 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRS Arena: Crowdsourced Benchmarking of Conversational Recommender Systems
Dec 13, 2024



We introduce CRS Arena, a research platform for scalable benchmarking of Conversational Recommender Systems (CRS) based on human feedback. The platform displays pairwise battles between anonymous conversational recommender systems, where users interact with the systems one after the other before declaring either a winner or a draw. CRS Arena collects conversations and user feedback, providing a foundation for reliable evaluation and ranking of CRSs. We conduct experiments with CRS Arena on both open and closed crowdsourcing platforms, confirming that both setups produce highly correlated rankings of CRSs and conversations with similar characteristics. We release CRSArena-Dial, a dataset of 474 conversations and their corresponding user feedback, along with a preliminary ranking of the systems based on the Elo rating system. The platform is accessible at https://iai-group-crsarena.hf.space/.
Doing Personal LAPS: LLM-Augmented Dialogue Construction for Personalized Multi-Session Conversational Search
May 06, 2024The future of conversational agents will provide users with personalized information responses. However, a significant challenge in developing models is the lack of large-scale dialogue datasets that span multiple sessions and reflect real-world user preferences. Previous approaches rely on experts in a wizard-of-oz setup that is difficult to scale, particularly for personalized tasks. Our method, LAPS, addresses this by using large language models (LLMs) to guide a single human worker in generating personalized dialogues. This method has proven to speed up the creation process and improve quality. LAPS can collect large-scale, human-written, multi-session, and multi-domain conversations, including extracting user preferences. When compared to existing datasets, LAPS-produced conversations are as natural and diverse as expert-created ones, which stays in contrast with fully synthetic methods. The collected dataset is suited to train preference extraction and personalized response generation. Our results show that responses generated explicitly using extracted preferences better match user's actual preferences, highlighting the value of using extracted preferences over simple dialogue history. Overall, LAPS introduces a new method to leverage LLMs to create realistic personalized conversational data more efficiently and effectively than previous methods.
Personal Entity, Concept, and Named Entity Linking in Conversations
Jun 15, 2022



Building conversational agents that can have natural and knowledge-grounded interactions with humans requires understanding user utterances. Entity Linking (EL) is an effective and widely used method for understanding natural language text and connecting it to external knowledge. It is, however, shown that existing EL methods developed for annotating documents are suboptimal for conversations, where personal entities (e.g., "my cars") and concepts are essential for understanding user utterances. In this paper, we introduce a collection and a tool for entity linking in conversations. We collect EL annotations for 1327 conversational utterances, consisting of links to named entities, concepts, and personal entities. The dataset is used for training our toolkit for conversational entity linking, CREL. Unlike existing EL methods, CREL is developed to identify both named entities and concepts. It also utilizes coreference resolution techniques to identify personal entities and references to the explicit entity mentions in the conversations. We compare CREL with state-of-the-art techniques and show that it outperforms all existing baselines.
Conversational Entity Linking: Problem Definition and Datasets
May 11, 2021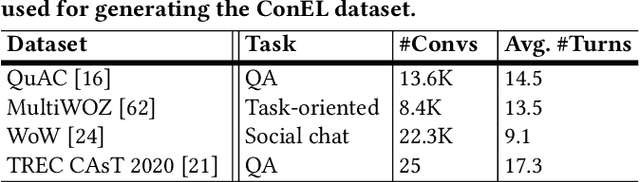
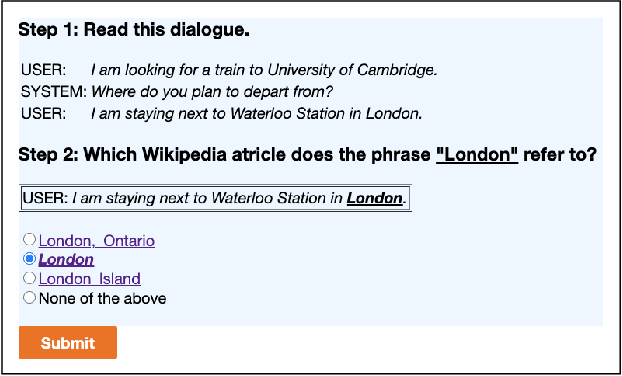

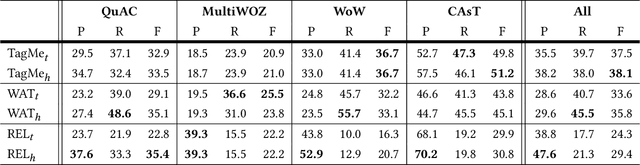
Machine understanding of user utterances in conversational systems is of utmost importance for enabling engaging and meaningful conversations with users. Entity Linking (EL) is one of the means of text understanding, with proven efficacy for various downstream tasks in information retrieval. In this paper, we study entity linking for conversational systems. To develop a better understanding of what EL in a conversational setting entails, we analyze a large number of dialogues from existing conversational datasets and annotate references to concepts, named entities, and personal entities using crowdsourcing. Based on the annotated dialogues, we identify the main characteristics of conversational entity linking. Further, we report on the performance of traditional EL systems on our Conversational Entity Linking dataset, ConEL, and present an extension to these methods to better fit the conversational setting. The resources released with this paper include annotated datasets, detailed descriptions of crowdsourcing setups, as well as the annotations produced by various EL systems. These new resources allow for an investigation of how the role of entities in conversations is different from that in documents or isolated short text utterances like queries and tweets, and complement existing conversational datasets.