 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Match Cutting: Finding and Creating Matching Audio Transitions in Movies and Videos
Aug 20, 2024A "match cut" is a common video editing technique where a pair of shots that have a similar composition transition fluidly from one to another. Although match cuts are often visual, certain match cuts involve the fluid transition of audio, where sounds from different sources merge into one indistinguishable transition between two shots. In this paper, we explore the ability to automatically find and create "audio match cuts" within videos and movies. We create a self-supervised audio representation for audio match cutting and develop a coarse-to-fine audio match pipeline that recommends matching shots and creates the blended audio. We further annotate a dataset for the proposed audio match cut task and compare the ability of multiple audio representations to find audio match cut candidates. Finally, we evaluate multiple methods to blend two matching audio candidates with the goal of creating a smooth transition. Project page and examples are available at: https://denfed.github.io/audiomatchcut/
Fine-Grained Engine Fault Sound Event Detection Using Multimodal Signals
Mar 16, 2024Sound event detection (SED) is an active area of audio research that aims to detect the temporal occurrence of sounds. In this paper, we apply SED to engine fault detection by introducing a multimodal SED framework that detects fine-grained engine faults of automobile engines using audio and accelerometer-recorded vibration. We first introduce the problem of engine fault SED on a dataset collected from a large variety of vehicles with expertly-labeled engine fault sound events. Next, we propose a SED model to temporally detect ten fine-grained engine faults that occur within vehicle engines and further explore a pretraining strategy using a large-scale weakly-labeled engine fault dataset. Through multiple evaluations, we show our proposed framework is able to effectively detect engine fault sound events. Finally, we investigate the interaction and characteristics of each modality and show that fusing features from audio and vibration improves overall engine fault SED capabilities.
CoNAN: Conditional Neural Aggregation Network For Unconstrained Face Feature Fusion
Jul 16, 2023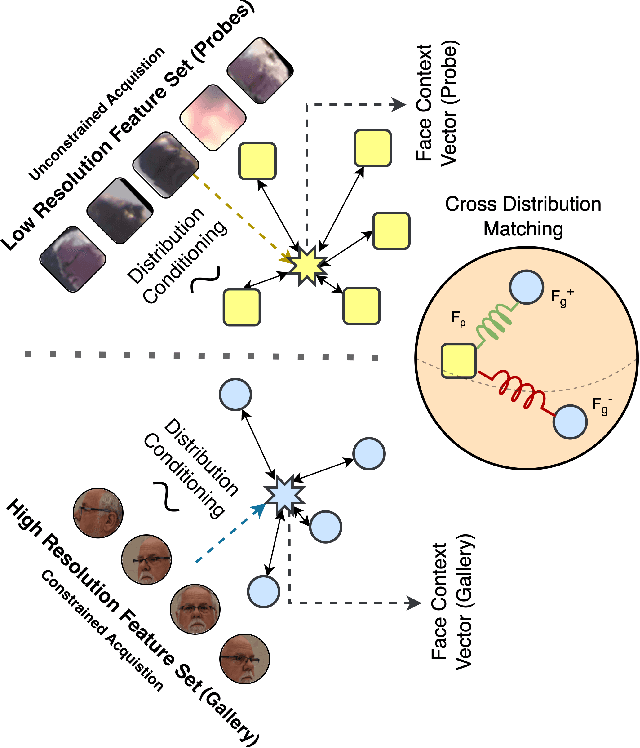
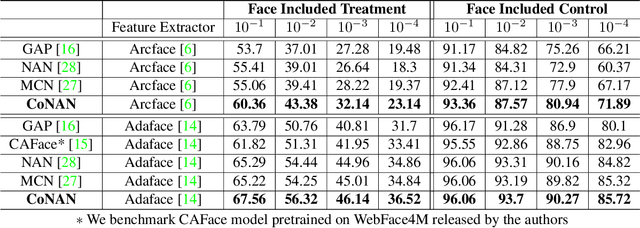
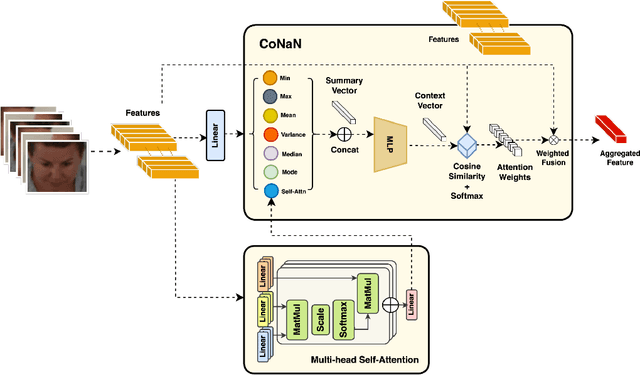
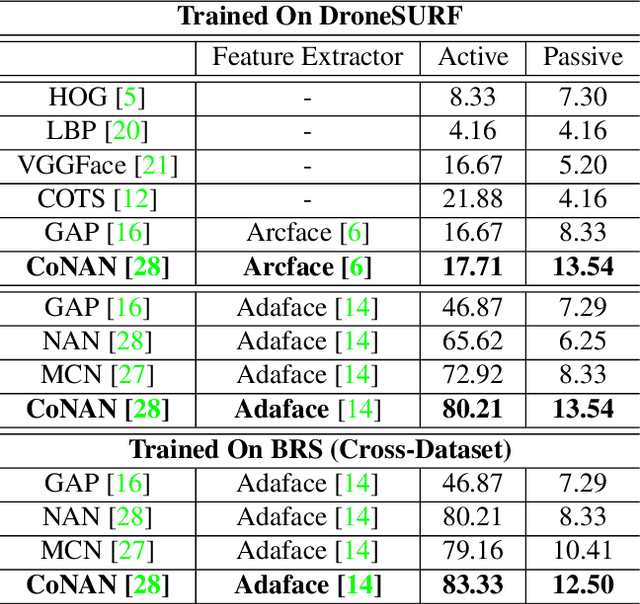
Face recognition from image sets acquired under unregulated and uncontrolled settings, such as at large distances, low resolutions, varying viewpoints, illumination, pose, and atmospheric conditions, is challenging. Face feature aggregation, which involves aggregating a set of N feature representations present in a template into a single global representation, plays a pivotal role in such recognition systems. Existing works in traditional face feature aggregation either utilize metadata or high-dimensional intermediate feature representations to estimate feature quality for aggregation. However, generating high-quality metadata or style information is not feasible for extremely low-resolution faces captured in long-range and high altitude settings. To overcome these limitations, we propose a feature distribution conditioning approach called CoNAN for template aggregation. Specifically, our method aims to learn a context vector conditioned over the distribution information of the incoming feature set, which is utilized to weigh the features based on their estimated informativeness. The proposed method produces state-of-the-art results on long-range unconstrained face recognition datasets such as BTS, and DroneSURF, validating the advantages of such an aggregation strategy.
Hear The Flow: Optical Flow-Based Self-Supervised Visual Sound Source Localization
Nov 06, 2022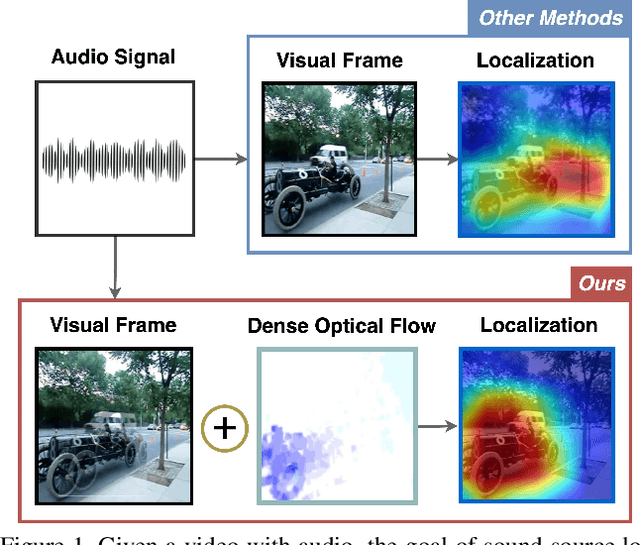
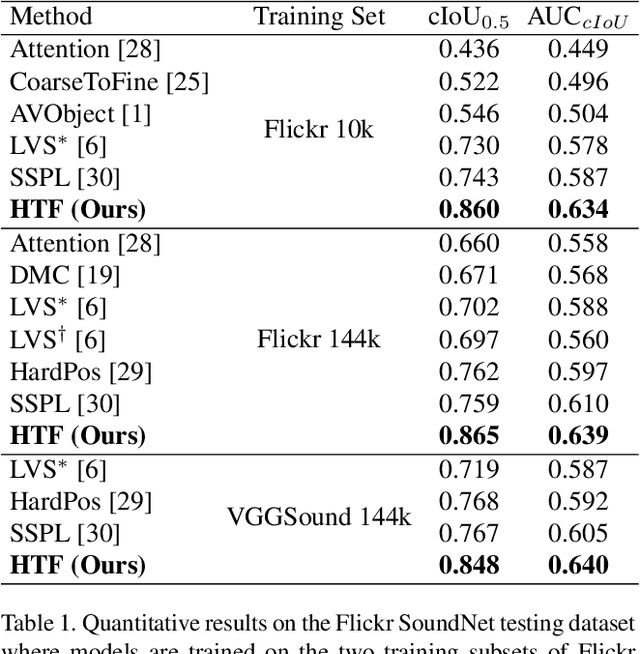
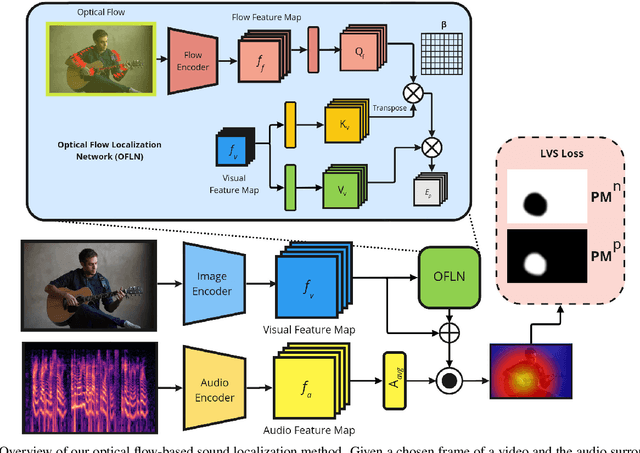
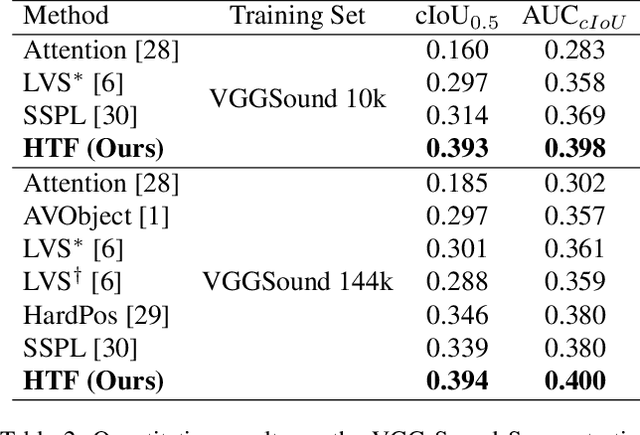
Learning to localize the sound source in videos without explicit annotations is a novel area of audio-visual research. Existing work in this area focuses on creating attention maps to capture the correlation between the two modalities to localize the source of the sound. In a video, oftentimes, the objects exhibiting movement are the ones generating the sound. In this work, we capture this characteristic by modeling the optical flow in a video as a prior to better aid in localizing the sound source. We further demonstrate that the addition of flow-based attention substantially improves visual sound source localization. Finally, we benchmark our method on standard sound source localization datasets and achieve state-of-the-art performance on the Soundnet Flickr and VGG Sound Source datasets. Code: https://github.com/denfed/heartheflow.