 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Reindex-Then-Adapt: Improving Large Language Models for Conversational Recommendation
May 20, 2024Large language models (LLMs) are revolutionizing conversational recommender systems by adeptly indexing item content, understanding complex conversational contexts, and generating relevant item titles. However, controlling the distribution of recommended items remains a challenge. This leads to suboptimal performance due to the failure to capture rapidly changing data distributions, such as item popularity, on targeted conversational recommendation platforms. In conversational recommendation, LLMs recommend items by generating the titles (as multiple tokens) autoregressively, making it difficult to obtain and control the recommendations over all items. Thus, we propose a Reindex-Then-Adapt (RTA) framework, which converts multi-token item titles into single tokens within LLMs, and then adjusts the probability distributions over these single-token item titles accordingly. The RTA framework marries the benefits of both LLMs and traditional recommender systems (RecSys): understanding complex queries as LLMs do; while efficiently controlling the recommended item distributions in conversational recommendations as traditional RecSys do. Our framework demonstrates improved accuracy metrics across three different conversational recommendation datasets and two adaptation settings
Large Language Models as Zero-Shot Conversational Recommenders
Aug 19, 2023



In this paper, we present empirical studies on conversational recommendation tasks using representative large language models in a zero-shot setting with three primary contributions. (1) Data: To gain insights into model behavior in "in-the-wild" conversational recommendation scenarios, we construct a new dataset of recommendation-related conversations by scraping a popular discussion website. This is the largest public real-world conversational recommendation dataset to date. (2) Evaluation: On the new dataset and two existing conversational recommendation datasets, we observe that even without fine-tuning, large language models can outperform existing fine-tuned conversational recommendation models. (3) Analysis: We propose various probing tasks to investigate the mechanisms behind the remarkable performance of large language models in conversational recommendation. We analyze both the large language models' behaviors and the characteristics of the datasets, providing a holistic understanding of the models' effectiveness, limitations and suggesting directions for the design of future conversational recommenders
QMSum: A New Benchmark for Query-based Multi-domain Meeting Summarization
Apr 13, 2021
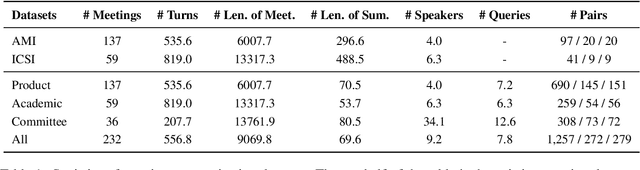
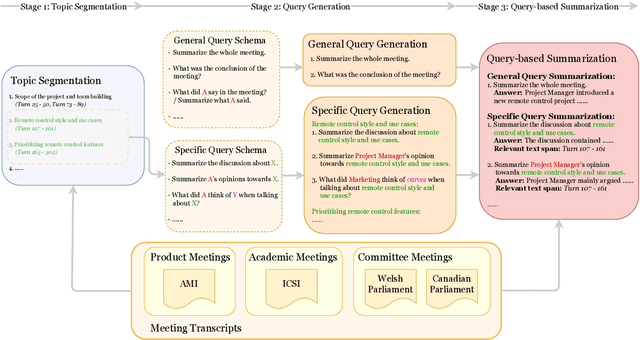
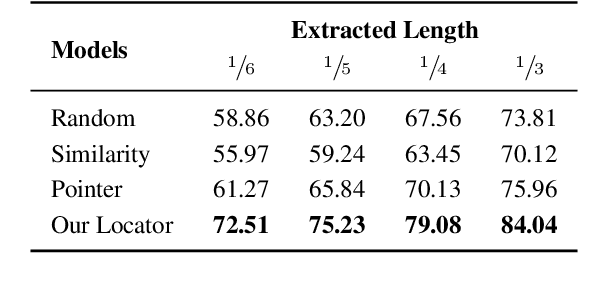
Meetings are a key component of human collaboration. As increasing numbers of meetings are recorded and transcribed, meeting summaries have become essential to remind those who may or may not have attended the meetings about the key decisions made and the tasks to be completed. However, it is hard to create a single short summary that covers all the content of a long meeting involving multiple people and topics. In order to satisfy the needs of different types of users, we define a new query-based multi-domain meeting summarization task, where models have to select and summarize relevant spans of meetings in response to a query, and we introduce QMSum, a new benchmark for this task. QMSum consists of 1,808 query-summary pairs over 232 meetings in multiple domains. Besides, we investigate a locate-then-summarize method and evaluate a set of strong summarization baselines on the task. Experimental results and manual analysis reveal that QMSum presents significant challenges in long meeting summarization for future research. Dataset is available at \url{https://github.com/Yale-LILY/QMSum}.
Go Figure! A Meta Evaluation of Factuality in Summarization
Oct 24, 2020

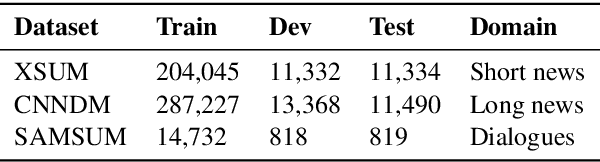
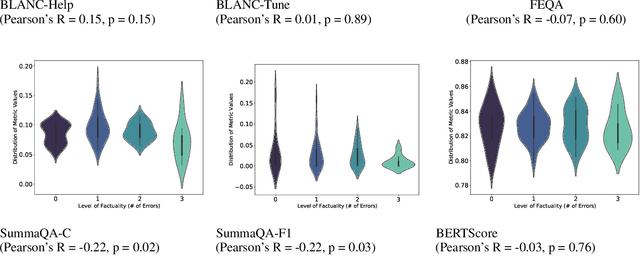
Text generation models can generate factually inconsistent text containing distorted or fabricated facts about the source text. Recent work has focused on building evaluation models to verify the factual correctness of semantically constrained text generation tasks such as document summarization. While the field of factuality evaluation is growing fast, we don't have well-defined criteria for measuring the effectiveness, generalizability, reliability, or sensitivity of the factuality metrics. Focusing on these aspects, in this paper, we introduce a meta-evaluation framework for evaluating factual consistency metrics. We introduce five necessary, common-sense conditions for effective factuality metrics and experiment with nine recent factuality metrics using synthetic and human-labeled factuality data from short news, long news and dialogue summarization domains. Our framework enables assessing the efficiency of any new factual consistency metric on a variety of dimensions over multiple summarization domains and can be easily extended with new meta-evaluation criteria. We also present our conclusions towards standardizing the factuality evaluation metrics.
Artemis: A Novel Annotation Methodology for Indicative Single Document Summarization
May 14, 2020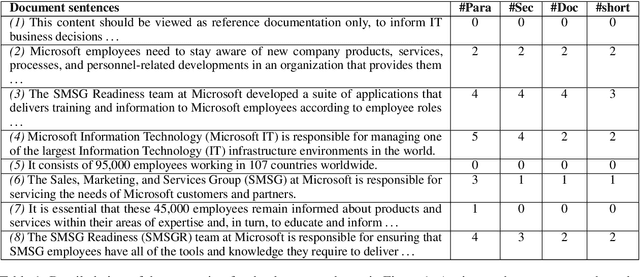
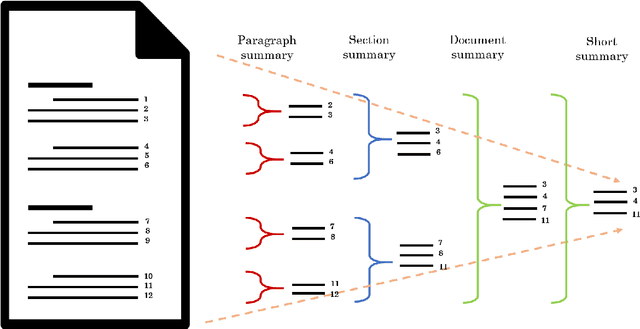
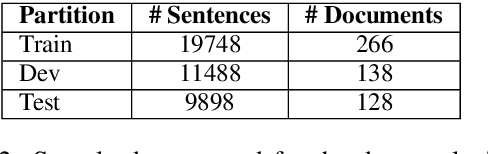

We describe Artemis (Annotation methodology for Rich, Tractable, Extractive, Multi-domain, Indicative Summarization), a novel hierarchical annotation process that produces indicative summaries for documents from multiple domains. Current summarization evaluation datasets are single-domain and focused on a few domains for which naturally occurring summaries can be easily found, such as news and scientific articles. These are not sufficient for training and evaluation of summarization models for use in document management and information retrieval systems, which need to deal with documents from multiple domains. Compared to other annotation methods such as Relative Utility and Pyramid, Artemis is more tractable because judges don't need to look at all the sentences in a document when making an importance judgment for one of the sentences, while providing similarly rich sentence importance annotations. We describe the annotation process in detail and compare it with other similar evaluation systems. We also present analysis and experimental results over a sample set of 532 annotated documents.
AREDSUM: Adaptive Redundancy-Aware Iterative Sentence Ranking for Extractive Document Summarization
Apr 13, 2020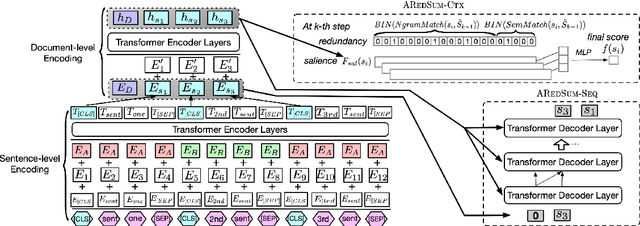
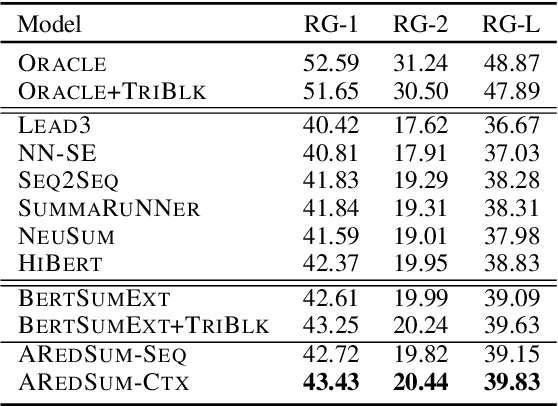
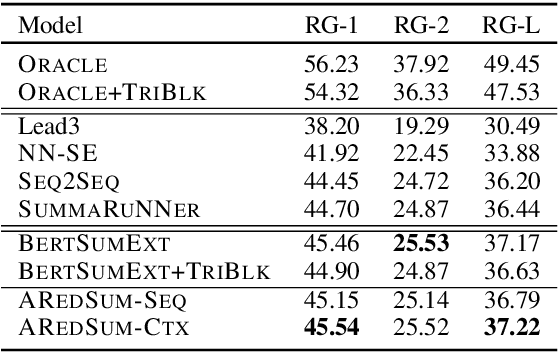
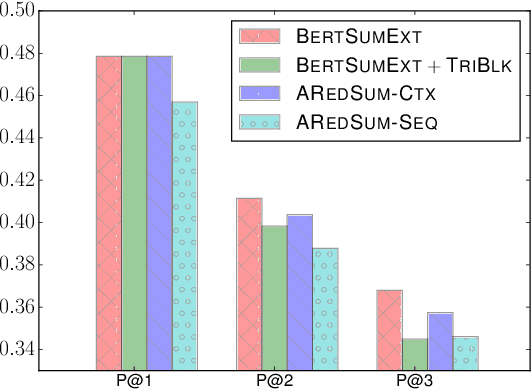
Redundancy-aware extractive summarization systems score the redundancy of the sentences to be included in a summary either jointly with their salience information or separately as an additional sentence scoring step. Previous work shows the efficacy of jointly scoring and selecting sentences with neural sequence generation models. It is, however, not well-understood if the gain is due to better encoding techniques or better redundancy reduction approaches. Similarly, the contribution of salience versus diversity components on the created summary is not studied well. Building on the state-of-the-art encoding methods for summarization, we present two adaptive learning models: AREDSUM-SEQ that jointly considers salience and novelty during sentence selection; and a two-step AREDSUM-CTX that scores salience first, then learns to balance salience and redundancy, enabling the measurement of the impact of each aspect. Empirical results on CNN/DailyMail and NYT50 datasets show that by modeling diversity explicitly in a separate step, AREDSUM-CTX achieves significantly better performance than AREDSUM-SEQ as well as state-of-the-art extractive summarization baselines.
Zero-Shot Adaptive Transfer for Conversational Language Understanding
Aug 29, 2018

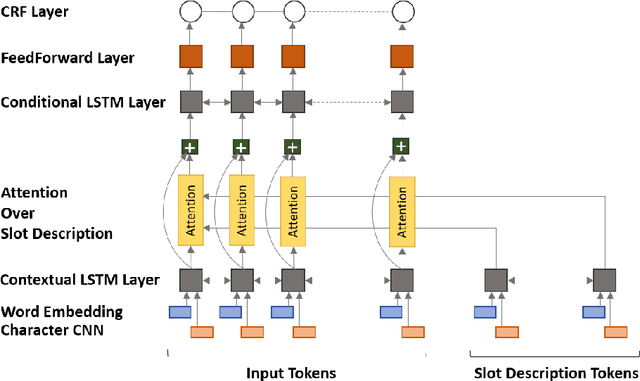
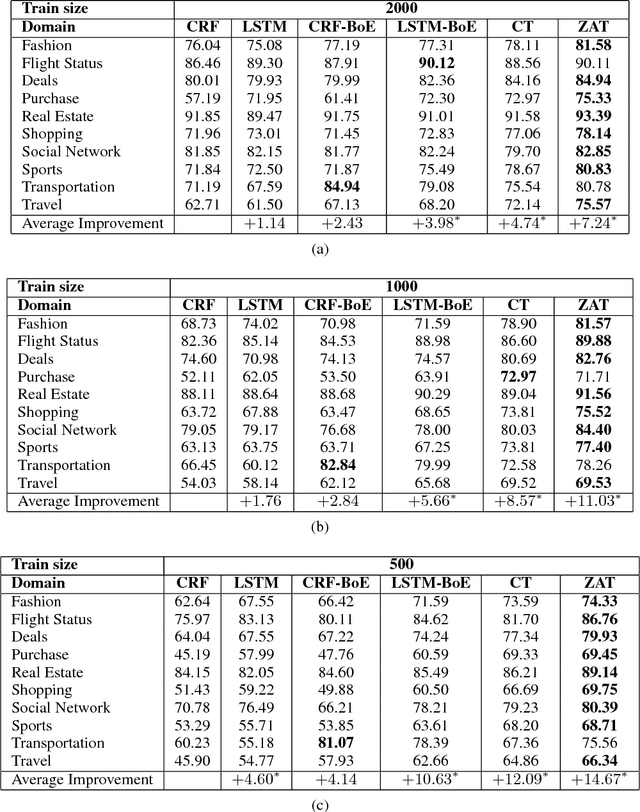
Conversational agents such as Alexa and Google Assistant constantly need to increase their language understanding capabilities by adding new domains. A massive amount of labeled data is required for training each new domain. While domain adaptation approaches alleviate the annotation cost, prior approaches suffer from increased training time and suboptimal concept alignments. To tackle this, we introduce a novel Zero-Shot Adaptive Transfer method for slot tagging that utilizes the slot description for transferring reusable concepts across domains, and enjoys efficient training without any explicit concept alignments. Extensive experimentation over a dataset of 10 domains relevant to our commercial personal digital assistant shows that our model outperforms previous state-of-the-art systems by a large margin, and achieves an even higher improvement in the low data regime.
Humor in Collective Discourse: Unsupervised Funniness Detection in the New Yorker Cartoon Caption Contest
Jun 26, 2015
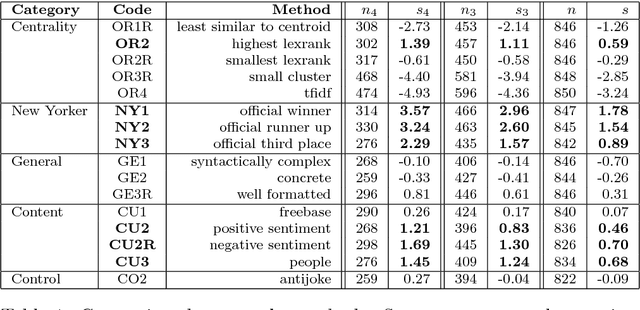


The New Yorker publishes a weekly captionless cartoon. More than 5,000 readers submit captions for it. The editors select three of them and ask the readers to pick the funniest one. We describe an experiment that compares a dozen automatic methods for selecting the funniest caption. We show that negative sentiment, human-centeredness, and lexical centrality most strongly match the funniest captions, followed by positive sentiment. These results are useful for understanding humor and also in the design of more engaging conversational agents in text and multimodal (vision+text) systems. As part of this work, a large set of cartoons and captions is being made available to the community.