 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Specific Knowledge Graphs for Complex Finance Topics
Paper and Code
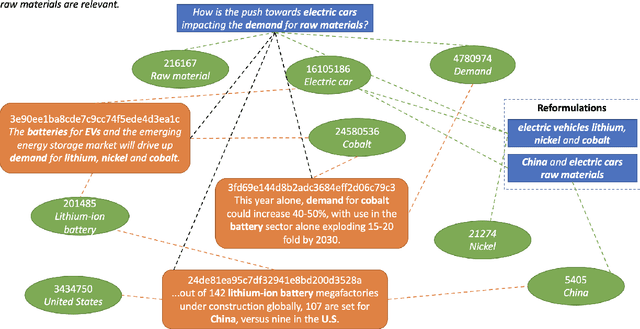


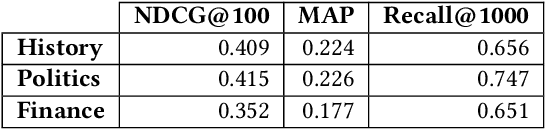
Across the financial domain, researchers answer complex questions by extensively "searching" for relevant information to generate long-form reports. This workshop paper discusses automating the construction of query-specific document and entity knowledge graphs (KGs) for complex research topics. We focus on the CODEC dataset, where domain experts (1) create challenging questions, (2) construct long natural language narratives, and (3) iteratively search and assess the relevance of documents and entities. For the construction of query-specific KGs, we show that state-of-the-art ranking systems have headroom for improvement, with specific failings due to a lack of context or explicit knowledge representation. We demonstrate that entity and document relevance are positively correlated, and that entity-based query feedback improves document ranking effectiveness. Furthermore, we construct query-specific KGs using retrieval and evaluate using CODEC's "ground-truth graphs", showing the precision and recall trade-offs. Lastly, we point to future work, including adaptive KG retrieval algorithms and GNN-based weighting methods, while highlighting key challenges such as high-quality data, information extraction recall, and the size and sparsity of complex topic graphs.