 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Simulated User Feedback for Conversational Search: Ranking, Rewriting, and Beyond
May 07, 2023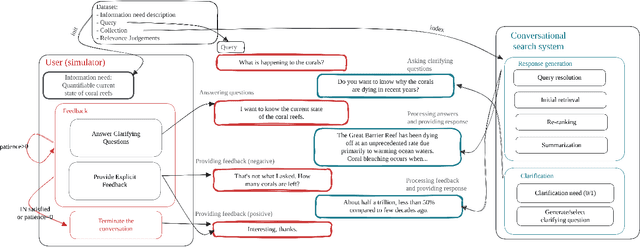


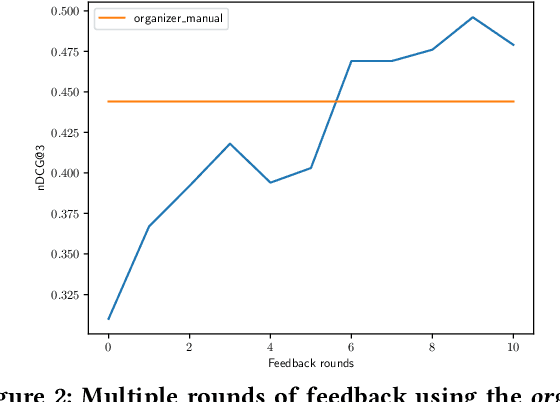
This research aims to explore various methods for assessing user feedback in mixed-initiative conversational search (CS) systems. While CS systems enjoy profuse advancements across multiple aspects, recent research fails to successfully incorporate feedback from the users. One of the main reasons for that is the lack of system-user conversational interaction data. To this end, we propose a user simulator-based framework for multi-turn interactions with a variety of mixed-initiative CS systems. Specifically, we develop a user simulator, dubbed ConvSim, that, once initialized with an information need description, is capable of providing feedback to a system's responses, as well as answering potential clarifying questions. Our experiments on a wide variety of state-of-the-art passage retrieval and neural re-ranking models show that effective utilization of user feedback can lead to 16% retrieval performance increase in terms of nDCG@3. Moreover, we observe consistent improvements as the number of feedback rounds increases (35% relative improvement in terms of nDCG@3 after three rounds). This points to a research gap in the development of specific feedback processing modules and opens a potential for significant advancements in CS. To support further research in the topic, we release over 30,000 transcripts of system-simulator interactions based on well-established CS datasets.
GRILLBot: An Assistant for Real-World Tasks with Neural Semantic Parsing and Graph-Based Representations
Aug 31, 2022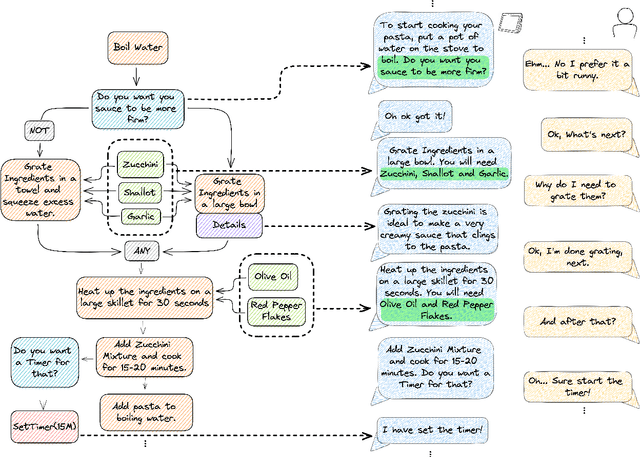

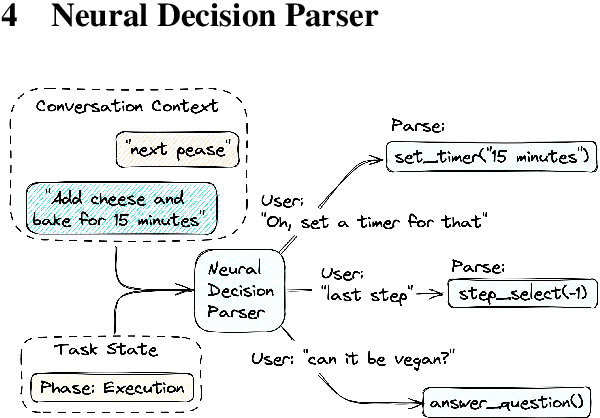
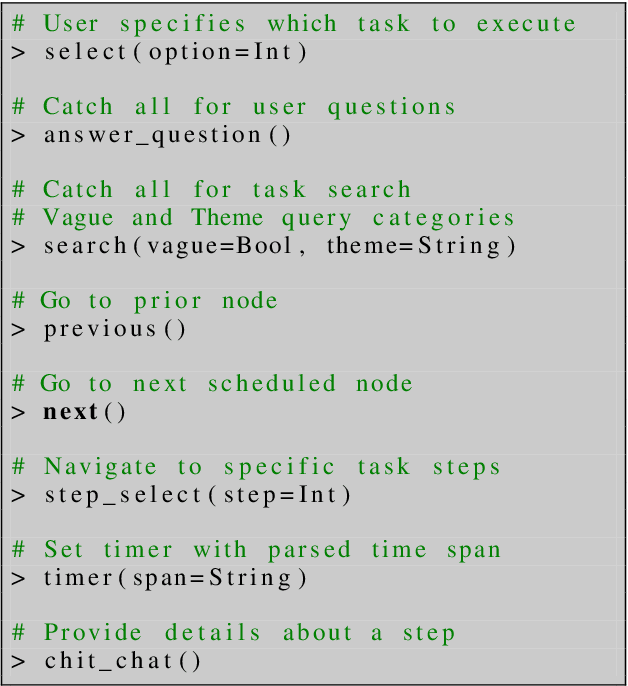
GRILLBot is the winning system in the 2022 Alexa Prize TaskBot Challenge, moving towards the next generation of multimodal task assistants. It is a voice assistant to guide users through complex real-world tasks in the domains of cooking and home improvement. These are long-running and complex tasks that require flexible adjustment and adaptation. The demo highlights the core aspects, including a novel Neural Decision Parser for contextualized semantic parsing, a new "TaskGraph" state representation that supports conditional execution, knowledge-grounded chit-chat, and automatic enrichment of tasks with images and videos.
CODEC: Complex Document and Entity Collection
May 17, 2022
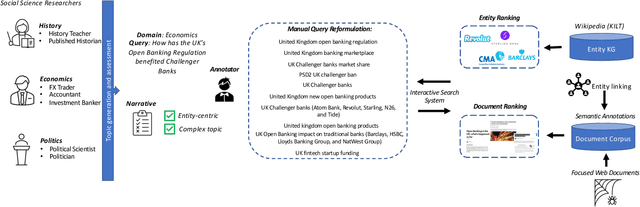

CODEC is a document and entity ranking benchmark that focuses on complex research topics. We target essay-style information needs of social science researchers, i.e. "How has the UK's Open Banking Regulation benefited Challenger Banks?". CODEC includes 42 topics developed by researchers and a new focused web corpus with semantic annotations including entity links. This resource includes expert judgments on 17,509 documents and entities (416.9 per topic) from diverse automatic and interactive manual runs. The manual runs include 387 query reformulations, providing data for query performance prediction and automatic rewriting evaluation. CODEC includes analysis of state-of-the-art systems, including dense retrieval and neural re-ranking. The results show the topics are challenging with headroom for document and entity ranking improvement. Query expansion with entity information shows significant gains in document ranking, demonstrating the resource's value for evaluating and improving entity-oriented search. We also show that the manual query reformulations significantly improve document ranking and entity ranking performance. Overall, CODEC provides challenging research topics to support the development and evaluation of entity-centric search methods.
Ìtàkúròso: Exploiting Cross-Lingual Transferability for Natural Language Generation of Dialogues in Low-Resource, African Languages
Apr 17, 2022
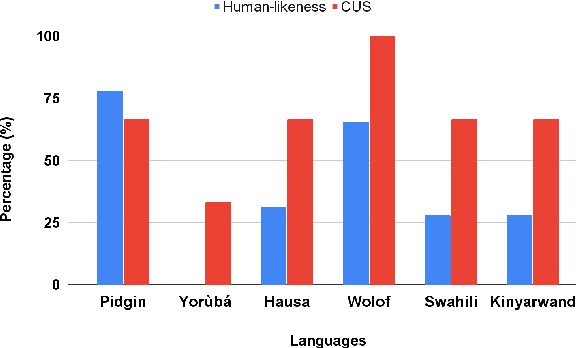
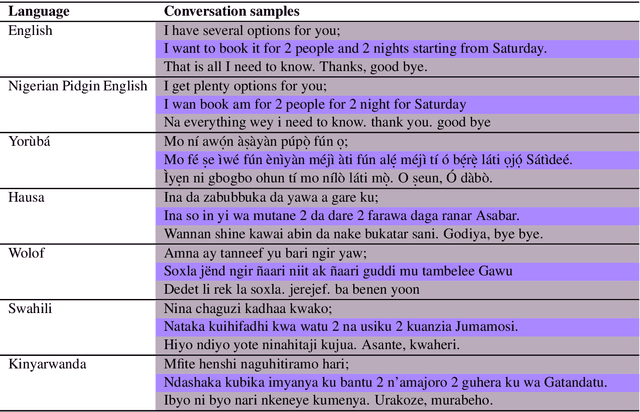
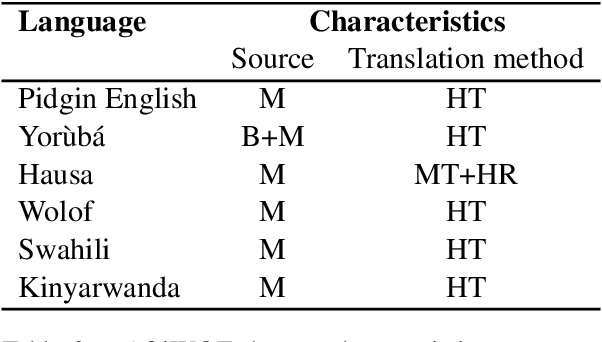
We investigate the possibility of cross-lingual transfer from a state-of-the-art (SoTA) deep monolingual model (DialoGPT) to 6 African languages and compare with 2 baselines (BlenderBot 90M, another SoTA, and a simple Seq2Seq). The languages are Swahili, Wolof, Hausa, Nigerian Pidgin English, Kinyarwanda & Yor\`ub\'a. Generation of dialogues is known to be a challenging task for many reasons. It becomes more challenging for African languages which are low-resource in terms of data. Therefore, we translate a small portion of the English multi-domain MultiWOZ dataset for each target language. Besides intrinsic evaluation (i.e. perplexity), we conduct human evaluation of single-turn conversations by using majority votes and measure inter-annotator agreement (IAA). The results show that the hypothesis that deep monolingual models learn some abstractions that generalise across languages holds. We observe human-like conversations in 5 out of the 6 languages. It, however, applies to different degrees in different languages, which is expected. The language with the most transferable properties is the Nigerian Pidgin English, with a human-likeness score of 78.1%, of which 34.4% are unanimous. The main contributions of this paper include the representation (through the provision of high-quality dialogue data) of under-represented African languages and demonstrating the cross-lingual transferability hypothesis for dialogue systems. We also provide the datasets and host the model checkpoints/demos on the HuggingFace hub for public access.