 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Augmented Intervenable Multimodal Adaptor for Post-operative Complication Prediction in Lung Cancer Surgery
Jan 20, 2026Postoperative complications remain a critical concern in clinical practice, adversely affecting patient outcomes and contributing to rising healthcare costs. We present MIRACLE, a deep learning architecture for prediction of risk of postoperative complications in lung cancer surgery by integrating preoperative clinical and radiological data. MIRACLE employs a hyperspherical embedding space fusion of heterogeneous inputs, enabling the extraction of robust, discriminative features from both structured clinical records and high-dimensional radiological images. To enhance transparency of prediction and clinical utility, we incorporate an interventional deep learning module in MIRACLE, that not only refines predictions but also provides interpretable and actionable insights, allowing domain experts to interactively adjust recommendations based on clinical expertise. We validate our approach on POC-L, a real-world dataset comprising 3,094 lung cancer patients who underwent surgery at Roswell Park Comprehensive Cancer Center. Our results demonstrate that MIRACLE outperforms various traditional machine learning models and contemporary large language models (LLM) variants alone, for personalized and explainable postoperative risk management.
RealCQA: Scientific Chart Question Answering as a Test-bed for First-Order Logic
Aug 03, 2023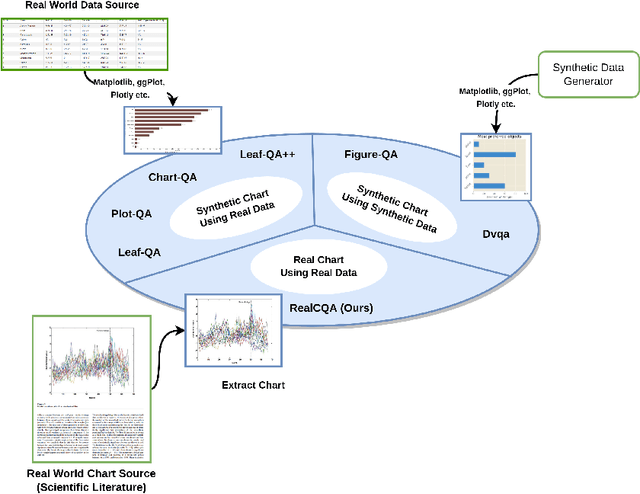
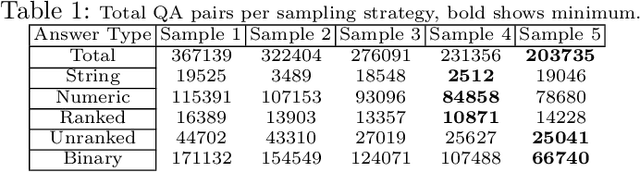

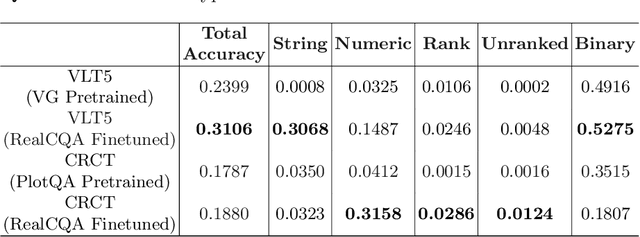
We present a comprehensive study of chart visual question-answering(QA) task, to address the challenges faced in comprehending and extracting data from chart visualizations within documents. Despite efforts to tackle this problem using synthetic charts, solutions are limited by the shortage of annotated real-world data. To fill this gap, we introduce a benchmark and dataset for chart visual QA on real-world charts, offering a systematic analysis of the task and a novel taxonomy for template-based chart question creation. Our contribution includes the introduction of a new answer type, 'list', with both ranked and unranked variations. Our study is conducted on a real-world chart dataset from scientific literature, showcasing higher visual complexity compared to other works. Our focus is on template-based QA and how it can serve as a standard for evaluating the first-order logic capabilities of models. The results of our experiments, conducted on a real-world out-of-distribution dataset, provide a robust evaluation of large-scale pre-trained models and advance the field of chart visual QA and formal logic verification for neural networks in general.
Delivery Issues Identification from Customer Feedback Data
Dec 26, 2021



Millions of packages are delivered successfully by online and local retail stores across the world every day. The proper delivery of packages is needed to ensure high customer satisfaction and repeat purchases. These deliveries suffer various problems despite the best efforts from the stores. These issues happen not only due to the large volume and high demand for low turnaround time but also due to mechanical operations and natural factors. These issues range from receiving wrong items in the package to delayed shipment to damaged packages because of mishandling during transportation. Finding solutions to various delivery issues faced by both sending and receiving parties plays a vital role in increasing the efficiency of the entire process. This paper shows how to find these issues using customer feedback from the text comments and uploaded images. We used transfer learning for both Text and Image models to minimize the demand for thousands of labeled examples. The results show that the model can find different issues. Furthermore, it can also be used for tasks like bottleneck identification, process improvement, automating refunds, etc. Compared with the existing process, the ensemble of text and image models proposed in this paper ensures the identification of several types of delivery issues, which is more suitable for the real-life scenarios of delivery of items in retail businesses. This method can supply a new idea of issue detection for the delivery of packages in similar industries.
Unsupervised paradigm for information extraction from transcripts using BERT
Oct 09, 2021
Audio call transcripts are one of the valuable sources of information for multiple downstream use cases such as understanding the voice of the customer and analyzing agent performance. However, these transcripts are noisy in nature and in an industry setting, getting tagged ground truth data is a challenge. In this paper, we present a solution implemented in the industry using BERT Language Models as part of our pipeline to extract key topics and multiple open intents discussed in the call. Another problem statement we looked at was the automatic tagging of transcripts into predefined categories, which traditionally is solved using supervised approach. To overcome the lack of tagged data, all our proposed approaches use unsupervised methods to solve the outlined problems. We evaluate the results by quantitatively comparing the automatically extracted topics, intents and tagged categories with human tagged ground truth and by qualitatively measuring the valuable concepts and intents that are not present in the ground truth. We achieved near human accuracy in extraction of these topics and intents using our novel approach