 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Makes the Difference: Evaluating How Different Memory Roles Shape Conversational Agents
Jun 24, 2026Prior research on memory mechanism in RAG-based conversational system has emphasized how memory is stored and retrieved. However, far less is known about how memories with different functional roles influence response quality. Specifically, how they shape an agent's responses under varying conversational contexts and whether they lead to substantively different response behaviors. Existing evaluations in conversational system are also largely reference-based, insufficiently capturing the nuances in responses that may address users' preferences differently. In this work, we probe the impact of different memory types in shaping agents' responses. We present a fine-grained taxonomy of conversational memory, classify retrieved memories into different role types, and design a user-centric evaluation framework that simulates user perspectives. Through comparative experiments on long-term datasets and frontier LLMs, our analysis reveal many differentiated effects of memories: e.g., clarifying memory improves responses' factual accuracy and constraint awareness, making them more correct and personalized; irrelevant memory reduces topic relevance and degrades constraint awareness. Despite the power of frontier LLMs, these findings shed light on how different memory types can be leveraged to produce more personalized responses and inspire further research in this direction.
Overview of the TREC 2025 Retrieval Augmented Generation (RAG) Track
Mar 10, 2026The second edition of the TREC Retrieval Augmented Generation (RAG) Track advances research on systems that integrate retrieval and generation to address complex, real-world information needs. Building on the foundation of the inaugural 2024 track, this year's challenge introduces long, multi-sentence narrative queries to better reflect the deep search task with the growing demand for reasoning-driven responses. Participants are tasked with designing pipelines that combine retrieval and generation while ensuring transparency and factual grounding. The track leverages the MS MARCO V2.1 corpus and employs a multi-layered evaluation framework encompassing relevance assessment, response completeness, attribution verification, and agreement analysis. By emphasizing multi-faceted narratives and attribution-rich answers from over 150 submissions this year, the TREC 2025 RAG Track aims to foster innovation in creating trustworthy, context-aware systems for retrieval augmented generation.
Beyond Output Critique: Self-Correction via Task Distillation
Jan 31, 2026Large language models (LLMs) have shown promising self-correction abilities, where iterative refinement improves the quality of generated responses. However, most existing approaches operate at the level of output critique, patching surface errors while often failing to correct deeper reasoning flaws. We propose SELF-THOUGHT, a framework that introduces an intermediate step of task abstraction before solution refinement. Given an input and an initial response, the model first distills the task into a structured template that captures key variables, constraints, and problem structure. This abstraction then guides solution instantiation, grounding subsequent responses in a clearer understanding of the task and reducing error propagation. Crucially, we show that these abstractions can be transferred across models: templates generated by larger models can serve as structured guides for smaller LLMs, which typically struggle with intrinsic self-correction. By reusing distilled task structures, smaller models achieve more reliable refinements without heavy fine-tuning or reliance on external verifiers. Experiments across diverse reasoning tasks demonstrate that SELF-THOUGHT improves accuracy, robustness, and generalization for both large and small models, offering a scalable path toward more reliable self-correcting language systems.
Fine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
Jan 06, 2026In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
All Claims Are Equal, but Some Claims Are More Equal Than Others: Importance-Sensitive Factuality Evaluation of LLM Generations
Oct 08, 2025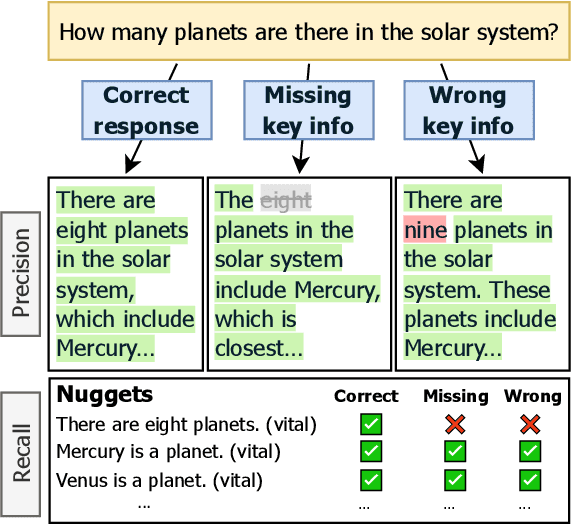
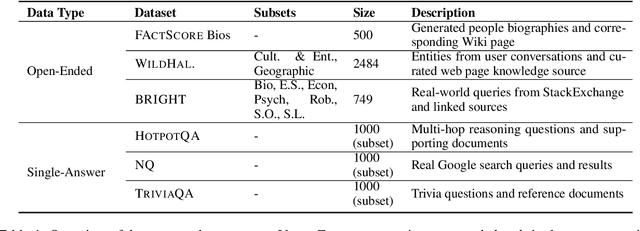
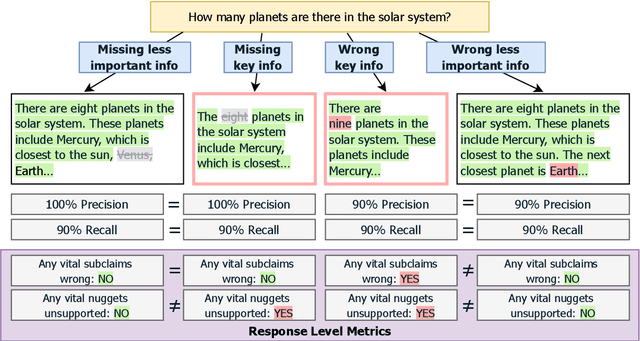

Existing methods for evaluating the factuality of large language model (LLM) responses treat all claims as equally important. This results in misleading evaluations when vital information is missing or incorrect as it receives the same weight as peripheral details, raising the question: how can we reliably detect such differences when there are errors in key information? Current approaches that measure factuality tend to be insensitive to omitted or false key information. To investigate this lack of sensitivity, we construct VITALERRORS, a benchmark of 6,733 queries with minimally altered LLM responses designed to omit or falsify key information. Using this dataset, we demonstrate the insensitivities of existing evaluation metrics to key information errors. To address this gap, we introduce VITAL, a set of metrics that provide greater sensitivity in measuring the factuality of responses by incorporating the relevance and importance of claims with respect to the query. Our analysis demonstrates that VITAL metrics more reliably detect errors in key information than previous methods. Our dataset, metrics, and analysis provide a foundation for more accurate and robust assessment of LLM factuality.
Towards Understanding Bias in Synthetic Data for Evaluation
Jun 12, 2025Test collections are crucial for evaluating Information Retrieval (IR) systems. Creating a diverse set of user queries for these collections can be challenging, and obtaining relevance judgments, which indicate how well retrieved documents match a query, is often costly and resource-intensive. Recently, generating synthetic datasets using Large Language Models (LLMs) has gained attention in various applications. While previous work has used LLMs to generate synthetic queries or documents to improve ranking models, using LLMs to create synthetic test collections is still relatively unexplored. Previous work~\cite{rahmani2024synthetic} showed that synthetic test collections have the potential to be used for system evaluation, however, more analysis is needed to validate this claim. In this paper, we thoroughly investigate the reliability of synthetic test collections constructed using LLMs, where LLMs are used to generate synthetic queries, labels, or both. In particular, we examine the potential biases that might occur when such test collections are used for evaluation. We first empirically show the presence of such bias in evaluation results and analyse the effects it might have on system evaluation. We further validate the presence of such bias using a linear mixed-effects model. Our analysis shows that while the effect of bias present in evaluation results obtained using synthetic test collections could be significant, for e.g.~computing absolute system performance, its effect may not be as significant in comparing relative system performance. Codes and data are available at: https://github.com/rahmanidashti/BiasSyntheticData.
LLM-Evaluation Tropes: Perspectives on the Validity of LLM-Evaluations
Apr 27, 2025Large Language Models (LLMs) are increasingly used to evaluate information retrieval (IR) systems, generating relevance judgments traditionally made by human assessors. Recent empirical studies suggest that LLM-based evaluations often align with human judgments, leading some to suggest that human judges may no longer be necessary, while others highlight concerns about judgment reliability, validity, and long-term impact. As IR systems begin incorporating LLM-generated signals, evaluation outcomes risk becoming self-reinforcing, potentially leading to misleading conclusions. This paper examines scenarios where LLM-evaluators may falsely indicate success, particularly when LLM-based judgments influence both system development and evaluation. We highlight key risks, including bias reinforcement, reproducibility challenges, and inconsistencies in assessment methodologies. To address these concerns, we propose tests to quantify adverse effects, guardrails, and a collaborative framework for constructing reusable test collections that integrate LLM judgments responsibly. By providing perspectives from academia and industry, this work aims to establish best practices for the principled use of LLMs in IR evaluation.
The Great Nugget Recall: Automating Fact Extraction and RAG Evaluation with Large Language Models
Apr 21, 2025



Large Language Models (LLMs) have significantly enhanced the capabilities of information access systems, especially with retrieval-augmented generation (RAG). Nevertheless, the evaluation of RAG systems remains a barrier to continued progress, a challenge we tackle in this work by proposing an automatic evaluation framework that is validated against human annotations. We believe that the nugget evaluation methodology provides a solid foundation for evaluating RAG systems. This approach, originally developed for the TREC Question Answering (QA) Track in 2003, evaluates systems based on atomic facts that should be present in good answers. Our efforts focus on "refactoring" this methodology, where we describe the AutoNuggetizer framework that specifically applies LLMs to both automatically create nuggets and automatically assign nuggets to system answers. In the context of the TREC 2024 RAG Track, we calibrate a fully automatic approach against strategies where nuggets are created manually or semi-manually by human assessors and then assigned manually to system answers. Based on results from a community-wide evaluation, we observe strong agreement at the run level between scores derived from fully automatic nugget evaluation and human-based variants. The agreement is stronger when individual framework components such as nugget assignment are automated independently. This suggests that our evaluation framework provides tradeoffs between effort and quality that can be used to guide the development of future RAG systems. However, further research is necessary to refine our approach, particularly in establishing robust per-topic agreement to diagnose system failures effectively.
Support Evaluation for the TREC 2024 RAG Track: Comparing Human versus LLM Judges
Apr 21, 2025Retrieval-augmented generation (RAG) enables large language models (LLMs) to generate answers with citations from source documents containing "ground truth", thereby reducing system hallucinations. A crucial factor in RAG evaluation is "support", whether the information in the cited documents supports the answer. To this end, we conducted a large-scale comparative study of 45 participant submissions on 36 topics to the TREC 2024 RAG Track, comparing an automatic LLM judge (GPT-4o) against human judges for support assessment. We considered two conditions: (1) fully manual assessments from scratch and (2) manual assessments with post-editing of LLM predictions. Our results indicate that for 56% of the manual from-scratch assessments, human and GPT-4o predictions match perfectly (on a three-level scale), increasing to 72% in the manual with post-editing condition. Furthermore, by carefully analyzing the disagreements in an unbiased study, we found that an independent human judge correlates better with GPT-4o than a human judge, suggesting that LLM judges can be a reliable alternative for support assessment. To conclude, we provide a qualitative analysis of human and GPT-4o errors to help guide future iterations of support assessment.
Judging the Judges: A Collection of LLM-Generated Relevance Judgements
Feb 19, 2025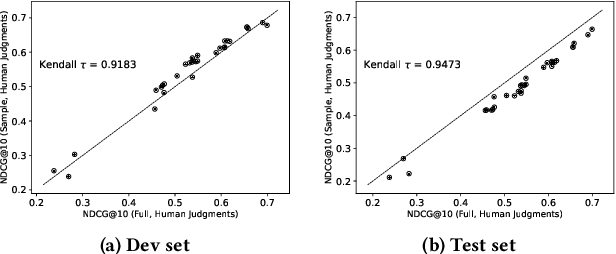
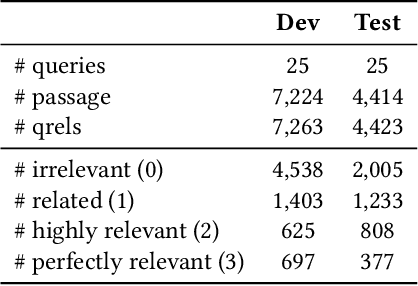
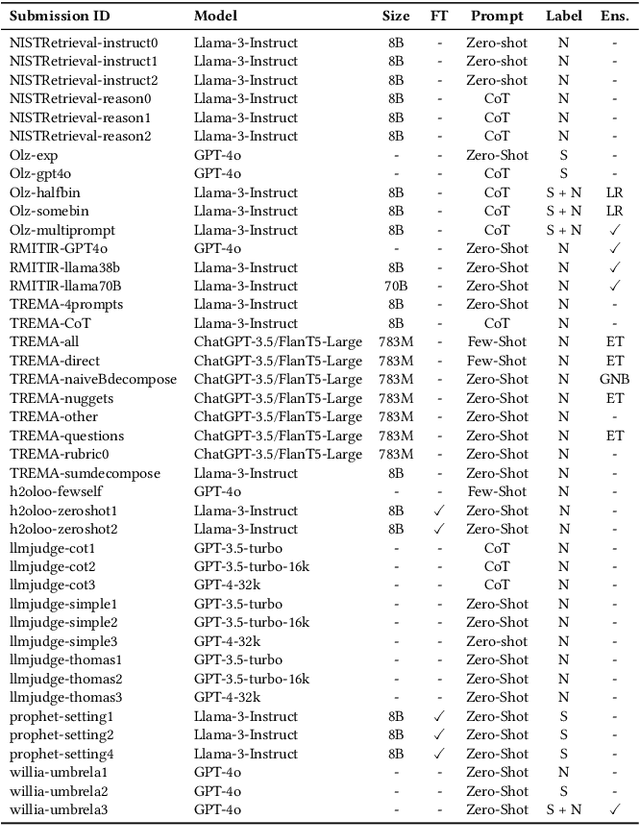
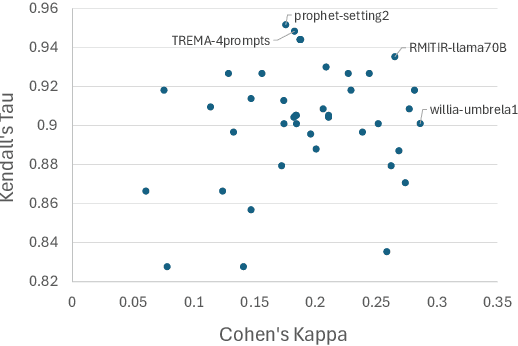
Using Large Language Models (LLMs) for relevance assessments offers promising opportunities to improve Information Retrieval (IR), Natural Language Processing (NLP), and related fields. Indeed, LLMs hold the promise of allowing IR experimenters to build evaluation collections with a fraction of the manual human labor currently required. This could help with fresh topics on which there is still limited knowledge and could mitigate the challenges of evaluating ranking systems in low-resource scenarios, where it is challenging to find human annotators. Given the fast-paced recent developments in the domain, many questions concerning LLMs as assessors are yet to be answered. Among the aspects that require further investigation, we can list the impact of various components in a relevance judgment generation pipeline, such as the prompt used or the LLM chosen. This paper benchmarks and reports on the results of a large-scale automatic relevance judgment evaluation, the LLMJudge challenge at SIGIR 2024, where different relevance assessment approaches were proposed. In detail, we release and benchmark 42 LLM-generated labels of the TREC 2023 Deep Learning track relevance judgments produced by eight international teams who participated in the challenge. Given their diverse nature, these automatically generated relevance judgments can help the community not only investigate systematic biases caused by LLMs but also explore the effectiveness of ensemble models, analyze the trade-offs between different models and human assessors, and advance methodologies for improving automated evaluation techniques. The released resource is available at the following link: https://llm4eval.github.io/LLMJudge-benchmark/