 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPILL: Domain-Adaptive Intent Clustering based on Selection and Pooling with Large Language Models
Mar 19, 2025In this paper, we propose Selection and Pooling with Large Language Models (SPILL), an intuitive and domain-adaptive method for intent clustering without fine-tuning. Existing embeddings-based clustering methods rely on a few labeled examples or unsupervised fine-tuning to optimize results for each new dataset, which makes them less generalizable to multiple datasets. Our goal is to make these existing embedders more generalizable to new domain datasets without further fine-tuning. Inspired by our theoretical derivation and simulation results on the effectiveness of sampling and pooling techniques, we view the clustering task as a small-scale selection problem. A good solution to this problem is associated with better clustering performance. Accordingly, we propose a two-stage approach: First, for each utterance (referred to as the seed), we derive its embedding using an existing embedder. Then, we apply a distance metric to select a pool of candidates close to the seed. Because the embedder is not optimized for new datasets, in the second stage, we use an LLM to further select utterances from these candidates that share the same intent as the seed. Finally, we pool these selected candidates with the seed to derive a refined embedding for the seed. We found that our method generally outperforms directly using an embedder, and it achieves comparable results to other state-of-the-art studies, even those that use much larger models and require fine-tuning, showing its strength and efficiency. Our results indicate that our method enables existing embedders to be further improved without additional fine-tuning, making them more adaptable to new domain datasets. Additionally, viewing the clustering task as a small-scale selection problem gives the potential of using LLMs to customize clustering tasks according to the user's goals.
Generate then Refine: Data Augmentation for Zero-shot Intent Detection
Oct 02, 2024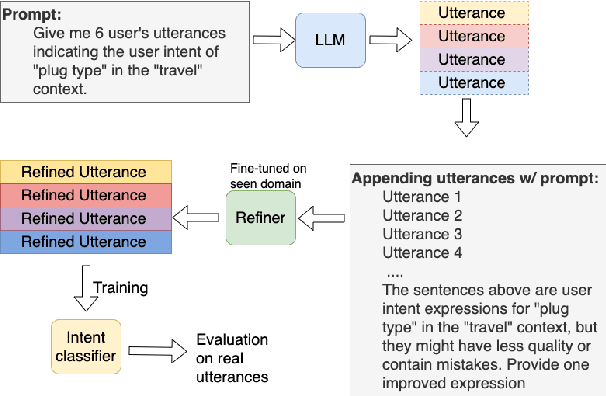
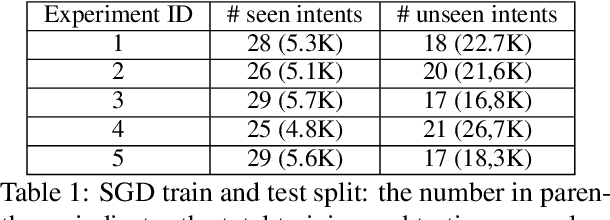
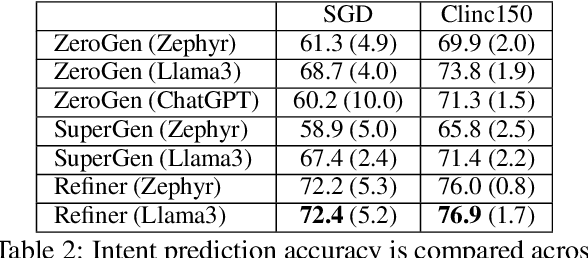
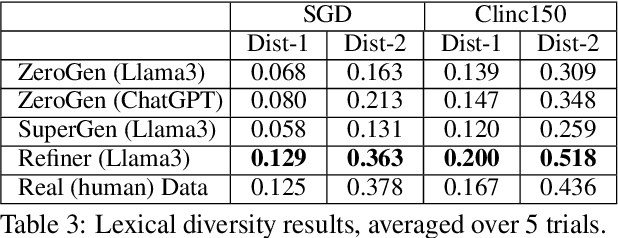
In this short paper we propose a data augmentation method for intent detection in zero-resource domains. Existing data augmentation methods rely on few labelled examples for each intent category, which can be expensive in settings with many possible intents. We use a two-stage approach: First, we generate utterances for intent labels using an open-source large language model in a zero-shot setting. Second, we develop a smaller sequence-to-sequence model (the Refiner), to improve the generated utterances. The Refiner is fine-tuned on seen domains and then applied to unseen domains. We evaluate our method by training an intent classifier on the generated data, and evaluating it on real (human) data. We find that the Refiner significantly improves the data utility and diversity over the zero-shot LLM baseline for unseen domains and over common baseline approaches. Our results indicate that a two-step approach of a generative LLM in zero-shot setting and a smaller sequence-to-sequence model can provide high-quality data for intent detection.