 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Assistant Toolkit -- version 2
Mar 01, 2024



We present the second version of the Open Assistant Toolkit (OAT-v2), an open-source task-oriented conversational system for composing generative neural models. OAT-v2 is a scalable and flexible assistant platform supporting multiple domains and modalities of user interaction. It splits processing a user utterance into modular system components, including submodules such as action code generation, multimodal content retrieval, and knowledge-augmented response generation. Developed over multiple years of the Alexa TaskBot challenge, OAT-v2 is a proven system that enables scalable and robust experimentation in experimental and real-world deployment. OAT-v2 provides open models and software for research and commercial applications to enable the future of multimodal virtual assistants across diverse applications and types of rich interaction.
GRILLBot In Practice: Lessons and Tradeoffs Deploying Large Language Models for Adaptable Conversational Task Assistants
Feb 12, 2024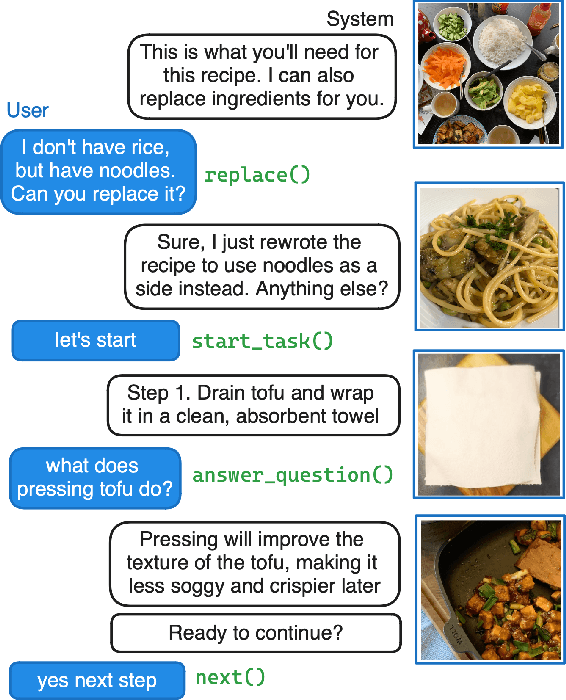

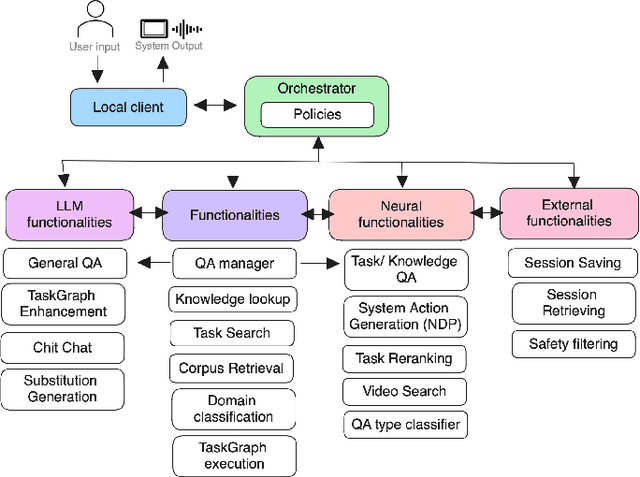

We tackle the challenge of building real-world multimodal assistants for complex real-world tasks. We describe the practicalities and challenges of developing and deploying GRILLBot, a leading (first and second prize winning in 2022 and 2023) system deployed in the Alexa Prize TaskBot Challenge. Building on our Open Assistant Toolkit (OAT) framework, we propose a hybrid architecture that leverages Large Language Models (LLMs) and specialised models tuned for specific subtasks requiring very low latency. OAT allows us to define when, how and which LLMs should be used in a structured and deployable manner. For knowledge-grounded question answering and live task adaptations, we show that LLM reasoning abilities over task context and world knowledge outweigh latency concerns. For dialogue state management, we implement a code generation approach and show that specialised smaller models have 84% effectiveness with 100x lower latency. Overall, we provide insights and discuss tradeoffs for deploying both traditional models and LLMs to users in complex real-world multimodal environments in the Alexa TaskBot challenge. These experiences will continue to evolve as LLMs become more capable and efficient -- fundamentally reshaping OAT and future assistant architectures.
Controllable Chest X-Ray Report Generation from Longitudinal Representations
Oct 09, 2023



Radiology reports are detailed text descriptions of the content of medical scans. Each report describes the presence/absence and location of relevant clinical findings, commonly including comparison with prior exams of the same patient to describe how they evolved. Radiology reporting is a time-consuming process, and scan results are often subject to delays. One strategy to speed up reporting is to integrate automated reporting systems, however clinical deployment requires high accuracy and interpretability. Previous approaches to automated radiology reporting generally do not provide the prior study as input, precluding comparison which is required for clinical accuracy in some types of scans, and offer only unreliable methods of interpretability. Therefore, leveraging an existing visual input format of anatomical tokens, we introduce two novel aspects: (1) longitudinal representation learning -- we input the prior scan as an additional input, proposing a method to align, concatenate and fuse the current and prior visual information into a joint longitudinal representation which can be provided to the multimodal report generation model; (2) sentence-anatomy dropout -- a training strategy for controllability in which the report generator model is trained to predict only sentences from the original report which correspond to the subset of anatomical regions given as input. We show through in-depth experiments on the MIMIC-CXR dataset how the proposed approach achieves state-of-the-art results while enabling anatomy-wise controllable report generation.
Finding-Aware Anatomical Tokens for Chest X-Ray Automated Reporting
Aug 30, 2023



The task of radiology reporting comprises describing and interpreting the medical findings in radiographic images, including description of their location and appearance. Automated approaches to radiology reporting require the image to be encoded into a suitable token representation for input to the language model. Previous methods commonly use convolutional neural networks to encode an image into a series of image-level feature map representations. However, the generated reports often exhibit realistic style but imperfect accuracy. Inspired by recent works for image captioning in the general domain in which each visual token corresponds to an object detected in an image, we investigate whether using local tokens corresponding to anatomical structures can improve the quality of the generated reports. We introduce a novel adaptation of Faster R-CNN in which finding detection is performed for the candidate bounding boxes extracted during anatomical structure localisation. We use the resulting bounding box feature representations as our set of finding-aware anatomical tokens. This encourages the extracted anatomical tokens to be informative about the findings they contain (required for the final task of radiology reporting). Evaluating on the MIMIC-CXR dataset of chest X-Ray images, we show that task-aware anatomical tokens give state-of-the-art performance when integrated into an automated reporting pipeline, yielding generated reports with improved clinical accuracy.
Re-Rank - Expand - Repeat: Adaptive Query Expansion for Document Retrieval Using Words and Entities
Jun 29, 2023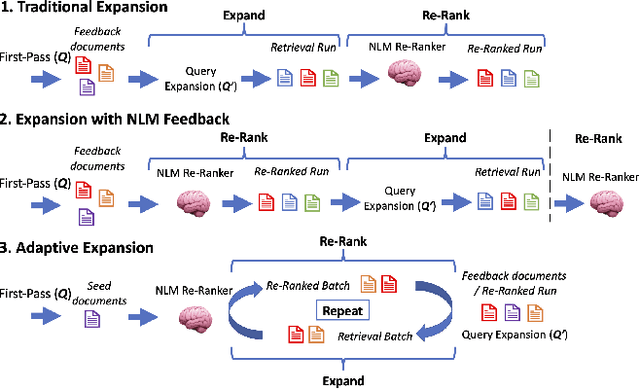
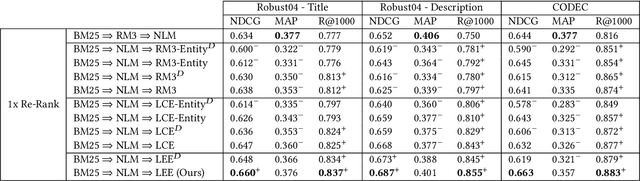

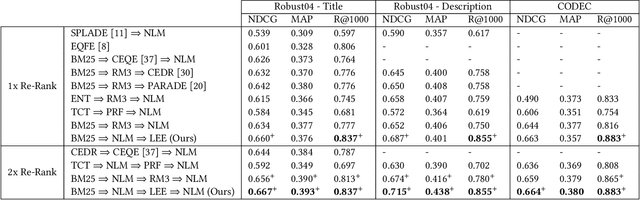
Sparse and dense pseudo-relevance feedback (PRF) approaches perform poorly on challenging queries due to low precision in first-pass retrieval. However, recent advances in neural language models (NLMs) can re-rank relevant documents to top ranks, even when few are in the re-ranking pool. This paper first addresses the problem of poor pseudo-relevance feedback by simply applying re-ranking prior to query expansion and re-executing this query. We find that this change alone can improve the retrieval effectiveness of sparse and dense PRF approaches by 5-8%. Going further, we propose a new expansion model, Latent Entity Expansion (LEE), a fine-grained word and entity-based relevance modelling incorporating localized features. Finally, we include an "adaptive" component to the retrieval process, which iteratively refines the re-ranking pool during scoring using the expansion model, i.e. we "re-rank - expand - repeat". Using LEE, we achieve (to our knowledge) the best NDCG, MAP and R@1000 results on the TREC Robust 2004 and CODEC adhoc document datasets, demonstrating a significant advancement in expansion effectiveness.
GRM: Generative Relevance Modeling Using Relevance-Aware Sample Estimation for Document Retrieval
Jun 16, 2023


Recent studies show that Generative Relevance Feedback (GRF), using text generated by Large Language Models (LLMs), can enhance the effectiveness of query expansion. However, LLMs can generate irrelevant information that harms retrieval effectiveness. To address this, we propose Generative Relevance Modeling (GRM) that uses Relevance-Aware Sample Estimation (RASE) for more accurate weighting of expansion terms. Specifically, we identify similar real documents for each generated document and use a neural re-ranker to estimate their relevance. Experiments on three standard document ranking benchmarks show that GRM improves MAP by 6-9% and R@1k by 2-4%, surpassing previous methods.
Generative and Pseudo-Relevant Feedback for Sparse, Dense and Learned Sparse Retrieval
May 12, 2023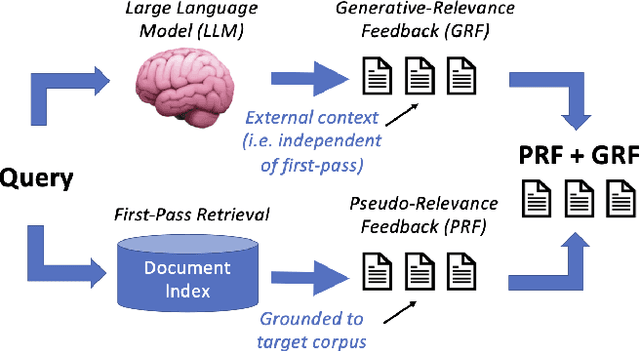
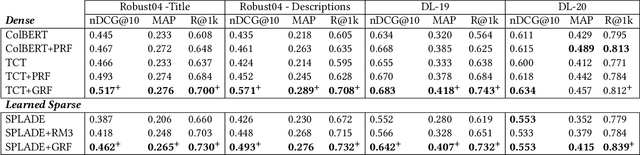
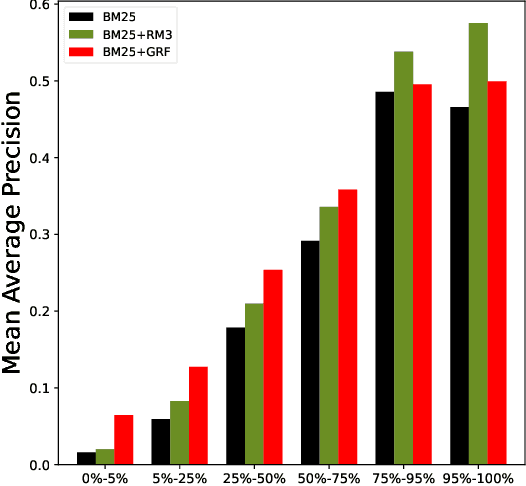
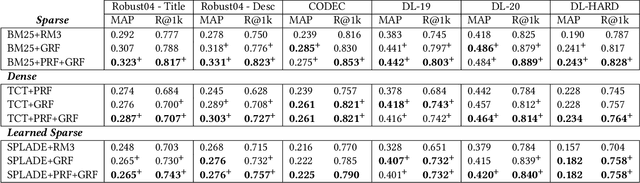
Pseudo-relevance feedback (PRF) is a classical approach to address lexical mismatch by enriching the query using first-pass retrieval. Moreover, recent work on generative-relevance feedback (GRF) shows that query expansion models using text generated from large language models can improve sparse retrieval without depending on first-pass retrieval effectiveness. This work extends GRF to dense and learned sparse retrieval paradigms with experiments over six standard document ranking benchmarks. We find that GRF improves over comparable PRF techniques by around 10% on both precision and recall-oriented measures. Nonetheless, query analysis shows that GRF and PRF have contrasting benefits, with GRF providing external context not present in first-pass retrieval, whereas PRF grounds the query to the information contained within the target corpus. Thus, we propose combining generative and pseudo-relevance feedback ranking signals to achieve the benefits of both feedback classes, which significantly increases recall over PRF methods on 95% of experiments.
Exploiting Simulated User Feedback for Conversational Search: Ranking, Rewriting, and Beyond
May 07, 2023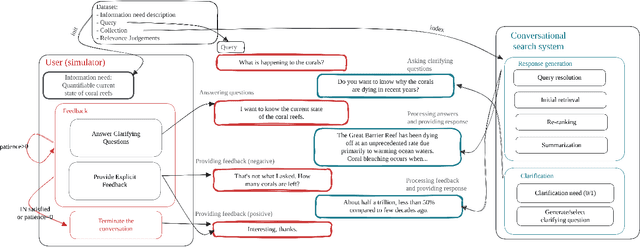


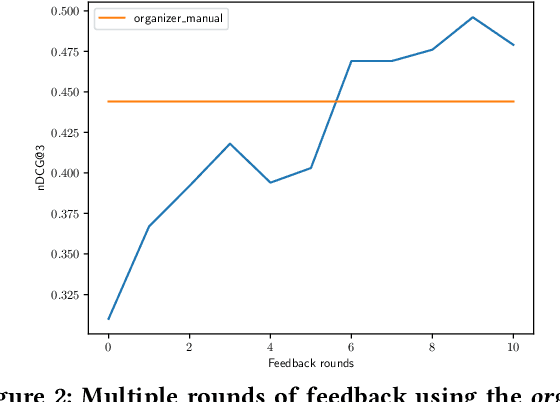
This research aims to explore various methods for assessing user feedback in mixed-initiative conversational search (CS) systems. While CS systems enjoy profuse advancements across multiple aspects, recent research fails to successfully incorporate feedback from the users. One of the main reasons for that is the lack of system-user conversational interaction data. To this end, we propose a user simulator-based framework for multi-turn interactions with a variety of mixed-initiative CS systems. Specifically, we develop a user simulator, dubbed ConvSim, that, once initialized with an information need description, is capable of providing feedback to a system's responses, as well as answering potential clarifying questions. Our experiments on a wide variety of state-of-the-art passage retrieval and neural re-ranking models show that effective utilization of user feedback can lead to 16% retrieval performance increase in terms of nDCG@3. Moreover, we observe consistent improvements as the number of feedback rounds increases (35% relative improvement in terms of nDCG@3 after three rounds). This points to a research gap in the development of specific feedback processing modules and opens a potential for significant advancements in CS. To support further research in the topic, we release over 30,000 transcripts of system-simulator interactions based on well-established CS datasets.
Generative Relevance Feedback with Large Language Models
Apr 25, 2023Current query expansion models use pseudo-relevance feedback to improve first-pass retrieval effectiveness; however, this fails when the initial results are not relevant. Instead of building a language model from retrieved results, we propose Generative Relevance Feedback (GRF) that builds probabilistic feedback models from long-form text generated from Large Language Models. We study the effective methods for generating text by varying the zero-shot generation subtasks: queries, entities, facts, news articles, documents, and essays. We evaluate GRF on document retrieval benchmarks covering a diverse set of queries and document collections, and the results show that GRF methods significantly outperform previous PRF methods. Specifically, we improve MAP between 5-19% and NDCG@10 17-24% compared to RM3 expansion, and achieve the best R@1k effectiveness on all datasets compared to state-of-the-art sparse, dense, and expansion models.
Generate, Transform, Answer: Question Specific Tool Synthesis for Tabular Data
Mar 17, 2023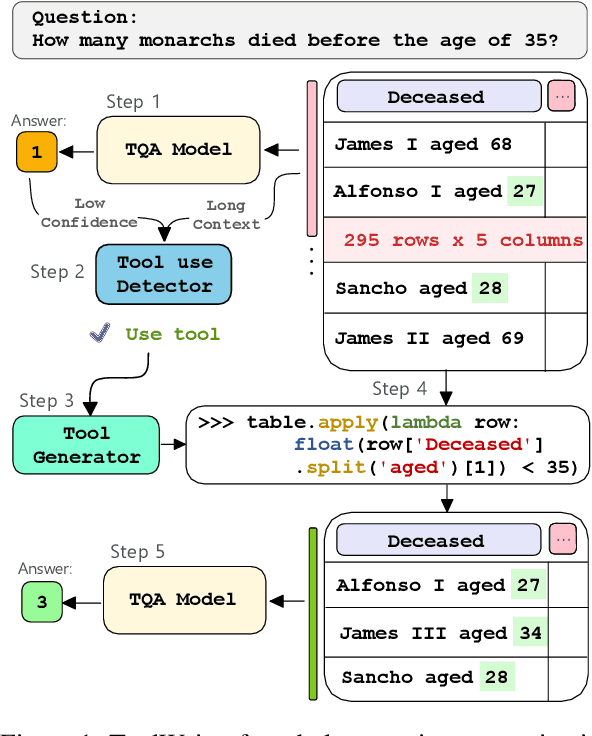
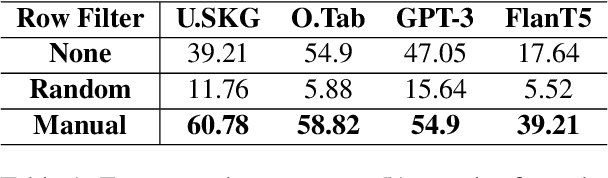
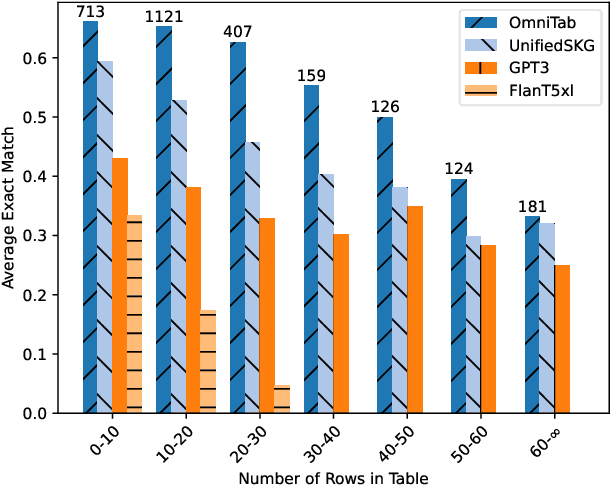
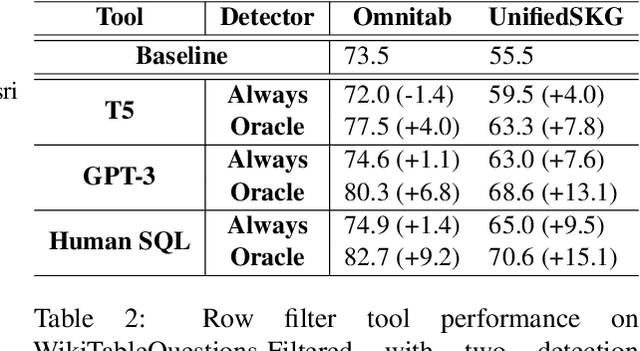
Tabular question answering (TQA) presents a challenging setting for neural systems by requiring joint reasoning of natural language with large amounts of semi-structured data. Unlike humans who use programmatic tools like filters to transform data before processing, language models in TQA process tables directly, resulting in information loss as table size increases. In this paper we propose ToolWriter to generate query specific programs and detect when to apply them to transform tables and align them with the TQA model's capabilities. Focusing ToolWriter to generate row-filtering tools improves the state-of-the-art for WikiTableQuestions and WikiSQL with the most performance gained on long tables. By investigating headroom, our work highlights the broader potential for programmatic tools combined with neural components to manipulate large amounts of structured data.