 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOT: Self-Supervised Contrastive Pretraining For Zero-Shot Compositional Retrieval
Jan 12, 2025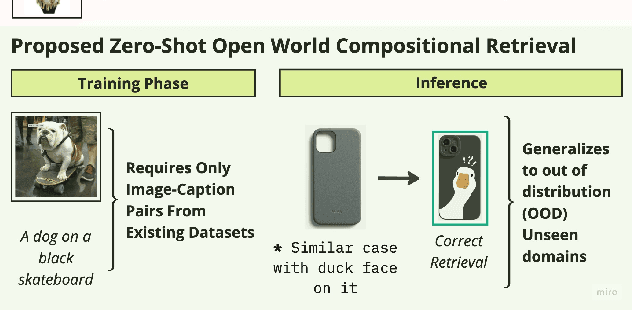
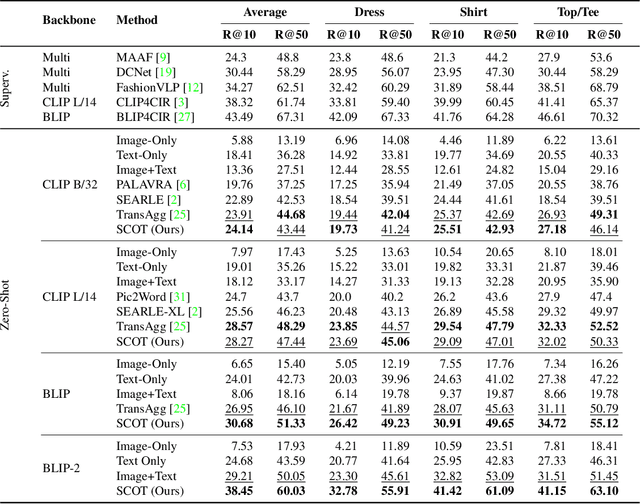
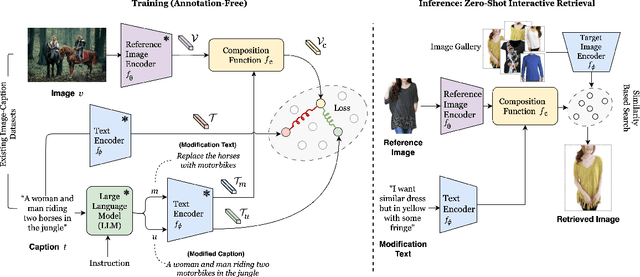
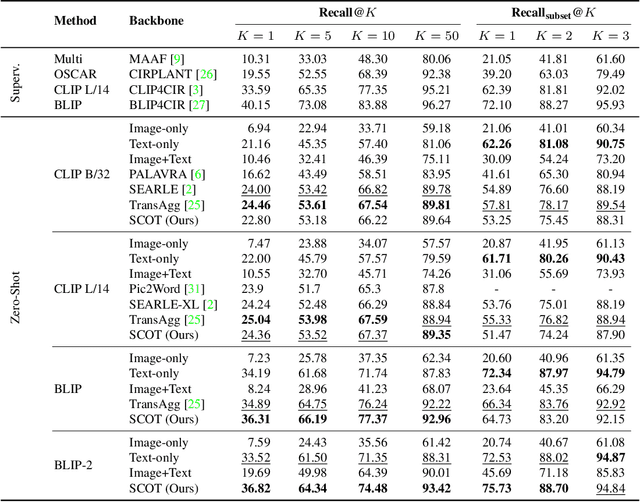
Compositional image retrieval (CIR) is a multimodal learning task where a model combines a query image with a user-provided text modification to retrieve a target image. CIR finds applications in a variety of domains including product retrieval (e-commerce) and web search. Existing methods primarily focus on fully-supervised learning, wherein models are trained on datasets of labeled triplets such as FashionIQ and CIRR. This poses two significant challenges: (i) curating such triplet datasets is labor intensive; and (ii) models lack generalization to unseen objects and domains. In this work, we propose SCOT (Self-supervised COmpositional Training), a novel zero-shot compositional pretraining strategy that combines existing large image-text pair datasets with the generative capabilities of large language models to contrastively train an embedding composition network. Specifically, we show that the text embedding from a large-scale contrastively-pretrained vision-language model can be utilized as proxy target supervision during compositional pretraining, replacing the target image embedding. In zero-shot settings, this strategy surpasses SOTA zero-shot compositional retrieval methods as well as many fully-supervised methods on standard benchmarks such as FashionIQ and CIRR.
Salient Object-Aware Background Generation using Text-Guided Diffusion Models
Apr 15, 2024Generating background scenes for salient objects plays a crucial role across various domains including creative design and e-commerce, as it enhances the presentation and context of subjects by integrating them into tailored environments. Background generation can be framed as a task of text-conditioned outpainting, where the goal is to extend image content beyond a salient object's boundaries on a blank background. Although popular diffusion models for text-guided inpainting can also be used for outpainting by mask inversion, they are trained to fill in missing parts of an image rather than to place an object into a scene. Consequently, when used for background creation, inpainting models frequently extend the salient object's boundaries and thereby change the object's identity, which is a phenomenon we call "object expansion." This paper introduces a model for adapting inpainting diffusion models to the salient object outpainting task using Stable Diffusion and ControlNet architectures. We present a series of qualitative and quantitative results across models and datasets, including a newly proposed metric to measure object expansion that does not require any human labeling. Compared to Stable Diffusion 2.0 Inpainting, our proposed approach reduces object expansion by 3.6x on average with no degradation in standard visual metrics across multiple datasets.
Staging E-Commerce Products for Online Advertising using Retrieval Assisted Image Generation
Jul 28, 2023

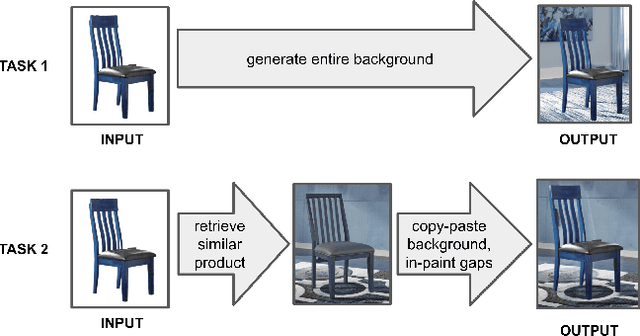

Online ads showing e-commerce products typically rely on the product images in a catalog sent to the advertising platform by an e-commerce platform. In the broader ads industry such ads are called dynamic product ads (DPA). It is common for DPA catalogs to be in the scale of millions (corresponding to the scale of products which can be bought from the e-commerce platform). However, not all product images in the catalog may be appealing when directly re-purposed as an ad image, and this may lead to lower click-through rates (CTRs). In particular, products just placed against a solid background may not be as enticing and realistic as a product staged in a natural environment. To address such shortcomings of DPA images at scale, we propose a generative adversarial network (GAN) based approach to generate staged backgrounds for un-staged product images. Generating the entire staged background is a challenging task susceptible to hallucinations. To get around this, we introduce a simpler approach called copy-paste staging using retrieval assisted GANs. In copy paste staging, we first retrieve (from the catalog) staged products similar to the un-staged input product, and then copy-paste the background of the retrieved product in the input image. A GAN based in-painting model is used to fill the holes left after this copy-paste operation. We show the efficacy of our copy-paste staging method via offline metrics, and human evaluation. In addition, we show how our staging approach can enable animations of moving products leading to a video ad from a product image.
Detecting Sarcasm in Multimodal Social Platforms
Aug 08, 2016

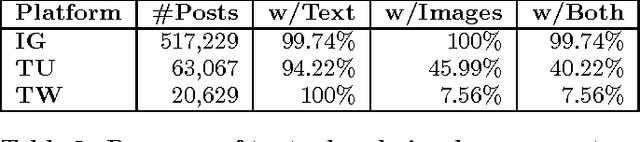

Sarcasm is a peculiar form of sentiment expression, where the surface sentiment differs from the implied sentiment. The detection of sarcasm in social media platforms has been applied in the past mainly to textual utterances where lexical indicators (such as interjections and intensifiers), linguistic markers, and contextual information (such as user profiles, or past conversations) were used to detect the sarcastic tone. However, modern social media platforms allow to create multimodal messages where audiovisual content is integrated with the text, making the analysis of a mode in isolation partial. In our work, we first study the relationship between the textual and visual aspects in multimodal posts from three major social media platforms, i.e., Instagram, Tumblr and Twitter, and we run a crowdsourcing task to quantify the extent to which images are perceived as necessary by human annotators. Moreover, we propose two different computational frameworks to detect sarcasm that integrate the textual and visual modalities. The first approach exploits visual semantics trained on an external dataset, and concatenates the semantics features with state-of-the-art textual features. The second method adapts a visual neural network initialized with parameters trained on ImageNet to multimodal sarcastic posts. Results show the positive effect of combining modalities for the detection of sarcasm across platforms and methods.
Humor in Collective Discourse: Unsupervised Funniness Detection in the New Yorker Cartoon Caption Contest
Jun 26, 2015
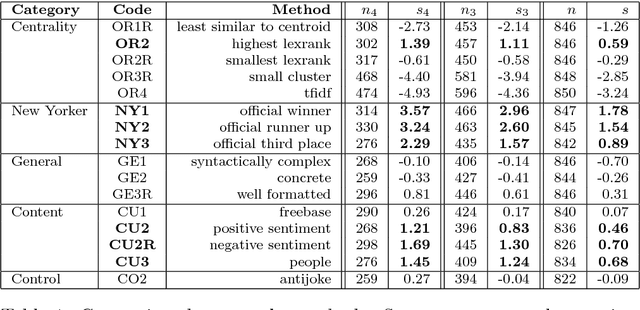


The New Yorker publishes a weekly captionless cartoon. More than 5,000 readers submit captions for it. The editors select three of them and ask the readers to pick the funniest one. We describe an experiment that compares a dozen automatic methods for selecting the funniest caption. We show that negative sentiment, human-centeredness, and lexical centrality most strongly match the funniest captions, followed by positive sentiment. These results are useful for understanding humor and also in the design of more engaging conversational agents in text and multimodal (vision+text) systems. As part of this work, a large set of cartoons and captions is being made available to the community.