 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntities as Retrieval Signals: A Systematic Study of Coverage, Supervision, and Evaluation in Entity-Oriented Ranking
Apr 06, 2026Entity-oriented retrieval assumes that relevant documents exhibit query-relevant entities, yet evaluations report conflicting results. We show this inconsistency stems not from model failure, but from evaluation. On TREC Robust04, we evaluate six neural rerankers and 437 unsupervised configurations against BM25. Across 443 systems, none improves MAP by more than 0.05 under open-world evaluation over the full candidate set, despite strong gains under entity-restricted settings. The best configuration matches the official Robust04 best system and outperforms most neural rerankers, indicating that the architecture is not the limiting factor. Instead, the bottleneck is the entity channel: even under idealized selection, entity signals cover only 19.7\% of relevant documents, and no method achieves both high coverage and discrimination. We explain this via a distinction between Conceptual Entity Relevance (CER) -- semantic relatedness -- and Observable Entity Relevance (OER) -- corpus-grounded discriminativeness under a given linker. All supervision strategies operate at the CER level and ignore the linking environment, leading to signals that are semantically valid but not discriminative. Improving supervision therefore does not recover open-world performance: stronger signals reduce coverage without improving effectiveness. Conditional and open-world evaluation answer different questions: exploiting entity evidence versus improving retrieval under realistic linking, but are often conflated. Progress requires datasets with entity-level discriminativeness and evaluation that reports both coverage and effectiveness. Until then, conditional gains do not imply open-world effectiveness, and open-world failures do not invalidate entity-based models.
Interplay: Training Independent Simulators for Reference-Free Conversational Recommendation
Mar 19, 2026Training conversational recommender systems (CRS) requires extensive dialogue data, which is challenging to collect at scale. To address this, researchers have used simulated user-recommender conversations. Traditional simulation approaches often utilize a single large language model (LLM) that generates entire conversations with prior knowledge of the target items, leading to scripted and artificial dialogues. We propose a reference-free simulation framework that trains two independent LLMs, one as the user and one as the conversational recommender. These models interact in real-time without access to predetermined target items, but preference summaries and target attributes, enabling the recommender to genuinely infer user preferences through dialogue. This approach produces more realistic and diverse conversations that closely mirror authentic human-AI interactions. Our reference-free simulators match or exceed existing methods in quality, while offering a scalable solution for generating high-quality conversational recommendation data without constraining conversations to pre-defined target items. We conduct both quantitative and human evaluations to confirm the effectiveness of our reference-free approach.
Single-Turn LLM Reformulation Powered Multi-Stage Hybrid Re-Ranking for Tip-of-the-Tongue Known-Item Retrieval
Feb 10, 2026Retrieving known items from vague descriptions, Tip-of-the-Tongue (ToT) retrieval, remains a significant challenge. We propose using a single call to a generic 8B-parameter LLM for query reformulation, bridging the gap between ill-formed ToT queries and specific information needs. This method is particularly effective where standard Pseudo-Relevance Feedback fails due to poor initial recall. Crucially, our LLM is not fine-tuned for ToT or specific domains, demonstrating that gains stem from our prompting strategy rather than model specialization. Rewritten queries feed a multi-stage pipeline: sparse retrieval (BM25), dense/late-interaction reranking (Contriever, E5-large-v2, ColBERTv2), monoT5 cross-encoding, and list-wise reranking (Qwen 2.5 72B). Experiments on 2025 TREC-ToT datasets show that while raw queries yield poor performance, our lightweight pre-retrieval transformation improves Recall by 20.61%. Subsequent reranking improves nDCG@10 by 33.88%, MRR by 29.92%, and MAP@10 by 29.98%, offering a cost-effective intervention that unlocks the potential of downstream rankers. Code and data: https://github.com/debayan1405/TREC-TOT-2025
DyVo: Dynamic Vocabularies for Learned Sparse Retrieval with Entities
Oct 10, 2024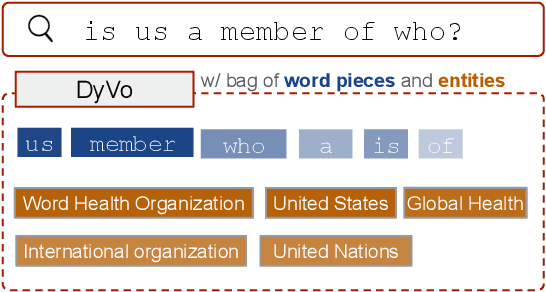
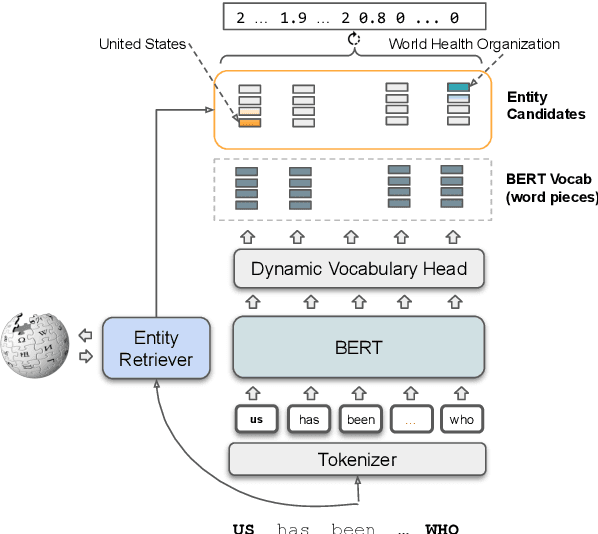

Learned Sparse Retrieval (LSR) models use vocabularies from pre-trained transformers, which often split entities into nonsensical fragments. Splitting entities can reduce retrieval accuracy and limits the model's ability to incorporate up-to-date world knowledge not included in the training data. In this work, we enhance the LSR vocabulary with Wikipedia concepts and entities, enabling the model to resolve ambiguities more effectively and stay current with evolving knowledge. Central to our approach is a Dynamic Vocabulary (DyVo) head, which leverages existing entity embeddings and an entity retrieval component that identifies entities relevant to a query or document. We use the DyVo head to generate entity weights, which are then merged with word piece weights to create joint representations for efficient indexing and retrieval using an inverted index. In experiments across three entity-rich document ranking datasets, the resulting DyVo model substantially outperforms state-of-the-art baselines.
* https://github.com/thongnt99/DyVo
Doing Personal LAPS: LLM-Augmented Dialogue Construction for Personalized Multi-Session Conversational Search
May 06, 2024The future of conversational agents will provide users with personalized information responses. However, a significant challenge in developing models is the lack of large-scale dialogue datasets that span multiple sessions and reflect real-world user preferences. Previous approaches rely on experts in a wizard-of-oz setup that is difficult to scale, particularly for personalized tasks. Our method, LAPS, addresses this by using large language models (LLMs) to guide a single human worker in generating personalized dialogues. This method has proven to speed up the creation process and improve quality. LAPS can collect large-scale, human-written, multi-session, and multi-domain conversations, including extracting user preferences. When compared to existing datasets, LAPS-produced conversations are as natural and diverse as expert-created ones, which stays in contrast with fully synthetic methods. The collected dataset is suited to train preference extraction and personalized response generation. Our results show that responses generated explicitly using extracted preferences better match user's actual preferences, highlighting the value of using extracted preferences over simple dialogue history. Overall, LAPS introduces a new method to leverage LLMs to create realistic personalized conversational data more efficiently and effectively than previous methods.
TREC iKAT 2023: A Test Collection for Evaluating Conversational and Interactive Knowledge Assistants
May 04, 2024Conversational information seeking has evolved rapidly in the last few years with the development of Large Language Models (LLMs), providing the basis for interpreting and responding in a naturalistic manner to user requests. The extended TREC Interactive Knowledge Assistance Track (iKAT) collection aims to enable researchers to test and evaluate their Conversational Search Agents (CSA). The collection contains a set of 36 personalized dialogues over 20 different topics each coupled with a Personal Text Knowledge Base (PTKB) that defines the bespoke user personas. A total of 344 turns with approximately 26,000 passages are provided as assessments on relevance, as well as additional assessments on generated responses over four key dimensions: relevance, completeness, groundedness, and naturalness. The collection challenges CSA to efficiently navigate diverse personal contexts, elicit pertinent persona information, and employ context for relevant conversations. The integration of a PTKB and the emphasis on decisional search tasks contribute to the uniqueness of this test collection, making it an essential benchmark for advancing research in conversational and interactive knowledge assistants.
DREQ: Document Re-Ranking Using Entity-based Query Understanding
Jan 11, 2024While entity-oriented neural IR models have advanced significantly, they often overlook a key nuance: the varying degrees of influence individual entities within a document have on its overall relevance. Addressing this gap, we present DREQ, an entity-oriented dense document re-ranking model. Uniquely, we emphasize the query-relevant entities within a document's representation while simultaneously attenuating the less relevant ones, thus obtaining a query-specific entity-centric document representation. We then combine this entity-centric document representation with the text-centric representation of the document to obtain a "hybrid" representation of the document. We learn a relevance score for the document using this hybrid representation. Using four large-scale benchmarks, we show that DREQ outperforms state-of-the-art neural and non-neural re-ranking methods, highlighting the effectiveness of our entity-oriented representation approach.
TREC iKAT 2023: The Interactive Knowledge Assistance Track Overview
Jan 02, 2024



Conversational Information Seeking stands as a pivotal research area with significant contributions from previous works. The TREC Interactive Knowledge Assistance Track (iKAT) builds on the foundational work of the TREC Conversational Assistance Track (CAsT). However, iKAT distinctively emphasizes the creation and research of conversational search agents that adapt responses based on user's prior interactions and present context. The challenge lies in enabling Conversational Search Agents (CSA) to incorporate this personalized context to efficiency and effectively guide users through the relevant information to them. iKAT also emphasizes decisional search tasks, where users sift through data and information to weigh up options in order to reach a conclusion or perform an action. These tasks, prevalent in everyday information-seeking decisions -- be it related to travel, health, or shopping -- often revolve around a subset of high-level information operators where queries or questions about the information space include: finding options, comparing options, identifying the pros and cons of options, etc. Given the different personas and their information need (expressed through the sequence of questions), diverse conversation trajectories will arise -- because the answers to these similar queries will be very different. In this paper, we report on the first year of TREC iKAT, describing the task, topics, data collection, and evaluation framework. We further review the submissions and summarize the findings.
Re-Rank - Expand - Repeat: Adaptive Query Expansion for Document Retrieval Using Words and Entities
Jun 29, 2023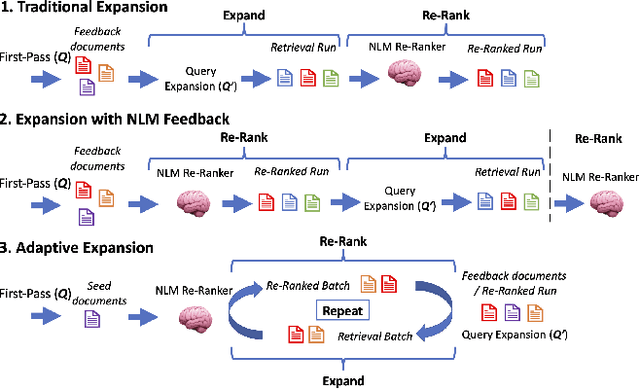
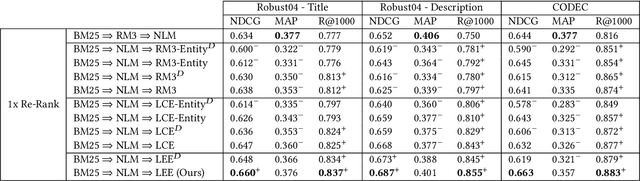

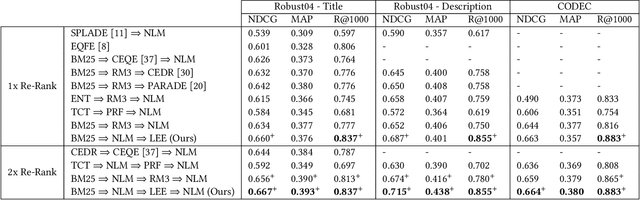
Sparse and dense pseudo-relevance feedback (PRF) approaches perform poorly on challenging queries due to low precision in first-pass retrieval. However, recent advances in neural language models (NLMs) can re-rank relevant documents to top ranks, even when few are in the re-ranking pool. This paper first addresses the problem of poor pseudo-relevance feedback by simply applying re-ranking prior to query expansion and re-executing this query. We find that this change alone can improve the retrieval effectiveness of sparse and dense PRF approaches by 5-8%. Going further, we propose a new expansion model, Latent Entity Expansion (LEE), a fine-grained word and entity-based relevance modelling incorporating localized features. Finally, we include an "adaptive" component to the retrieval process, which iteratively refines the re-ranking pool during scoring using the expansion model, i.e. we "re-rank - expand - repeat". Using LEE, we achieve (to our knowledge) the best NDCG, MAP and R@1000 results on the TREC Robust 2004 and CODEC adhoc document datasets, demonstrating a significant advancement in expansion effectiveness.
GRM: Generative Relevance Modeling Using Relevance-Aware Sample Estimation for Document Retrieval
Jun 16, 2023


Recent studies show that Generative Relevance Feedback (GRF), using text generated by Large Language Models (LLMs), can enhance the effectiveness of query expansion. However, LLMs can generate irrelevant information that harms retrieval effectiveness. To address this, we propose Generative Relevance Modeling (GRM) that uses Relevance-Aware Sample Estimation (RASE) for more accurate weighting of expansion terms. Specifically, we identify similar real documents for each generated document and use a neural re-ranker to estimate their relevance. Experiments on three standard document ranking benchmarks show that GRM improves MAP by 6-9% and R@1k by 2-4%, surpassing previous methods.