 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTotal Recall QA: A Verifiable Evaluation Suite for Deep Research Agents
Mar 19, 2026Deep research agents have emerged as LLM-based systems designed to perform multi-step information seeking and reasoning over large, open-domain sources to answer complex questions by synthesizing information from multiple information sources. Given the complexity of the task and despite various recent efforts, evaluation of deep research agents remains fundamentally challenging. This paper identifies a list of requirements and optional properties for evaluating deep research agents. We observe that existing benchmarks do not satisfy all identified requirements. Inspired by prior research on TREC Total Recall Tracks, we introduce the task of Total Recall Question Answering and develop a framework for deep research agents evaluation that satisfies the identified criteria. Our framework constructs single-answer, total recall queries with precise evaluation and relevance judgments derived from a structured knowledge base paired with a text corpus, enabling large-scale data construction. Using this framework, we build TRQA, a deep research benchmark constructed from Wikidata-Wikipedia as a real-world source and a synthetically generated e-commerce knowledge base and corpus to mitigate the effects of data contamination. We benchmark the collection with representative retriever and deep research models and establish baseline retrieval and end-to-end results for future comparative evaluation.
OrLog: Resolving Complex Queries with LLMs and Probabilistic Reasoning
Jan 30, 2026Resolving complex information needs that come with multiple constraints should consider enforcing the logical operators encoded in the query (i.e., conjunction, disjunction, negation) on the candidate answer set. Current retrieval systems either ignore these constraints in neural embeddings or approximate them in a generative reasoning process that can be inconsistent and unreliable. Although well-suited to structured reasoning, existing neuro-symbolic approaches remain confined to formal logic or mathematics problems as they often assume unambiguous queries and access to complete evidence, conditions rarely met in information retrieval. To bridge this gap, we introduce OrLog, a neuro-symbolic retrieval framework that decouples predicate-level plausibility estimation from logical reasoning: a large language model (LLM) provides plausibility scores for atomic predicates in one decoding-free forward pass, from which a probabilistic reasoning engine derives the posterior probability of query satisfaction. We evaluate OrLog across multiple backbone LLMs, varying levels of access to external knowledge, and a range of logical constraints, and compare it against base retrievers and LLM-as-reasoner methods. Provided with entity descriptions, OrLog can significantly boost top-rank precision compared to LLM reasoning with larger gains on disjunctive queries. OrLog is also more efficient, cutting mean tokens by $\sim$90\% per query-entity pair. These results demonstrate that generation-free predicate plausibility estimation combined with probabilistic reasoning enables constraint-aware retrieval that outperforms monolithic reasoning while using far fewer tokens.
Why Uncertainty Estimation Methods Fall Short in RAG: An Axiomatic Analysis
May 12, 2025Large Language Models (LLMs) are valued for their strong performance across various tasks, but they also produce inaccurate or misleading outputs. Uncertainty Estimation (UE) quantifies the model's confidence and helps users assess response reliability. However, existing UE methods have not been thoroughly examined in scenarios like Retrieval-Augmented Generation (RAG), where the input prompt includes non-parametric knowledge. This paper shows that current UE methods cannot reliably assess correctness in the RAG setting. We further propose an axiomatic framework to identify deficiencies in existing methods and guide the development of improved approaches. Our framework introduces five constraints that an effective UE method should meet after incorporating retrieved documents into the LLM's prompt. Experimental results reveal that no existing UE method fully satisfies all the axioms, explaining their suboptimal performance in RAG. We further introduce a simple yet effective calibration function based on our framework, which not only satisfies more axioms than baseline methods but also improves the correlation between uncertainty estimates and correctness.
LLM-Evaluation Tropes: Perspectives on the Validity of LLM-Evaluations
Apr 27, 2025Large Language Models (LLMs) are increasingly used to evaluate information retrieval (IR) systems, generating relevance judgments traditionally made by human assessors. Recent empirical studies suggest that LLM-based evaluations often align with human judgments, leading some to suggest that human judges may no longer be necessary, while others highlight concerns about judgment reliability, validity, and long-term impact. As IR systems begin incorporating LLM-generated signals, evaluation outcomes risk becoming self-reinforcing, potentially leading to misleading conclusions. This paper examines scenarios where LLM-evaluators may falsely indicate success, particularly when LLM-based judgments influence both system development and evaluation. We highlight key risks, including bias reinforcement, reproducibility challenges, and inconsistencies in assessment methodologies. To address these concerns, we propose tests to quantify adverse effects, guardrails, and a collaborative framework for constructing reusable test collections that integrate LLM judgments responsibly. By providing perspectives from academia and industry, this work aims to establish best practices for the principled use of LLMs in IR evaluation.
Adaptive Orchestration of Modular Generative Information Access Systems
Apr 24, 2025Advancements in large language models (LLMs) have driven the emergence of complex new systems to provide access to information, that we will collectively refer to as modular generative information access (GenIA) systems. They integrate a broad and evolving range of specialized components, including LLMs, retrieval models, and a heterogeneous set of sources and tools. While modularity offers flexibility, it also raises critical challenges: How can we systematically characterize the space of possible modules and their interactions? How can we automate and optimize interactions among these heterogeneous components? And, how do we enable this modular system to dynamically adapt to varying user query requirements and evolving module capabilities? In this perspective paper, we argue that the architecture of future modular generative information access systems will not just assemble powerful components, but enable a self-organizing system through real-time adaptive orchestration -- where components' interactions are dynamically configured for each user input, maximizing information relevance while minimizing computational overhead. We give provisional answers to the questions raised above with a roadmap that depicts the key principles and methods for designing such an adaptive modular system. We identify pressing challenges, and propose avenues for addressing them in the years ahead. This perspective urges the IR community to rethink modular system designs for developing adaptive, self-optimizing, and future-ready architectures that evolve alongside their rapidly advancing underlying technologies.
SPILL: Domain-Adaptive Intent Clustering based on Selection and Pooling with Large Language Models
Mar 19, 2025In this paper, we propose Selection and Pooling with Large Language Models (SPILL), an intuitive and domain-adaptive method for intent clustering without fine-tuning. Existing embeddings-based clustering methods rely on a few labeled examples or unsupervised fine-tuning to optimize results for each new dataset, which makes them less generalizable to multiple datasets. Our goal is to make these existing embedders more generalizable to new domain datasets without further fine-tuning. Inspired by our theoretical derivation and simulation results on the effectiveness of sampling and pooling techniques, we view the clustering task as a small-scale selection problem. A good solution to this problem is associated with better clustering performance. Accordingly, we propose a two-stage approach: First, for each utterance (referred to as the seed), we derive its embedding using an existing embedder. Then, we apply a distance metric to select a pool of candidates close to the seed. Because the embedder is not optimized for new datasets, in the second stage, we use an LLM to further select utterances from these candidates that share the same intent as the seed. Finally, we pool these selected candidates with the seed to derive a refined embedding for the seed. We found that our method generally outperforms directly using an embedder, and it achieves comparable results to other state-of-the-art studies, even those that use much larger models and require fine-tuning, showing its strength and efficiency. Our results indicate that our method enables existing embedders to be further improved without additional fine-tuning, making them more adaptable to new domain datasets. Additionally, viewing the clustering task as a small-scale selection problem gives the potential of using LLMs to customize clustering tasks according to the user's goals.
Large Physics Models: Towards a collaborative approach with Large Language Models and Foundation Models
Jan 09, 2025

This paper explores ideas and provides a potential roadmap for the development and evaluation of physics-specific large-scale AI models, which we call Large Physics Models (LPMs). These models, based on foundation models such as Large Language Models (LLMs) - trained on broad data - are tailored to address the demands of physics research. LPMs can function independently or as part of an integrated framework. This framework can incorporate specialized tools, including symbolic reasoning modules for mathematical manipulations, frameworks to analyse specific experimental and simulated data, and mechanisms for synthesizing theories and scientific literature. We begin by examining whether the physics community should actively develop and refine dedicated models, rather than relying solely on commercial LLMs. We then outline how LPMs can be realized through interdisciplinary collaboration among experts in physics, computer science, and philosophy of science. To integrate these models effectively, we identify three key pillars: Development, Evaluation, and Philosophical Reflection. Development focuses on constructing models capable of processing physics texts, mathematical formulations, and diverse physical data. Evaluation assesses accuracy and reliability by testing and benchmarking. Finally, Philosophical Reflection encompasses the analysis of broader implications of LLMs in physics, including their potential to generate new scientific understanding and what novel collaboration dynamics might arise in research. Inspired by the organizational structure of experimental collaborations in particle physics, we propose a similarly interdisciplinary and collaborative approach to building and refining Large Physics Models. This roadmap provides specific objectives, defines pathways to achieve them, and identifies challenges that must be addressed to realise physics-specific large scale AI models.
CRS Arena: Crowdsourced Benchmarking of Conversational Recommender Systems
Dec 13, 2024



We introduce CRS Arena, a research platform for scalable benchmarking of Conversational Recommender Systems (CRS) based on human feedback. The platform displays pairwise battles between anonymous conversational recommender systems, where users interact with the systems one after the other before declaring either a winner or a draw. CRS Arena collects conversations and user feedback, providing a foundation for reliable evaluation and ranking of CRSs. We conduct experiments with CRS Arena on both open and closed crowdsourcing platforms, confirming that both setups produce highly correlated rankings of CRSs and conversations with similar characteristics. We release CRSArena-Dial, a dataset of 474 conversations and their corresponding user feedback, along with a preliminary ranking of the systems based on the Elo rating system. The platform is accessible at https://iai-group-crsarena.hf.space/.
Generate then Refine: Data Augmentation for Zero-shot Intent Detection
Oct 02, 2024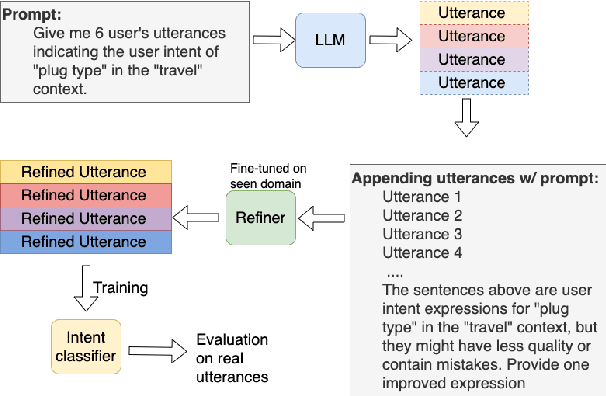
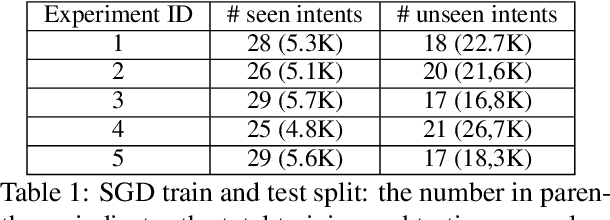
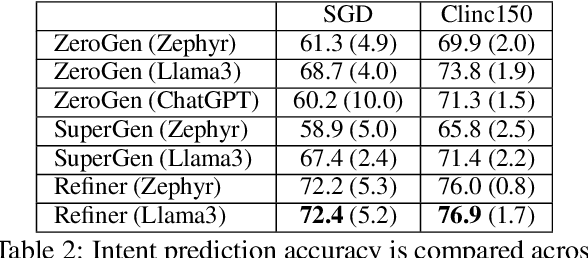
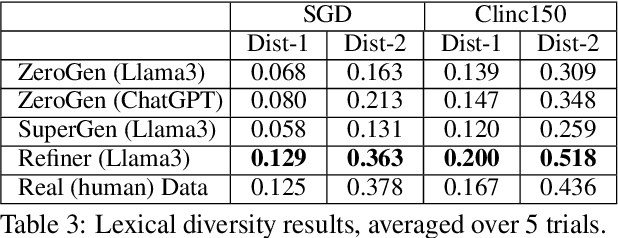
In this short paper we propose a data augmentation method for intent detection in zero-resource domains. Existing data augmentation methods rely on few labelled examples for each intent category, which can be expensive in settings with many possible intents. We use a two-stage approach: First, we generate utterances for intent labels using an open-source large language model in a zero-shot setting. Second, we develop a smaller sequence-to-sequence model (the Refiner), to improve the generated utterances. The Refiner is fine-tuned on seen domains and then applied to unseen domains. We evaluate our method by training an intent classifier on the generated data, and evaluating it on real (human) data. We find that the Refiner significantly improves the data utility and diversity over the zero-shot LLM baseline for unseen domains and over common baseline approaches. Our results indicate that a two-step approach of a generative LLM in zero-shot setting and a smaller sequence-to-sequence model can provide high-quality data for intent detection.
Real World Conversational Entity Linking Requires More Than Zeroshots
Sep 02, 2024



Entity linking (EL) in conversations faces notable challenges in practical applications, primarily due to the scarcity of entity-annotated conversational datasets and sparse knowledge bases (KB) containing domain-specific, long-tail entities. We designed targeted evaluation scenarios to measure the efficacy of EL models under resource constraints. Our evaluation employs two KBs: Fandom, exemplifying real-world EL complexities, and the widely used Wikipedia. First, we assess EL models' ability to generalize to a new unfamiliar KB using Fandom and a novel zero-shot conversational entity linking dataset that we curated based on Reddit discussions on Fandom entities. We then evaluate the adaptability of EL models to conversational settings without prior training. Our results indicate that current zero-shot EL models falter when introduced to new, domain-specific KBs without prior training, significantly dropping in performance. Our findings reveal that previous evaluation approaches fall short of capturing real-world complexities for zero-shot EL, highlighting the necessity for new approaches to design and assess conversational EL models to adapt to limited resources. The evaluation setup and the dataset proposed in this research are made publicly available.