 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfusionBench: An Expert-Validated Benchmark for Confusion Recognition and Localization in Educational Videos
Mar 18, 2026Recognizing and localizing student confusion from video is an important yet challenging problem in educational AI. Existing confusion datasets suffer from noisy labels, coarse temporal annotations, and limited expert validation, which hinder reliable fine-grained recognition and temporally grounded analysis. To address these limitations, we propose a practical multi-stage filtering pipeline that integrates two stages of model-assisted screening, researcher curation, and expert validation to build a higher-quality benchmark for confusion understanding. Based on this pipeline, we introduce ConfusionBench, a new benchmark for educational videos consisting of a balanced confusion recognition dataset and a video localization dataset. We further provide zero-shot baseline evaluations of a representative open-source model and a proprietary model on clip-level confusion recognition, long-video confusion localization tasks. Experimental results show that the proprietary model performs better overall but tends to over-predict transitional segments, while the open-source model is more conservative and more prone to missed detections. In addition, the proposed student confusion report visualization can support educational experts in making intervention decisions and adapting learning plans accordingly. All datasets and related materials will be made publicly available on our project page.
InterventionLens: A Multi-Agent Framework for Detecting ASD Intervention Strategies in Parent-Child Shared Reading
Mar 14, 2026Home-based interventions like parent-child shared reading provide a cost-effective approach for supporting children with autism spectrum disorder (ASD). However, analyzing caregiver intervention strategies in naturalistic home interactions typically relies on expert annotation, which is costly, time-intensive, and difficult to scale. To address this challenge, we propose InterventionLens, an end-to-end multi-agent system for automatically detecting and temporally segmenting caregiver intervention strategies from shared reading videos. Without task-specific model training or fine-tuning, InterventionLens uses a collaborative multi-agent architecture to integrate multimodal interaction content and perform fine-grained strategy analysis. Experiments on the ASD-HI dataset show that InterventionLens achieves an overall F1 score of 79.44\%, outperforming the baseline by 19.72\%. These results suggest that InterventionLens is a promising system for analyzing caregiver intervention strategies in home-based ASD shared reading settings. Additional resources will be released on the project page.
MistyPilot: An Agentic Fast-Slow Thinking LLM Framework for Misty Social Robots
Mar 04, 2026With the availability of open APIs in social robots, it has become easier to customize general-purpose tools to meet users' needs. However, interpreting high-level user instructions, selecting and configuring appropriate tools, and executing them reliably remain challenging for users without programming experience. To address these challenges, we introduce MistyPilot, an agentic LLM-driven framework for autonomous tool selection, orchestration, and parameter configuration. MistyPilot comprises two core components: a Physically Interactive Agent (PIA) and a Socially Intelligent Agent (SIA). The PIA enables robust sensor-triggered and tool-driven task execution, while the SIA generates socially intelligent and emotionally aligned dialogue. MistyPilot further integrates a fast-slow thinking paradigm to capture user preferences, reduce latency, and improve task efficiency. To comprehensively evaluate MistyPilot, we contribute five benchmark datasets. Extensive experiments demonstrate the effectiveness of our framework in routing correctness, task completeness, fast-slow thinking retrieval efficiency, tool scalability,and emotion alignment. All code, datasets, and experimental videos will be made publicly available on the project webpage.
LLM Augmented Intervenable Multimodal Adaptor for Post-operative Complication Prediction in Lung Cancer Surgery
Jan 20, 2026Postoperative complications remain a critical concern in clinical practice, adversely affecting patient outcomes and contributing to rising healthcare costs. We present MIRACLE, a deep learning architecture for prediction of risk of postoperative complications in lung cancer surgery by integrating preoperative clinical and radiological data. MIRACLE employs a hyperspherical embedding space fusion of heterogeneous inputs, enabling the extraction of robust, discriminative features from both structured clinical records and high-dimensional radiological images. To enhance transparency of prediction and clinical utility, we incorporate an interventional deep learning module in MIRACLE, that not only refines predictions but also provides interpretable and actionable insights, allowing domain experts to interactively adjust recommendations based on clinical expertise. We validate our approach on POC-L, a real-world dataset comprising 3,094 lung cancer patients who underwent surgery at Roswell Park Comprehensive Cancer Center. Our results demonstrate that MIRACLE outperforms various traditional machine learning models and contemporary large language models (LLM) variants alone, for personalized and explainable postoperative risk management.
AutoMisty: A Multi-Agent LLM Framework for Automated Code Generation in the Misty Social Robot
Mar 09, 2025The social robot's open API allows users to customize open-domain interactions. However, it remains inaccessible to those without programming experience. In this work, we introduce AutoMisty, the first multi-agent collaboration framework powered by large language models (LLMs), to enable the seamless generation of executable Misty robot code from natural language instructions. AutoMisty incorporates four specialized agent modules to manage task decomposition, assignment, problem-solving, and result synthesis. Each agent incorporates a two-layer optimization mechanism, with self-reflection for iterative refinement and human-in-the-loop for better alignment with user preferences. AutoMisty ensures a transparent reasoning process, allowing users to iteratively refine tasks through natural language feedback for precise execution. To evaluate AutoMisty's effectiveness, we designed a benchmark task set spanning four levels of complexity and conducted experiments in a real Misty robot environment. Extensive evaluations demonstrate that AutoMisty not only consistently generates high-quality code but also enables precise code control, significantly outperforming direct reasoning with ChatGPT-4o and ChatGPT-o1. All code, optimized APIs, and experimental videos will be publicly released through the webpage: https://wangxiaoshawn.github.io/AutoMisty.html
SCOT: Self-Supervised Contrastive Pretraining For Zero-Shot Compositional Retrieval
Jan 12, 2025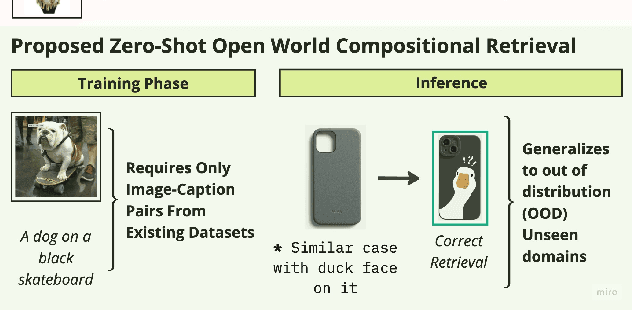
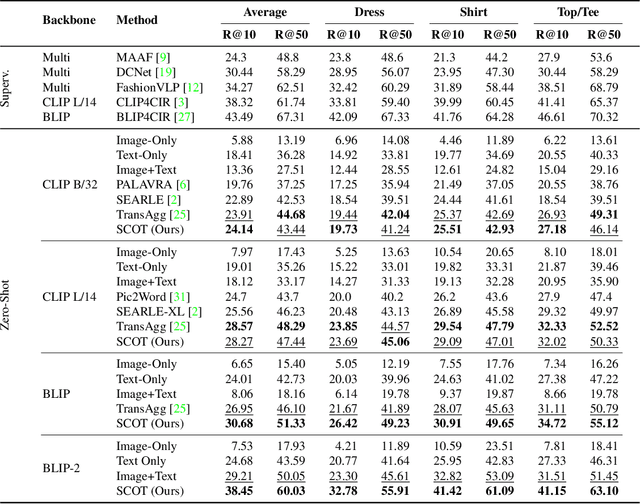
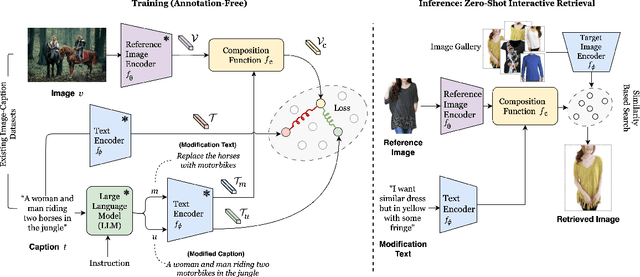
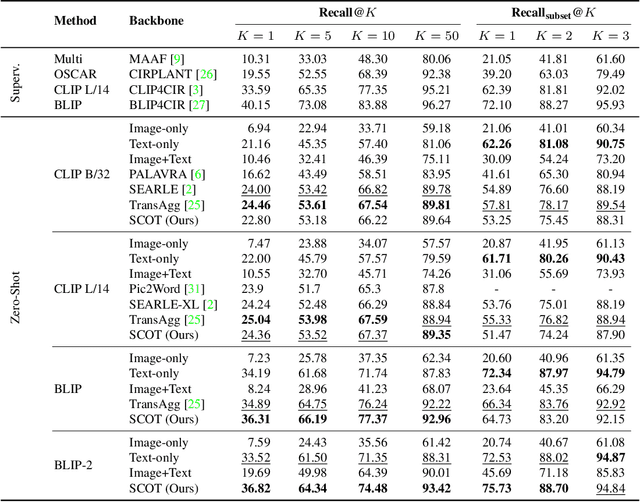
Compositional image retrieval (CIR) is a multimodal learning task where a model combines a query image with a user-provided text modification to retrieve a target image. CIR finds applications in a variety of domains including product retrieval (e-commerce) and web search. Existing methods primarily focus on fully-supervised learning, wherein models are trained on datasets of labeled triplets such as FashionIQ and CIRR. This poses two significant challenges: (i) curating such triplet datasets is labor intensive; and (ii) models lack generalization to unseen objects and domains. In this work, we propose SCOT (Self-supervised COmpositional Training), a novel zero-shot compositional pretraining strategy that combines existing large image-text pair datasets with the generative capabilities of large language models to contrastively train an embedding composition network. Specifically, we show that the text embedding from a large-scale contrastively-pretrained vision-language model can be utilized as proxy target supervision during compositional pretraining, replacing the target image embedding. In zero-shot settings, this strategy surpasses SOTA zero-shot compositional retrieval methods as well as many fully-supervised methods on standard benchmarks such as FashionIQ and CIRR.
Ig3D: Integrating 3D Face Representations in Facial Expression Inference
Aug 29, 2024Reconstructing 3D faces with facial geometry from single images has allowed for major advances in animation, generative models, and virtual reality. However, this ability to represent faces with their 3D features is not as fully explored by the facial expression inference (FEI) community. This study therefore aims to investigate the impacts of integrating such 3D representations into the FEI task, specifically for facial expression classification and face-based valence-arousal (VA) estimation. To accomplish this, we first assess the performance of two 3D face representations (both based on the 3D morphable model, FLAME) for the FEI tasks. We further explore two fusion architectures, intermediate fusion and late fusion, for integrating the 3D face representations with existing 2D inference frameworks. To evaluate our proposed architecture, we extract the corresponding 3D representations and perform extensive tests on the AffectNet and RAF-DB datasets. Our experimental results demonstrate that our proposed method outperforms the state-of-the-art AffectNet VA estimation and RAF-DB classification tasks. Moreover, our method can act as a complement to other existing methods to boost performance in many emotion inference tasks.
Audio Match Cutting: Finding and Creating Matching Audio Transitions in Movies and Videos
Aug 20, 2024A "match cut" is a common video editing technique where a pair of shots that have a similar composition transition fluidly from one to another. Although match cuts are often visual, certain match cuts involve the fluid transition of audio, where sounds from different sources merge into one indistinguishable transition between two shots. In this paper, we explore the ability to automatically find and create "audio match cuts" within videos and movies. We create a self-supervised audio representation for audio match cutting and develop a coarse-to-fine audio match pipeline that recommends matching shots and creates the blended audio. We further annotate a dataset for the proposed audio match cut task and compare the ability of multiple audio representations to find audio match cut candidates. Finally, we evaluate multiple methods to blend two matching audio candidates with the goal of creating a smooth transition. Project page and examples are available at: https://denfed.github.io/audiomatchcut/
Fine-Grained Engine Fault Sound Event Detection Using Multimodal Signals
Mar 16, 2024Sound event detection (SED) is an active area of audio research that aims to detect the temporal occurrence of sounds. In this paper, we apply SED to engine fault detection by introducing a multimodal SED framework that detects fine-grained engine faults of automobile engines using audio and accelerometer-recorded vibration. We first introduce the problem of engine fault SED on a dataset collected from a large variety of vehicles with expertly-labeled engine fault sound events. Next, we propose a SED model to temporally detect ten fine-grained engine faults that occur within vehicle engines and further explore a pretraining strategy using a large-scale weakly-labeled engine fault dataset. Through multiple evaluations, we show our proposed framework is able to effectively detect engine fault sound events. Finally, we investigate the interaction and characteristics of each modality and show that fusing features from audio and vibration improves overall engine fault SED capabilities.
Liveness Detection Competition -- Noncontact-based Fingerprint Algorithms and Systems (LivDet-2023 Noncontact Fingerprint)
Oct 01, 2023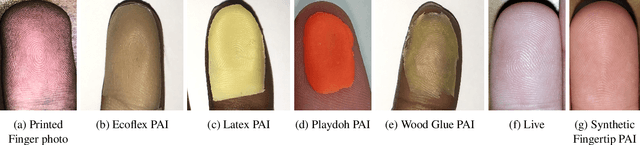


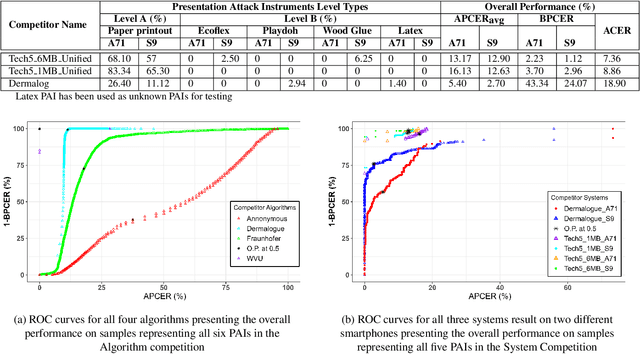
Liveness Detection (LivDet) is an international competition series open to academia and industry with the objec-tive to assess and report state-of-the-art in Presentation Attack Detection (PAD). LivDet-2023 Noncontact Fingerprint is the first edition of the noncontact fingerprint-based PAD competition for algorithms and systems. The competition serves as an important benchmark in noncontact-based fingerprint PAD, offering (a) independent assessment of the state-of-the-art in noncontact-based fingerprint PAD for algorithms and systems, and (b) common evaluation protocol, which includes finger photos of a variety of Presentation Attack Instruments (PAIs) and live fingers to the biometric research community (c) provides standard algorithm and system evaluation protocols, along with the comparative analysis of state-of-the-art algorithms from academia and industry with both old and new android smartphones. The winning algorithm achieved an APCER of 11.35% averaged overall PAIs and a BPCER of 0.62%. The winning system achieved an APCER of 13.0.4%, averaged over all PAIs tested over all the smartphones, and a BPCER of 1.68% over all smartphones tested. Four-finger systems that make individual finger-based PAD decisions were also tested. The dataset used for competition will be available 1 to all researchers as per data share protocol