 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Retrieval Adaptation using Target Domain Description
Jul 06, 2023



In information retrieval (IR), domain adaptation is the process of adapting a retrieval model to a new domain whose data distribution is different from the source domain. Existing methods in this area focus on unsupervised domain adaptation where they have access to the target document collection or supervised (often few-shot) domain adaptation where they additionally have access to (limited) labeled data in the target domain. There also exists research on improving zero-shot performance of retrieval models with no adaptation. This paper introduces a new category of domain adaptation in IR that is as-yet unexplored. Here, similar to the zero-shot setting, we assume the retrieval model does not have access to the target document collection. In contrast, it does have access to a brief textual description that explains the target domain. We define a taxonomy of domain attributes in retrieval tasks to understand different properties of a source domain that can be adapted to a target domain. We introduce a novel automatic data construction pipeline that produces a synthetic document collection, query set, and pseudo relevance labels, given a textual domain description. Extensive experiments on five diverse target domains show that adapting dense retrieval models using the constructed synthetic data leads to effective retrieval performance on the target domain.
Generalized Weak Supervision for Neural Information Retrieval
Apr 18, 2023



Neural ranking models (NRMs) have demonstrated effective performance in several information retrieval (IR) tasks. However, training NRMs often requires large-scale training data, which is difficult and expensive to obtain. To address this issue, one can train NRMs via weak supervision, where a large dataset is automatically generated using an existing ranking model (called the weak labeler) for training NRMs. Weakly supervised NRMs can generalize from the observed data and significantly outperform the weak labeler. This paper generalizes this idea through an iterative re-labeling process, demonstrating that weakly supervised models can iteratively play the role of weak labeler and significantly improve ranking performance without using manually labeled data. The proposed Generalized Weak Supervision (GWS) solution is generic and orthogonal to the ranking model architecture. This paper offers four implementations of GWS: self-labeling, cross-labeling, joint cross- and self-labeling, and greedy multi-labeling. GWS also benefits from a query importance weighting mechanism based on query performance prediction methods to reduce noise in the generated training data. We further draw a theoretical connection between self-labeling and Expectation-Maximization. Our experiments on two passage retrieval benchmarks suggest that all implementations of GWS lead to substantial improvements compared to weak supervision in all cases.
Evaluating Fairness in Argument Retrieval
Aug 23, 2021
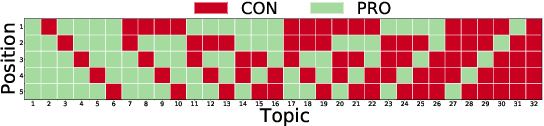
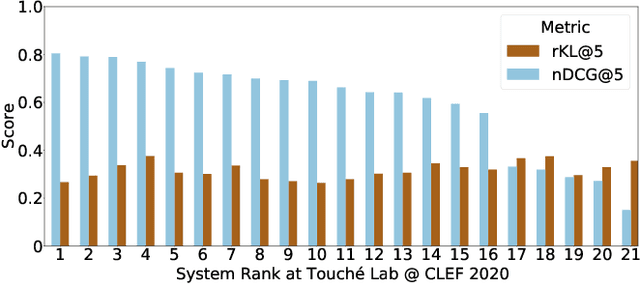

Existing commercial search engines often struggle to represent different perspectives of a search query. Argument retrieval systems address this limitation of search engines and provide both positive (PRO) and negative (CON) perspectives about a user's information need on a controversial topic (e.g., climate change). The effectiveness of such argument retrieval systems is typically evaluated based on topical relevance and argument quality, without taking into account the often differing number of documents shown for the argument stances (PRO or CON). Therefore, systems may retrieve relevant passages, but with a biased exposure of arguments. In this work, we analyze a range of non-stochastic fairness-aware ranking and diversity metrics to evaluate the extent to which argument stances are fairly exposed in argument retrieval systems. Using the official runs of the argument retrieval task Touch\'e at CLEF 2020, as well as synthetic data to control the amount and order of argument stances in the rankings, we show that systems with the best effectiveness in terms of topical relevance are not necessarily the most fair or the most diverse in terms of argument stance. The relationships we found between (un)fairness and diversity metrics shed light on how to evaluate group fairness -- in addition to topical relevance -- in argument retrieval settings.
Asking Clarifying Questions Based on Negative Feedback in Conversational Search
Jul 12, 2021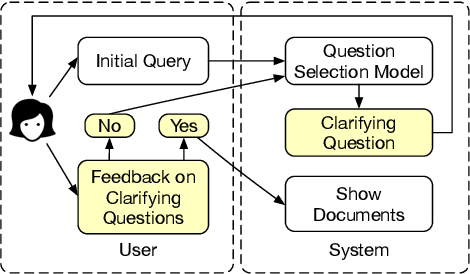
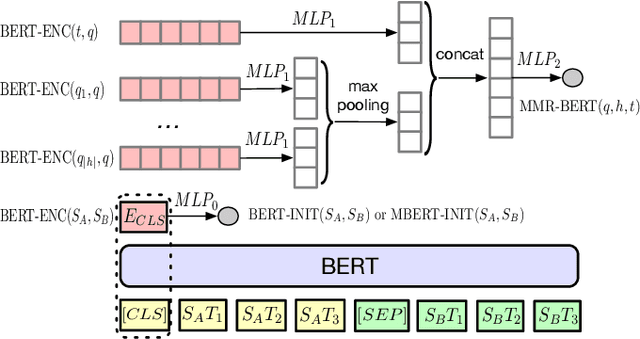
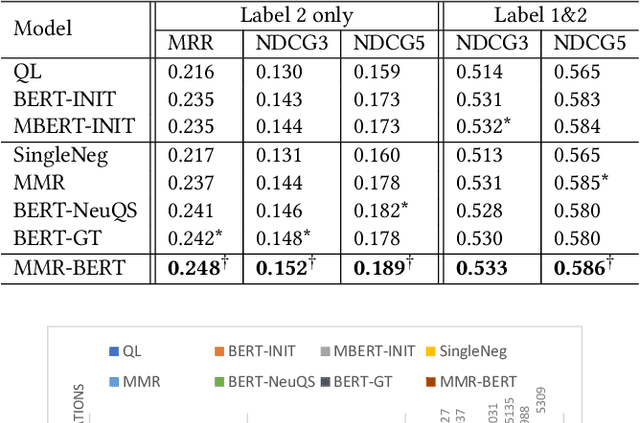
Users often need to look through multiple search result pages or reformulate queries when they have complex information-seeking needs. Conversational search systems make it possible to improve user satisfaction by asking questions to clarify users' search intents. This, however, can take significant effort to answer a series of questions starting with "what/why/how". To quickly identify user intent and reduce effort during interactions, we propose an intent clarification task based on yes/no questions where the system needs to ask the correct question about intents within the fewest conversation turns. In this task, it is essential to use negative feedback about the previous questions in the conversation history. To this end, we propose a Maximum-Marginal-Relevance (MMR) based BERT model (MMR-BERT) to leverage negative feedback based on the MMR principle for the next clarifying question selection. Experiments on the Qulac dataset show that MMR-BERT outperforms state-of-the-art baselines significantly on the intent identification task and the selected questions also achieve significantly better performance in the associated document retrieval tasks.
Passage Retrieval for Outside-Knowledge Visual Question Answering
May 09, 2021

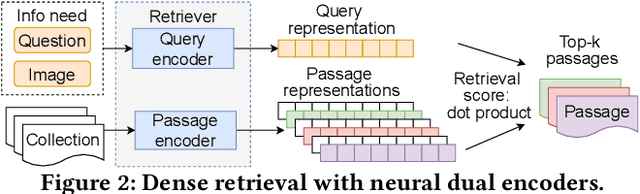
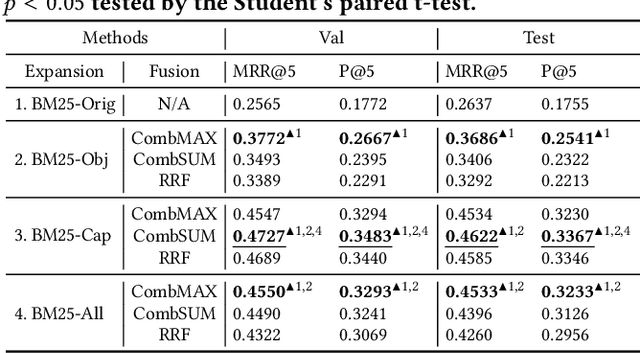
In this work, we address multi-modal information needs that contain text questions and images by focusing on passage retrieval for outside-knowledge visual question answering. This task requires access to outside knowledge, which in our case we define to be a large unstructured passage collection. We first conduct sparse retrieval with BM25 and study expanding the question with object names and image captions. We verify that visual clues play an important role and captions tend to be more informative than object names in sparse retrieval. We then construct a dual-encoder dense retriever, with the query encoder being LXMERT, a multi-modal pre-trained transformer. We further show that dense retrieval significantly outperforms sparse retrieval that uses object expansion. Moreover, dense retrieval matches the performance of sparse retrieval that leverages human-generated captions.
A Neural Passage Model for Ad-hoc Document Retrieval
Mar 16, 2021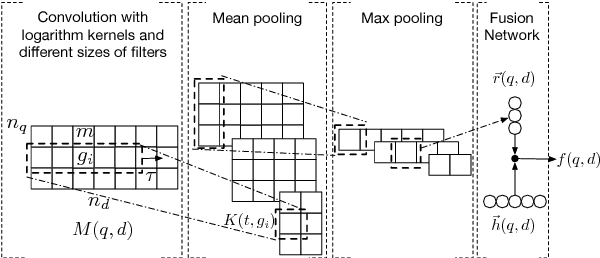
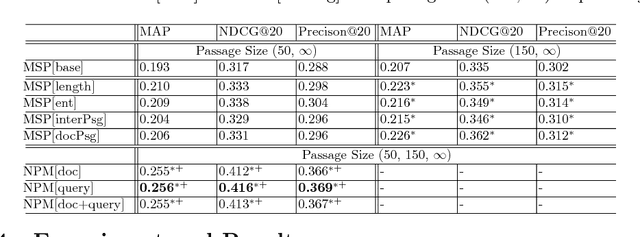
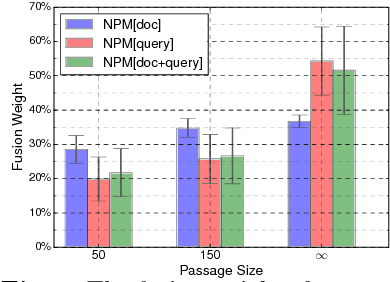
Traditional statistical retrieval models often treat each document as a whole. In many cases, however, a document is relevant to a query only because a small part of it contain the targeted information. In this work, we propose a neural passage model (NPM) that uses passage-level information to improve the performance of ad-hoc retrieval. Instead of using a single window to extract passages, our model automatically learns to weight passages with different granularities in the training process. We show that the passage-based document ranking paradigm from previous studies can be directly derived from our neural framework. Also, our experiments on a TREC collection showed that the NPM can significantly outperform the existing passage-based retrieval models.
Weakly-Supervised Open-Retrieval Conversational Question Answering
Mar 03, 2021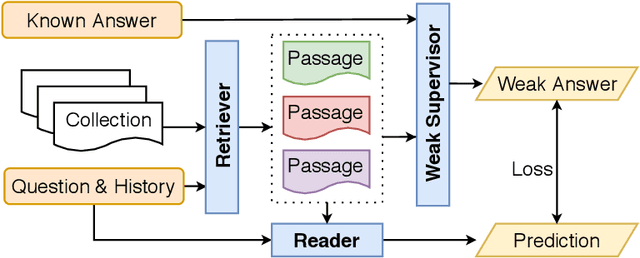
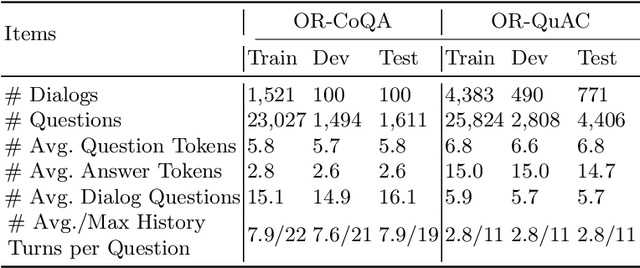
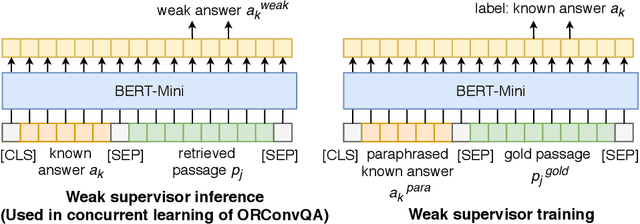
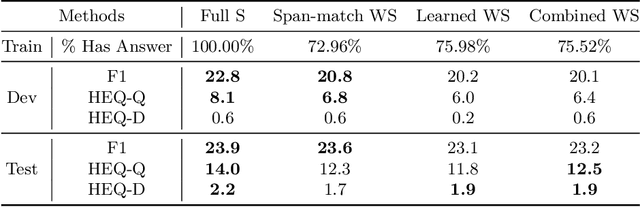
Recent studies on Question Answering (QA) and Conversational QA (ConvQA) emphasize the role of retrieval: a system first retrieves evidence from a large collection and then extracts answers. This open-retrieval ConvQA setting typically assumes that each question is answerable by a single span of text within a particular passage (a span answer). The supervision signal is thus derived from whether or not the system can recover an exact match of this ground-truth answer span from the retrieved passages. This method is referred to as span-match weak supervision. However, information-seeking conversations are challenging for this span-match method since long answers, especially freeform answers, are not necessarily strict spans of any passage. Therefore, we introduce a learned weak supervision approach that can identify a paraphrased span of the known answer in a passage. Our experiments on QuAC and CoQA datasets show that the span-match weak supervisor can only handle conversations with span answers, and has less satisfactory results for freeform answers generated by people. Our method is more flexible as it can handle both span answers and freeform answers. Moreover, our method can be more powerful when combined with the span-match method which shows it is complementary to the span-match method. We also conduct in-depth analyses to show more insights on open-retrieval ConvQA under a weak supervision setting.
Context-Aware Target Apps Selection and Recommendation for Enhancing Personal Mobile Assistants
Jan 09, 2021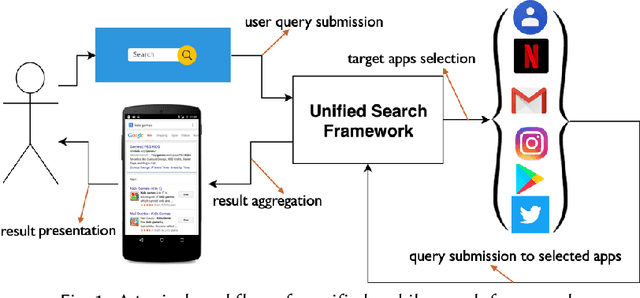
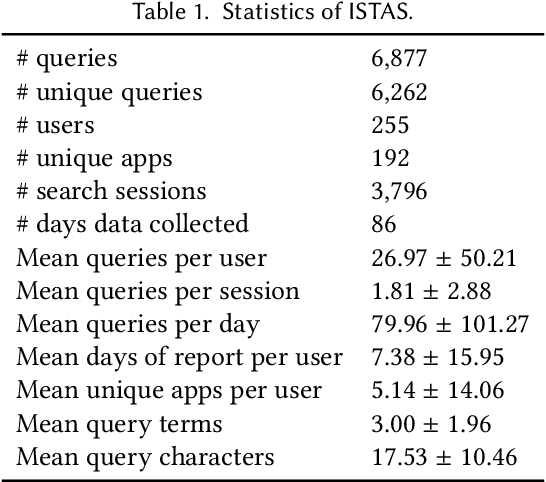
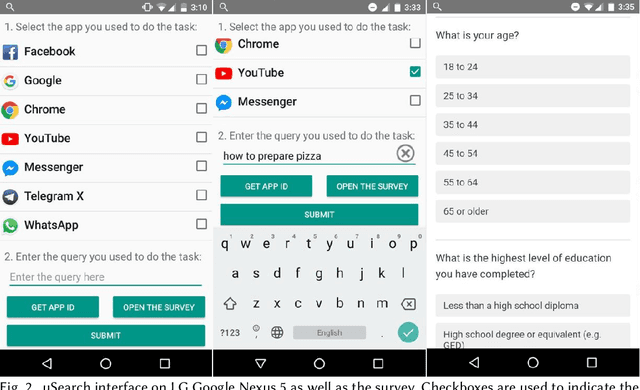
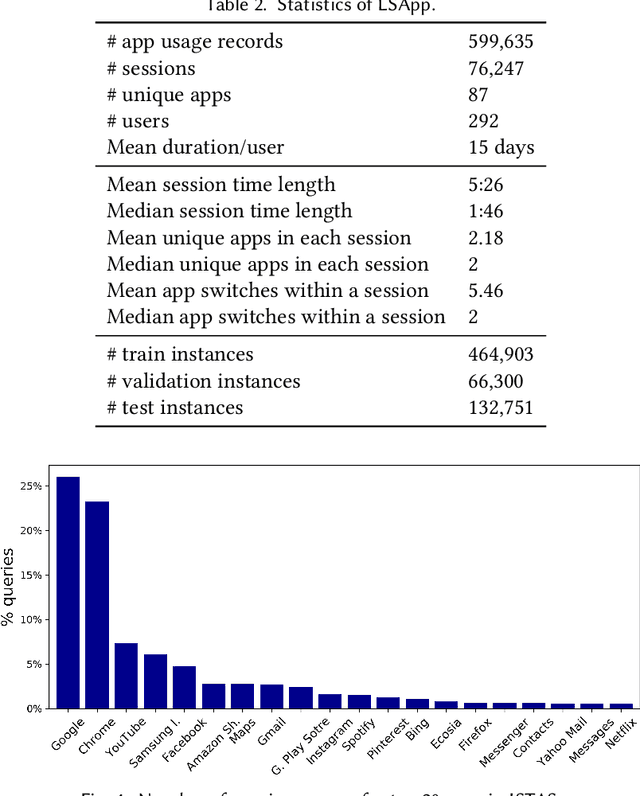
Users install many apps on their smartphones, raising issues related to information overload for users and resource management for devices. Moreover, the recent increase in the use of personal assistants has made mobile devices even more pervasive in users' lives. This paper addresses two research problems that are vital for developing effective personal mobile assistants: target apps selection and recommendation. The former is the key component of a unified mobile search system: a system that addresses the users' information needs for all the apps installed on their devices with a unified mode of access. The latter, instead, predicts the next apps that the users would want to launch. Here we focus on context-aware models to leverage the rich contextual information available to mobile devices. We design an in situ study to collect thousands of mobile queries enriched with mobile sensor data (now publicly available for research purposes). With the aid of this dataset, we study the user behavior in the context of these tasks and propose a family of context-aware neural models that take into account the sequential, temporal, and personal behavior of users. We study several state-of-the-art models and show that the proposed models significantly outperform the baselines.
Guided Transformer: Leveraging Multiple External Sources for Representation Learning in Conversational Search
Jun 13, 2020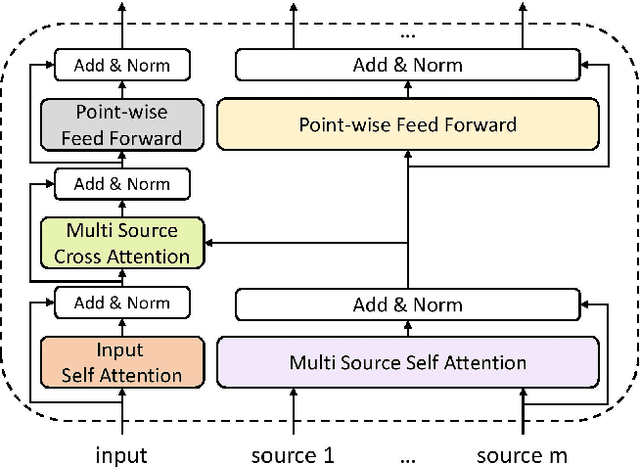
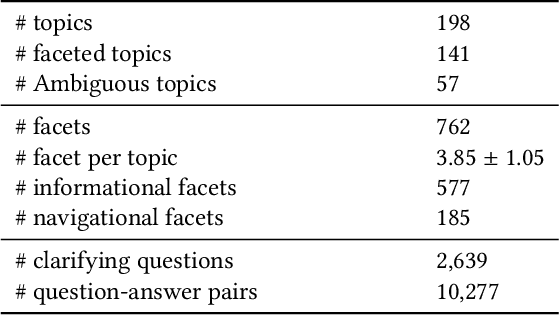
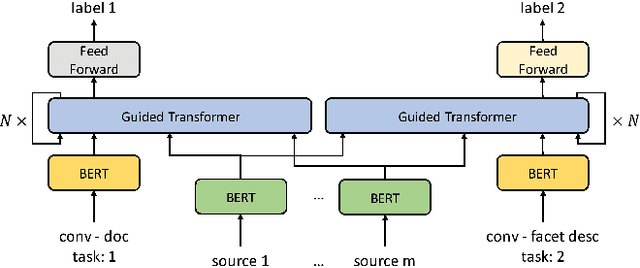
Asking clarifying questions in response to ambiguous or faceted queries has been recognized as a useful technique for various information retrieval systems, especially conversational search systems with limited bandwidth interfaces. Analyzing and generating clarifying questions have been studied recently but the accurate utilization of user responses to clarifying questions has been relatively less explored. In this paper, we enrich the representations learned by Transformer networks using a novel attention mechanism from external information sources that weights each term in the conversation. We evaluate this Guided Transformer model in a conversational search scenario that includes clarifying questions. In our experiments, we use two separate external sources, including the top retrieved documents and a set of different possible clarifying questions for the query. We implement the proposed representation learning model for two downstream tasks in conversational search; document retrieval and next clarifying question selection. Our experiments use a public dataset for search clarification and demonstrate significant improvements compared to competitive baselines.
Open-Retrieval Conversational Question Answering
May 22, 2020
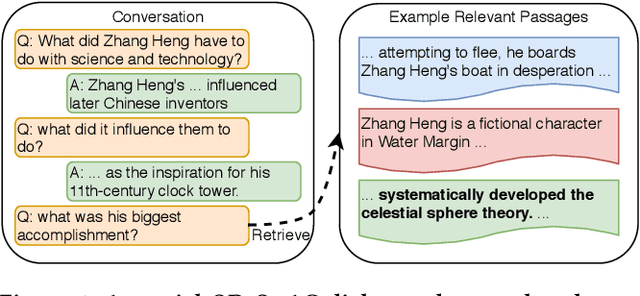
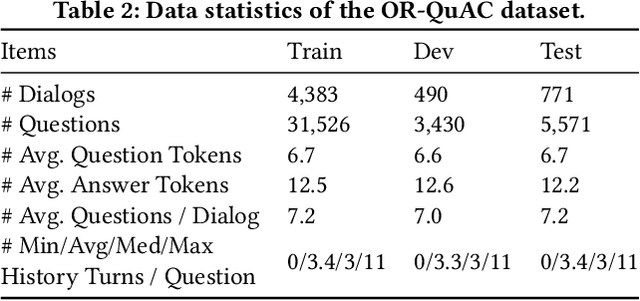
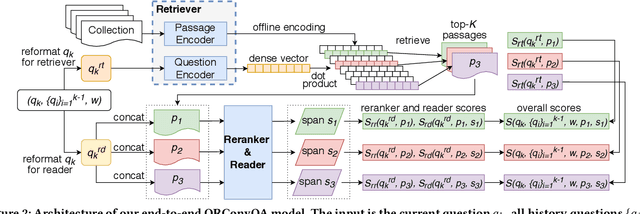
Conversational search is one of the ultimate goals of information retrieval. Recent research approaches conversational search by simplified settings of response ranking and conversational question answering, where an answer is either selected from a given candidate set or extracted from a given passage. These simplifications neglect the fundamental role of retrieval in conversational search. To address this limitation, we introduce an open-retrieval conversational question answering (ORConvQA) setting, where we learn to retrieve evidence from a large collection before extracting answers, as a further step towards building functional conversational search systems. We create a dataset, OR-QuAC, to facilitate research on ORConvQA. We build an end-to-end system for ORConvQA, featuring a retriever, a reranker, and a reader that are all based on Transformers. Our extensive experiments on OR-QuAC demonstrate that a learnable retriever is crucial for ORConvQA. We further show that our system can make a substantial improvement when we enable history modeling in all system components. Moreover, we show that the reranker component contributes to the model performance by providing a regularization effect. Finally, further in-depth analyses are performed to provide new insights into ORConvQA.