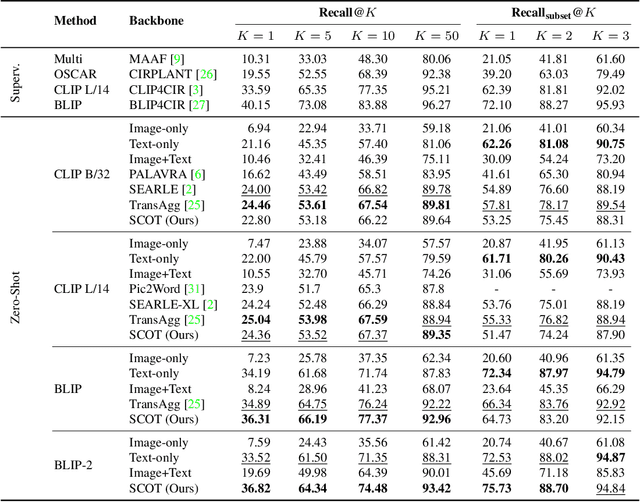
Compositional image retrieval (CIR) is a multimodal learning task where a model combines a query image with a user-provided text modification to retrieve a target image. CIR finds applications in a variety of domains including product retrieval (e-commerce) and web search. Existing methods primarily focus on fully-supervised learning, wherein models are trained on datasets of labeled triplets such as FashionIQ and CIRR. This poses two significant challenges: (i) curating such triplet datasets is labor intensive; and (ii) models lack generalization to unseen objects and domains. In this work, we propose SCOT (Self-supervised COmpositional Training), a novel zero-shot compositional pretraining strategy that combines existing large image-text pair datasets with the generative capabilities of large language models to contrastively train an embedding composition network. Specifically, we show that the text embedding from a large-scale contrastively-pretrained vision-language model can be utilized as proxy target supervision during compositional pretraining, replacing the target image embedding. In zero-shot settings, this strategy surpasses SOTA zero-shot compositional retrieval methods as well as many fully-supervised methods on standard benchmarks such as FashionIQ and CIRR.
RealCQA-V2 : Visual Premise Proving
Oct 29, 2024We introduce Visual Premise Proving (VPP), a novel task tailored to refine the process of chart question answering by deconstructing it into a series of logical premises. Each of these premises represents an essential step in comprehending a chart's content and deriving logical conclusions, thereby providing a granular look at a model's reasoning abilities. This approach represents a departure from conventional accuracy-based evaluation methods, emphasizing the model's ability to sequentially validate each premise and ideally mimic human analytical processes. A model adept at reasoning is expected to demonstrate proficiency in both data retrieval and the structural understanding of charts, suggesting a synergy between these competencies. However, in our zero-shot study using the sophisticated MATCHA model on a scientific chart question answering dataset, an intriguing pattern emerged. The model showcased superior performance in chart reasoning (27\%) over chart structure (19\%) and data retrieval (14\%). This performance gap suggests that models might more readily generalize reasoning capabilities across datasets, benefiting from consistent mathematical and linguistic semantics, even when challenged by changes in the visual domain that complicate structure comprehension and data retrieval. Furthermore, the efficacy of using accuracy of binary QA for evaluating chart reasoning comes into question if models can deduce correct answers without parsing chart data or structure. VPP highlights the importance of integrating reasoning with visual comprehension to enhance model performance in chart analysis, pushing for a balanced approach in evaluating visual data interpretation capabilities.
Ig3D: Integrating 3D Face Representations in Facial Expression Inference
Aug 29, 2024Reconstructing 3D faces with facial geometry from single images has allowed for major advances in animation, generative models, and virtual reality. However, this ability to represent faces with their 3D features is not as fully explored by the facial expression inference (FEI) community. This study therefore aims to investigate the impacts of integrating such 3D representations into the FEI task, specifically for facial expression classification and face-based valence-arousal (VA) estimation. To accomplish this, we first assess the performance of two 3D face representations (both based on the 3D morphable model, FLAME) for the FEI tasks. We further explore two fusion architectures, intermediate fusion and late fusion, for integrating the 3D face representations with existing 2D inference frameworks. To evaluate our proposed architecture, we extract the corresponding 3D representations and perform extensive tests on the AffectNet and RAF-DB datasets. Our experimental results demonstrate that our proposed method outperforms the state-of-the-art AffectNet VA estimation and RAF-DB classification tasks. Moreover, our method can act as a complement to other existing methods to boost performance in many emotion inference tasks.