 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Assistant Toolkit -- version 2
Mar 01, 2024



We present the second version of the Open Assistant Toolkit (OAT-v2), an open-source task-oriented conversational system for composing generative neural models. OAT-v2 is a scalable and flexible assistant platform supporting multiple domains and modalities of user interaction. It splits processing a user utterance into modular system components, including submodules such as action code generation, multimodal content retrieval, and knowledge-augmented response generation. Developed over multiple years of the Alexa TaskBot challenge, OAT-v2 is a proven system that enables scalable and robust experimentation in experimental and real-world deployment. OAT-v2 provides open models and software for research and commercial applications to enable the future of multimodal virtual assistants across diverse applications and types of rich interaction.
GRILLBot In Practice: Lessons and Tradeoffs Deploying Large Language Models for Adaptable Conversational Task Assistants
Feb 12, 2024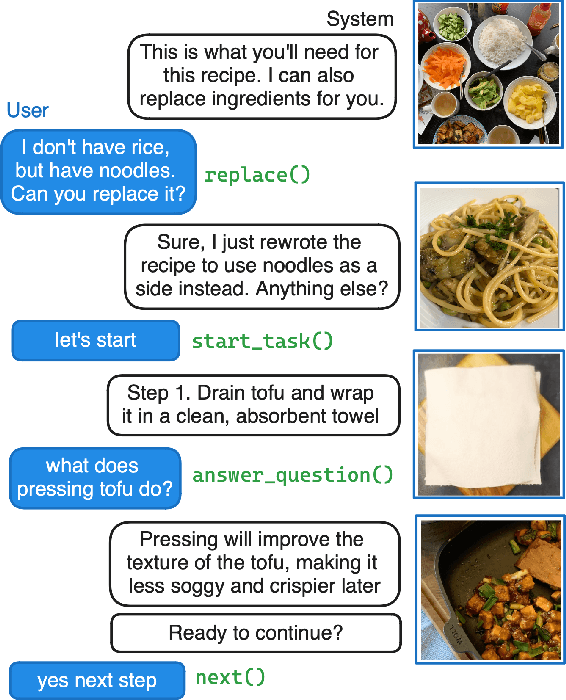

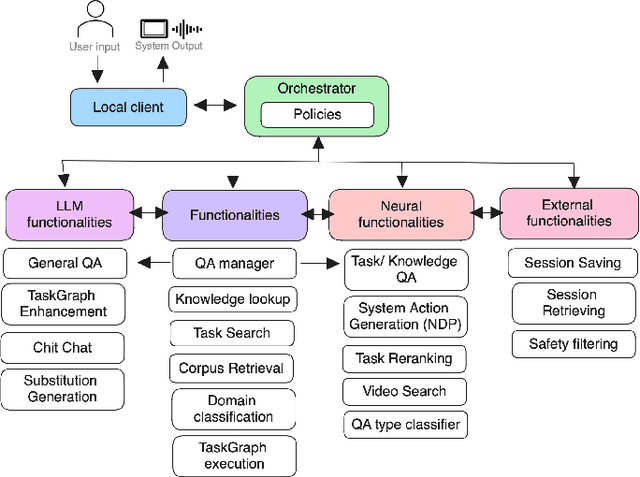

We tackle the challenge of building real-world multimodal assistants for complex real-world tasks. We describe the practicalities and challenges of developing and deploying GRILLBot, a leading (first and second prize winning in 2022 and 2023) system deployed in the Alexa Prize TaskBot Challenge. Building on our Open Assistant Toolkit (OAT) framework, we propose a hybrid architecture that leverages Large Language Models (LLMs) and specialised models tuned for specific subtasks requiring very low latency. OAT allows us to define when, how and which LLMs should be used in a structured and deployable manner. For knowledge-grounded question answering and live task adaptations, we show that LLM reasoning abilities over task context and world knowledge outweigh latency concerns. For dialogue state management, we implement a code generation approach and show that specialised smaller models have 84% effectiveness with 100x lower latency. Overall, we provide insights and discuss tradeoffs for deploying both traditional models and LLMs to users in complex real-world multimodal environments in the Alexa TaskBot challenge. These experiences will continue to evolve as LLMs become more capable and efficient -- fundamentally reshaping OAT and future assistant architectures.
DREQ: Document Re-Ranking Using Entity-based Query Understanding
Jan 11, 2024While entity-oriented neural IR models have advanced significantly, they often overlook a key nuance: the varying degrees of influence individual entities within a document have on its overall relevance. Addressing this gap, we present DREQ, an entity-oriented dense document re-ranking model. Uniquely, we emphasize the query-relevant entities within a document's representation while simultaneously attenuating the less relevant ones, thus obtaining a query-specific entity-centric document representation. We then combine this entity-centric document representation with the text-centric representation of the document to obtain a "hybrid" representation of the document. We learn a relevance score for the document using this hybrid representation. Using four large-scale benchmarks, we show that DREQ outperforms state-of-the-art neural and non-neural re-ranking methods, highlighting the effectiveness of our entity-oriented representation approach.
Re-Rank - Expand - Repeat: Adaptive Query Expansion for Document Retrieval Using Words and Entities
Jun 29, 2023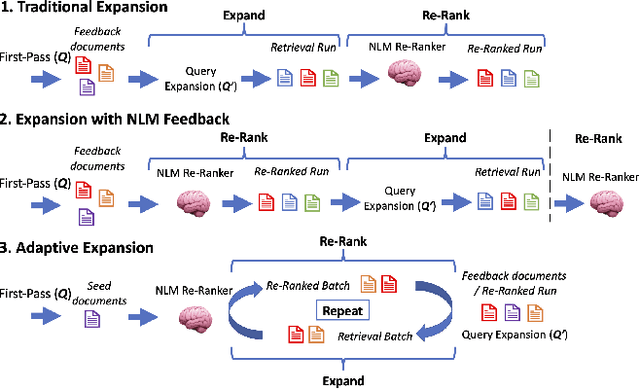
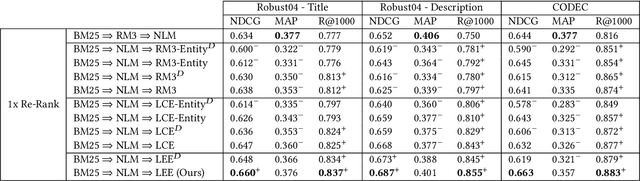

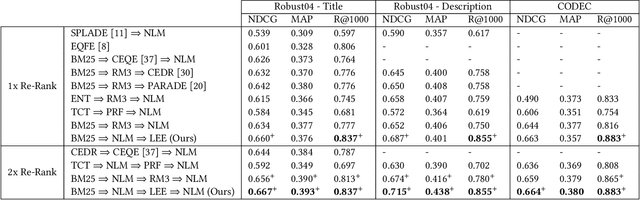
Sparse and dense pseudo-relevance feedback (PRF) approaches perform poorly on challenging queries due to low precision in first-pass retrieval. However, recent advances in neural language models (NLMs) can re-rank relevant documents to top ranks, even when few are in the re-ranking pool. This paper first addresses the problem of poor pseudo-relevance feedback by simply applying re-ranking prior to query expansion and re-executing this query. We find that this change alone can improve the retrieval effectiveness of sparse and dense PRF approaches by 5-8%. Going further, we propose a new expansion model, Latent Entity Expansion (LEE), a fine-grained word and entity-based relevance modelling incorporating localized features. Finally, we include an "adaptive" component to the retrieval process, which iteratively refines the re-ranking pool during scoring using the expansion model, i.e. we "re-rank - expand - repeat". Using LEE, we achieve (to our knowledge) the best NDCG, MAP and R@1000 results on the TREC Robust 2004 and CODEC adhoc document datasets, demonstrating a significant advancement in expansion effectiveness.
GRM: Generative Relevance Modeling Using Relevance-Aware Sample Estimation for Document Retrieval
Jun 16, 2023


Recent studies show that Generative Relevance Feedback (GRF), using text generated by Large Language Models (LLMs), can enhance the effectiveness of query expansion. However, LLMs can generate irrelevant information that harms retrieval effectiveness. To address this, we propose Generative Relevance Modeling (GRM) that uses Relevance-Aware Sample Estimation (RASE) for more accurate weighting of expansion terms. Specifically, we identify similar real documents for each generated document and use a neural re-ranker to estimate their relevance. Experiments on three standard document ranking benchmarks show that GRM improves MAP by 6-9% and R@1k by 2-4%, surpassing previous methods.
Generative and Pseudo-Relevant Feedback for Sparse, Dense and Learned Sparse Retrieval
May 12, 2023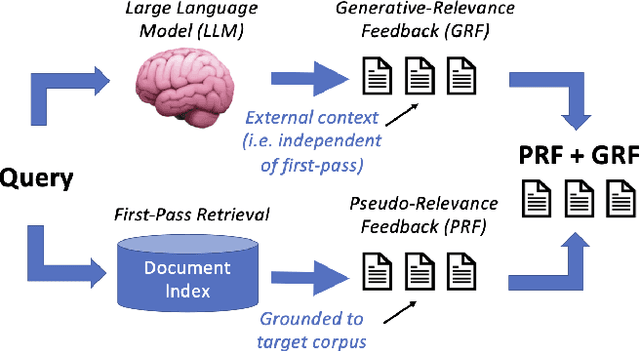
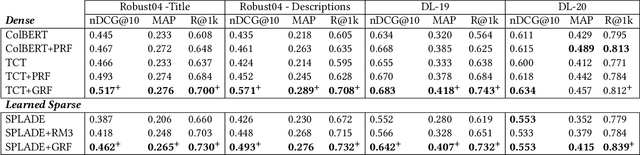
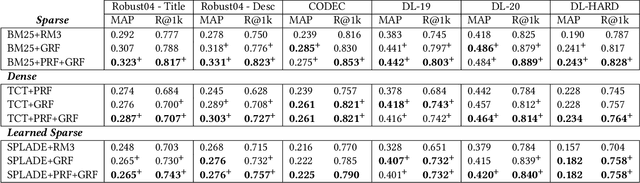
Pseudo-relevance feedback (PRF) is a classical approach to address lexical mismatch by enriching the query using first-pass retrieval. Moreover, recent work on generative-relevance feedback (GRF) shows that query expansion models using text generated from large language models can improve sparse retrieval without depending on first-pass retrieval effectiveness. This work extends GRF to dense and learned sparse retrieval paradigms with experiments over six standard document ranking benchmarks. We find that GRF improves over comparable PRF techniques by around 10% on both precision and recall-oriented measures. Nonetheless, query analysis shows that GRF and PRF have contrasting benefits, with GRF providing external context not present in first-pass retrieval, whereas PRF grounds the query to the information contained within the target corpus. Thus, we propose combining generative and pseudo-relevance feedback ranking signals to achieve the benefits of both feedback classes, which significantly increases recall over PRF methods on 95% of experiments.
Generative Relevance Feedback with Large Language Models
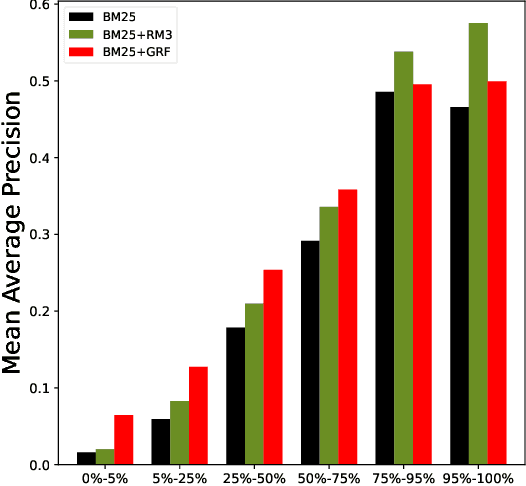
Apr 25, 2023Current query expansion models use pseudo-relevance feedback to improve first-pass retrieval effectiveness; however, this fails when the initial results are not relevant. Instead of building a language model from retrieved results, we propose Generative Relevance Feedback (GRF) that builds probabilistic feedback models from long-form text generated from Large Language Models. We study the effective methods for generating text by varying the zero-shot generation subtasks: queries, entities, facts, news articles, documents, and essays. We evaluate GRF on document retrieval benchmarks covering a diverse set of queries and document collections, and the results show that GRF methods significantly outperform previous PRF methods. Specifically, we improve MAP between 5-19% and NDCG@10 17-24% compared to RM3 expansion, and achieve the best R@1k effectiveness on all datasets compared to state-of-the-art sparse, dense, and expansion models.
DocuT5: Seq2seq SQL Generation with Table Documentation
Nov 11, 2022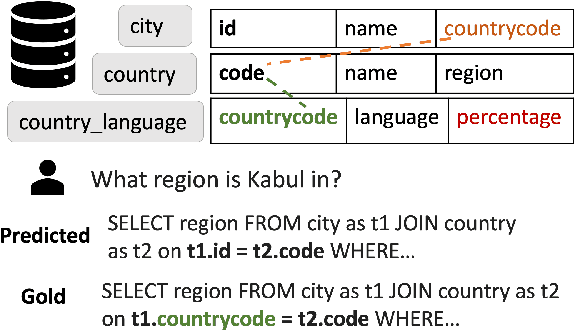



Current SQL generators based on pre-trained language models struggle to answer complex questions requiring domain context or understanding fine-grained table structure. Humans would deal with these unknowns by reasoning over the documentation of the tables. Based on this hypothesis, we propose DocuT5, which uses off-the-shelf language model architecture and injects knowledge from external `documentation' to improve domain generalization. We perform experiments on the Spider family of datasets that contain complex questions that are cross-domain and multi-table. Specifically, we develop a new text-to-SQL failure taxonomy and find that 19.6% of errors are due to foreign key mistakes, and 49.2% are due to a lack of domain knowledge. We proposed DocuT5, a method that captures knowledge from (1) table structure context of foreign keys and (2) domain knowledge through contextualizing tables and columns. Both types of knowledge improve over state-of-the-art T5 with constrained decoding on Spider, and domain knowledge produces state-of-the-art comparable effectiveness on Spider-DK and Spider-SYN datasets.
Query-Specific Knowledge Graphs for Complex Finance Topics
Nov 08, 2022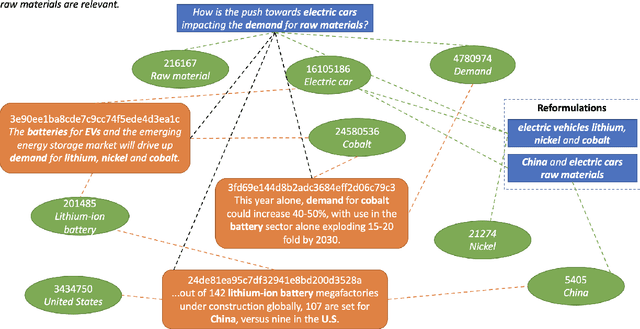


Across the financial domain, researchers answer complex questions by extensively "searching" for relevant information to generate long-form reports. This workshop paper discusses automating the construction of query-specific document and entity knowledge graphs (KGs) for complex research topics. We focus on the CODEC dataset, where domain experts (1) create challenging questions, (2) construct long natural language narratives, and (3) iteratively search and assess the relevance of documents and entities. For the construction of query-specific KGs, we show that state-of-the-art ranking systems have headroom for improvement, with specific failings due to a lack of context or explicit knowledge representation. We demonstrate that entity and document relevance are positively correlated, and that entity-based query feedback improves document ranking effectiveness. Furthermore, we construct query-specific KGs using retrieval and evaluate using CODEC's "ground-truth graphs", showing the precision and recall trade-offs. Lastly, we point to future work, including adaptive KG retrieval algorithms and GNN-based weighting methods, while highlighting key challenges such as high-quality data, information extraction recall, and the size and sparsity of complex topic graphs.
GRILLBot: An Assistant for Real-World Tasks with Neural Semantic Parsing and Graph-Based Representations
Aug 31, 2022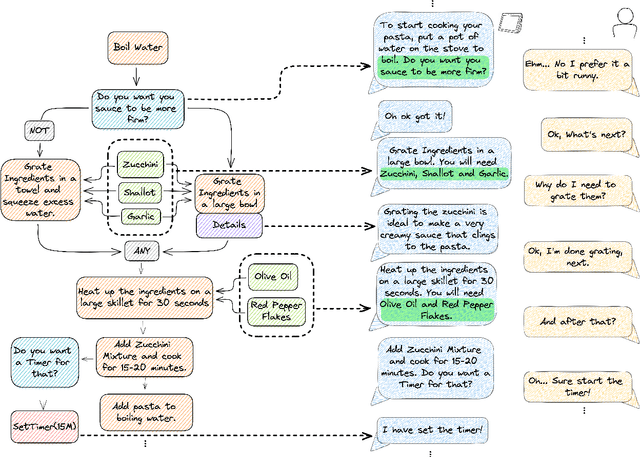

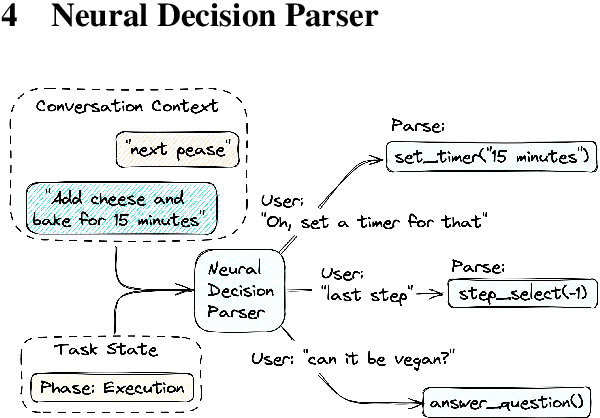
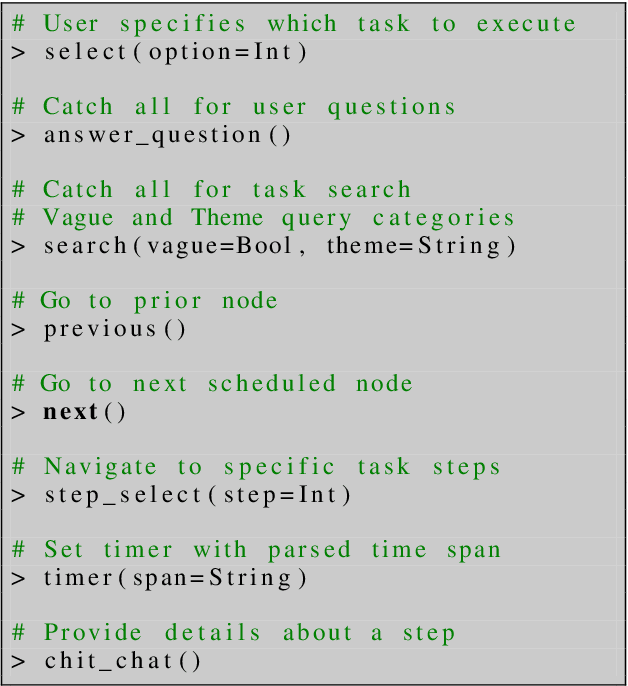
GRILLBot is the winning system in the 2022 Alexa Prize TaskBot Challenge, moving towards the next generation of multimodal task assistants. It is a voice assistant to guide users through complex real-world tasks in the domains of cooking and home improvement. These are long-running and complex tasks that require flexible adjustment and adaptation. The demo highlights the core aspects, including a novel Neural Decision Parser for contextualized semantic parsing, a new "TaskGraph" state representation that supports conditional execution, knowledge-grounded chit-chat, and automatic enrichment of tasks with images and videos.