 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Effectiveness of LLMs in Delivering Cognitive Behavioral Therapy
Mar 04, 2026As mental health issues continue to rise globally, there is an increasing demand for accessible and scalable therapeutic solutions. Many individuals currently seek support from Large Language Models (LLMs), even though these models have not been validated for use in counseling services. In this paper, we evaluate LLMs' ability to emulate professional therapists practicing Cognitive Behavioral Therapy (CBT). Using anonymized, transcribed role-play sessions between licensed therapists and clients, we compare two approaches: (1) a generation-only method and (2) a Retrieval-Augmented Generation (RAG) approach using CBT guidelines. We evaluate both proprietary and open-source models for linguistic quality, semantic coherence, and therapeutic fidelity using standard natural language generation (NLG) metrics, natural language inference (NLI), and automated scoring for skills assessment. Our results indicate that while LLMs can generate CBT-like dialogues, they are limited in their ability to convey empathy and maintain consistency.
TalkDep: Clinically Grounded LLM Personas for Conversation-Centric Depression Screening
Aug 06, 2025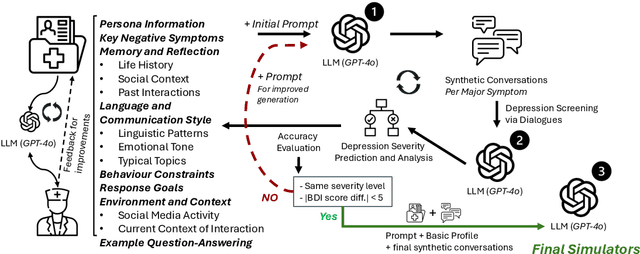
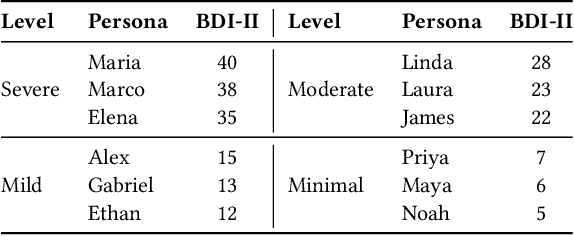

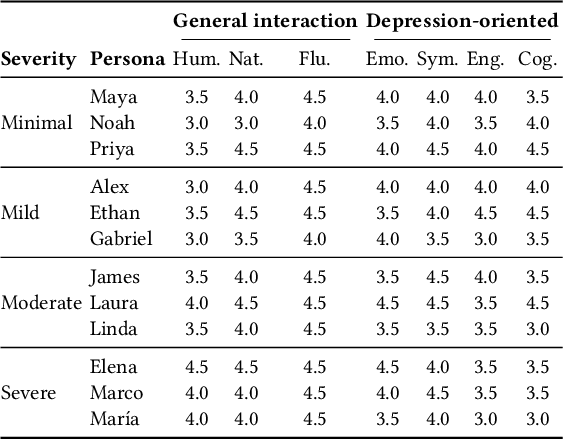
The increasing demand for mental health services has outpaced the availability of real training data to develop clinical professionals, leading to limited support for the diagnosis of depression. This shortage has motivated the development of simulated or virtual patients to assist in training and evaluation, but existing approaches often fail to generate clinically valid, natural, and diverse symptom presentations. In this work, we embrace the recent advanced language models as the backbone and propose a novel clinician-in-the-loop patient simulation pipeline, TalkDep, with access to diversified patient profiles to develop simulated patients. By conditioning the model on psychiatric diagnostic criteria, symptom severity scales, and contextual factors, our goal is to create authentic patient responses that can better support diagnostic model training and evaluation. We verify the reliability of these simulated patients with thorough assessments conducted by clinical professionals. The availability of validated simulated patients offers a scalable and adaptable resource for improving the robustness and generalisability of automatic depression diagnosis systems.
A Survey on Multilingual Mental Disorders Detection from Social Media Data
May 21, 2025The increasing prevalence of mental health disorders globally highlights the urgent need for effective digital screening methods that can be used in multilingual contexts. Most existing studies, however, focus on English data, overlooking critical mental health signals that may be present in non-English texts. To address this important gap, we present the first survey on the detection of mental health disorders using multilingual social media data. We investigate the cultural nuances that influence online language patterns and self-disclosure behaviors, and how these factors can impact the performance of NLP tools. Additionally, we provide a comprehensive list of multilingual data collections that can be used for developing NLP models for mental health screening. Our findings can inform the design of effective multilingual mental health screening tools that can meet the needs of diverse populations, ultimately improving mental health outcomes on a global scale.
The Emotional Spectrum of LLMs: Leveraging Empathy and Emotion-Based Markers for Mental Health Support
Dec 28, 2024The increasing demand for mental health services has highlighted the need for innovative solutions, particularly in the realm of psychological conversational AI, where the availability of sensitive data is scarce. In this work, we explored the development of a system tailored for mental health support with a novel approach to psychological assessment based on explainable emotional profiles in combination with empathetic conversational models, offering a promising tool for augmenting traditional care, particularly where immediate expertise is unavailable. Our work can be divided into two main parts, intrinsecaly connected to each other. First, we present RACLETTE, a conversational system that demonstrates superior emotional accuracy compared to state-of-the-art benchmarks in both understanding users' emotional states and generating empathetic responses during conversations, while progressively building an emotional profile of the user through their interactions. Second, we show how the emotional profiles of a user can be used as interpretable markers for mental health assessment. These profiles can be compared with characteristic emotional patterns associated with different mental disorders, providing a novel approach to preliminary screening and support.
Towards Self-Contained Answers: Entity-Based Answer Rewriting in Conversational Search
Mar 04, 2024



Conversational information-seeking (CIS) is an emerging paradigm for knowledge acquisition and exploratory search. Traditional web search interfaces enable easy exploration of entities, but this is limited in conversational settings due to the limited-bandwidth interface. This paper explore ways to rewrite answers in CIS, so that users can understand them without having to resort to external services or sources. Specifically, we focus on salient entities -- entities that are central to understanding the answer. As our first contribution, we create a dataset of conversations annotated with entities for saliency. Our analysis of the collected data reveals that the majority of answers contain salient entities. As our second contribution, we propose two answer rewriting strategies aimed at improving the overall user experience in CIS. One approach expands answers with inline definitions of salient entities, making the answer self-contained. The other approach complements answers with follow-up questions, offering users the possibility to learn more about specific entities. Results of a crowdsourcing-based study indicate that rewritten answers are clearly preferred over the original ones. We also find that inline definitions tend to be favored over follow-up questions, but this choice is highly subjective, thereby providing a promising future direction for personalization.
Estimating the Usefulness of Clarifying Questions and Answers for Conversational Search
Jan 21, 2024While the body of research directed towards constructing and generating clarifying questions in mixed-initiative conversational search systems is vast, research aimed at processing and comprehending users' answers to such questions is scarce. To this end, we present a simple yet effective method for processing answers to clarifying questions, moving away from previous work that simply appends answers to the original query and thus potentially degrades retrieval performance. Specifically, we propose a classifier for assessing usefulness of the prompted clarifying question and an answer given by the user. Useful questions or answers are further appended to the conversation history and passed to a transformer-based query rewriting module. Results demonstrate significant improvements over strong non-mixed-initiative baselines. Furthermore, the proposed approach mitigates the performance drops when non useful questions and answers are utilized.
Analyzing Coherency in Facet-based Clarification Prompt Generation for Search
Jan 09, 2024Clarifying user's information needs is an essential component of modern search systems. While most of the approaches for constructing clarifying prompts rely on query facets, the impact of the quality of the facets is relatively unexplored. In this work, we concentrate on facet quality through the notion of facet coherency and assess its importance for overall usefulness for clarification in search. We find that existing evaluation procedures do not account for facet coherency, as evident by the poor correlation of coherency with automated metrics. Moreover, we propose a coherency classifier and assess the prevalence of incoherent facets in a well-established dataset on clarification. Our findings can serve as motivation for future work on the topic.
GRM: Generative Relevance Modeling Using Relevance-Aware Sample Estimation for Document Retrieval
Jun 16, 2023


Recent studies show that Generative Relevance Feedback (GRF), using text generated by Large Language Models (LLMs), can enhance the effectiveness of query expansion. However, LLMs can generate irrelevant information that harms retrieval effectiveness. To address this, we propose Generative Relevance Modeling (GRM) that uses Relevance-Aware Sample Estimation (RASE) for more accurate weighting of expansion terms. Specifically, we identify similar real documents for each generated document and use a neural re-ranker to estimate their relevance. Experiments on three standard document ranking benchmarks show that GRM improves MAP by 6-9% and R@1k by 2-4%, surpassing previous methods.
Exploiting Simulated User Feedback for Conversational Search: Ranking, Rewriting, and Beyond
May 07, 2023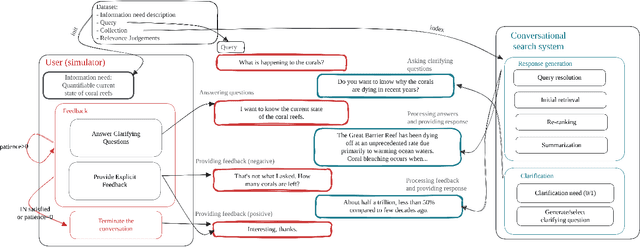


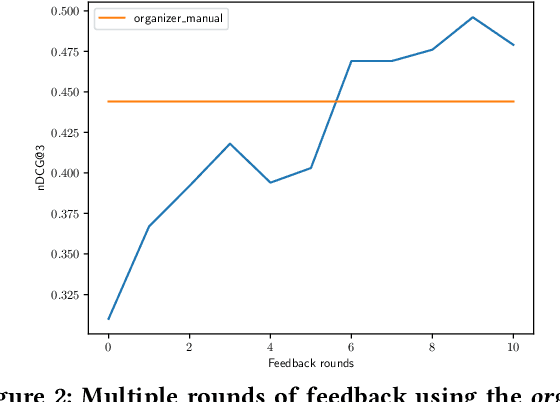
This research aims to explore various methods for assessing user feedback in mixed-initiative conversational search (CS) systems. While CS systems enjoy profuse advancements across multiple aspects, recent research fails to successfully incorporate feedback from the users. One of the main reasons for that is the lack of system-user conversational interaction data. To this end, we propose a user simulator-based framework for multi-turn interactions with a variety of mixed-initiative CS systems. Specifically, we develop a user simulator, dubbed ConvSim, that, once initialized with an information need description, is capable of providing feedback to a system's responses, as well as answering potential clarifying questions. Our experiments on a wide variety of state-of-the-art passage retrieval and neural re-ranking models show that effective utilization of user feedback can lead to 16% retrieval performance increase in terms of nDCG@3. Moreover, we observe consistent improvements as the number of feedback rounds increases (35% relative improvement in terms of nDCG@3 after three rounds). This points to a research gap in the development of specific feedback processing modules and opens a potential for significant advancements in CS. To support further research in the topic, we release over 30,000 transcripts of system-simulator interactions based on well-established CS datasets.
Evaluating Mixed-initiative Conversational Search Systems via User Simulation
Apr 20, 2022
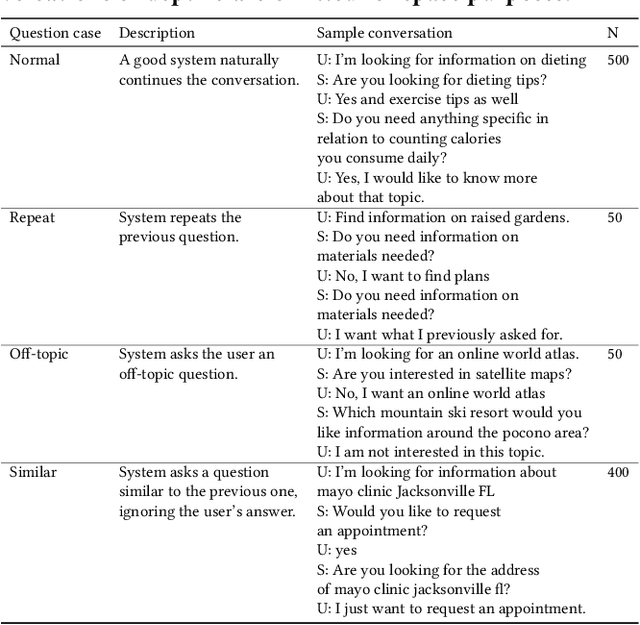
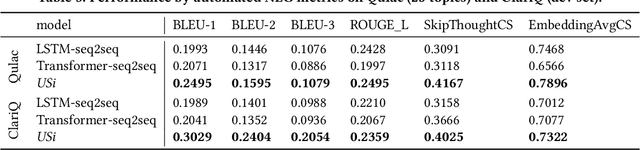

Clarifying the underlying user information need by asking clarifying questions is an important feature of modern conversational search system. However, evaluation of such systems through answering prompted clarifying questions requires significant human effort, which can be time-consuming and expensive. In this paper, we propose a conversational User Simulator, called USi, for automatic evaluation of such conversational search systems. Given a description of an information need, USi is capable of automatically answering clarifying questions about the topic throughout the search session. Through a set of experiments, including automated natural language generation metrics and crowdsourcing studies, we show that responses generated by USi are both inline with the underlying information need and comparable to human-generated answers. Moreover, we make the first steps towards multi-turn interactions, where conversational search systems asks multiple questions to the (simulated) user with a goal of clarifying the user need. To this end, we expand on currently available datasets for studying clarifying questions, i.e., Qulac and ClariQ, by performing a crowdsourcing-based multi-turn data acquisition. We show that our generative, GPT2-based model, is capable of providing accurate and natural answers to unseen clarifying questions in the single-turn setting and discuss capabilities of our model in the multi-turn setting. We provide the code, data, and the pre-trained model to be used for further research on the topic.