 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the TREC 2025 Retrieval Augmented Generation (RAG) Track
Mar 10, 2026The second edition of the TREC Retrieval Augmented Generation (RAG) Track advances research on systems that integrate retrieval and generation to address complex, real-world information needs. Building on the foundation of the inaugural 2024 track, this year's challenge introduces long, multi-sentence narrative queries to better reflect the deep search task with the growing demand for reasoning-driven responses. Participants are tasked with designing pipelines that combine retrieval and generation while ensuring transparency and factual grounding. The track leverages the MS MARCO V2.1 corpus and employs a multi-layered evaluation framework encompassing relevance assessment, response completeness, attribution verification, and agreement analysis. By emphasizing multi-faceted narratives and attribution-rich answers from over 150 submissions this year, the TREC 2025 RAG Track aims to foster innovation in creating trustworthy, context-aware systems for retrieval augmented generation.
EnronQA: Towards Personalized RAG over Private Documents
May 01, 2025Retrieval Augmented Generation (RAG) has become one of the most popular methods for bringing knowledge-intensive context to large language models (LLM) because of its ability to bring local context at inference time without the cost or data leakage risks associated with fine-tuning. A clear separation of private information from the LLM training has made RAG the basis for many enterprise LLM workloads as it allows the company to augment LLM's understanding using customers' private documents. Despite its popularity for private documents in enterprise deployments, current RAG benchmarks for validating and optimizing RAG pipelines draw their corpora from public data such as Wikipedia or generic web pages and offer little to no personal context. Seeking to empower more personal and private RAG we release the EnronQA benchmark, a dataset of 103,638 emails with 528,304 question-answer pairs across 150 different user inboxes. EnronQA enables better benchmarking of RAG pipelines over private data and allows for experimentation on the introduction of personalized retrieval settings over realistic data. Finally, we use EnronQA to explore the tradeoff in memorization and retrieval when reasoning over private documents.
ColBERT-serve: Efficient Multi-Stage Memory-Mapped Scoring
Apr 21, 2025We study serving retrieval models, specifically late interaction models like ColBERT, to many concurrent users at once and under a small budget, in which the index may not fit in memory. We present ColBERT-serve, a novel serving system that applies a memory-mapping strategy to the ColBERT index, reducing RAM usage by 90% and permitting its deployment on cheap servers, and incorporates a multi-stage architecture with hybrid scoring, reducing ColBERT's query latency and supporting many concurrent queries in parallel.
Support Evaluation for the TREC 2024 RAG Track: Comparing Human versus LLM Judges
Apr 21, 2025Retrieval-augmented generation (RAG) enables large language models (LLMs) to generate answers with citations from source documents containing "ground truth", thereby reducing system hallucinations. A crucial factor in RAG evaluation is "support", whether the information in the cited documents supports the answer. To this end, we conducted a large-scale comparative study of 45 participant submissions on 36 topics to the TREC 2024 RAG Track, comparing an automatic LLM judge (GPT-4o) against human judges for support assessment. We considered two conditions: (1) fully manual assessments from scratch and (2) manual assessments with post-editing of LLM predictions. Our results indicate that for 56% of the manual from-scratch assessments, human and GPT-4o predictions match perfectly (on a three-level scale), increasing to 72% in the manual with post-editing condition. Furthermore, by carefully analyzing the disagreements in an unbiased study, we found that an independent human judge correlates better with GPT-4o than a human judge, suggesting that LLM judges can be a reliable alternative for support assessment. To conclude, we provide a qualitative analysis of human and GPT-4o errors to help guide future iterations of support assessment.
The Great Nugget Recall: Automating Fact Extraction and RAG Evaluation with Large Language Models
Apr 21, 2025



Large Language Models (LLMs) have significantly enhanced the capabilities of information access systems, especially with retrieval-augmented generation (RAG). Nevertheless, the evaluation of RAG systems remains a barrier to continued progress, a challenge we tackle in this work by proposing an automatic evaluation framework that is validated against human annotations. We believe that the nugget evaluation methodology provides a solid foundation for evaluating RAG systems. This approach, originally developed for the TREC Question Answering (QA) Track in 2003, evaluates systems based on atomic facts that should be present in good answers. Our efforts focus on "refactoring" this methodology, where we describe the AutoNuggetizer framework that specifically applies LLMs to both automatically create nuggets and automatically assign nuggets to system answers. In the context of the TREC 2024 RAG Track, we calibrate a fully automatic approach against strategies where nuggets are created manually or semi-manually by human assessors and then assigned manually to system answers. Based on results from a community-wide evaluation, we observe strong agreement at the run level between scores derived from fully automatic nugget evaluation and human-based variants. The agreement is stronger when individual framework components such as nugget assignment are automated independently. This suggests that our evaluation framework provides tradeoffs between effort and quality that can be used to guide the development of future RAG systems. However, further research is necessary to refine our approach, particularly in establishing robust per-topic agreement to diagnose system failures effectively.
CORD: Balancing COnsistency and Rank Distillation for Robust Retrieval-Augmented Generation
Dec 19, 2024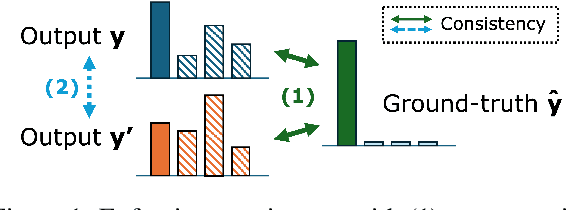



With the adoption of retrieval-augmented generation (RAG), large language models (LLMs) are expected to ground their generation to the retrieved contexts. Yet, this is hindered by position bias of LLMs, failing to evenly attend to all contexts. Previous work has addressed this by synthesizing contexts with perturbed positions of gold segment, creating a position-diversified train set. We extend this intuition to propose consistency regularization with augmentation and distillation. First, we augment each training instance with its position perturbation to encourage consistent predictions, regardless of ordering. We also distill behaviors of this pair, although it can be counterproductive in certain RAG scenarios where the given order from the retriever is crucial for generation quality. We thus propose CORD, balancing COnsistency and Rank Distillation. CORD adaptively samples noise-controlled perturbations from an interpolation space, ensuring both consistency and respect for the rank prior. Empirical results show this balance enables CORD to outperform consistently in diverse RAG benchmarks.
Inference Scaling for Bridging Retrieval and Augmented Generation
Dec 14, 2024Retrieval-augmented generation (RAG) has emerged as a popular approach to steering the output of a large language model (LLM) by incorporating retrieved contexts as inputs. However, existing work observed the generator bias, such that improving the retrieval results may negatively affect the outcome. In this work, we show such bias can be mitigated, from inference scaling, aggregating inference calls from the permuted order of retrieved contexts. The proposed Mixture-of-Intervention (MOI) explicitly models the debiased utility of each passage with multiple forward passes to construct a new ranking. We also show that MOI can leverage the retriever's prior knowledge to reduce the computational cost by minimizing the number of permutations considered and lowering the cost per LLM call. We showcase the effectiveness of MOI on diverse RAG tasks, improving ROUGE-L on MS MARCO and EM on HotpotQA benchmarks by ~7 points.
Arctic-Embed 2.0: Multilingual Retrieval Without Compromise
Dec 03, 2024This paper presents the training methodology of Arctic-Embed 2.0, a set of open-source text embedding models built for accurate and efficient multilingual retrieval. While prior works have suffered from degraded English retrieval quality, Arctic-Embed 2.0 delivers competitive retrieval quality on multilingual and English-only benchmarks, and supports Matryoshka Representation Learning (MRL) for efficient embedding storage with significantly lower compressed quality degradation compared to alternatives. We detail the design and implementation, presenting several important open research questions that arose during model development. We conduct experiments exploring these research questions and include extensive discussion aimed at fostering further discussion in this field.
Initial Nugget Evaluation Results for the TREC 2024 RAG Track with the AutoNuggetizer Framework
Nov 14, 2024

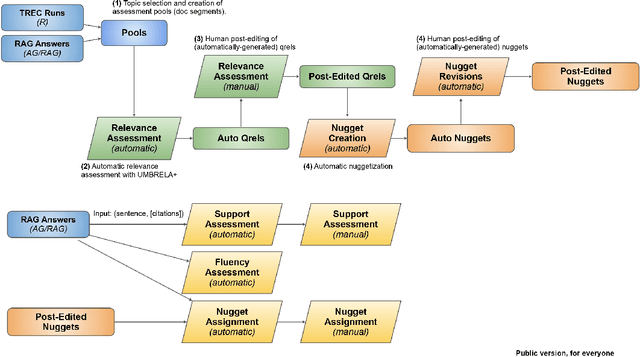

This report provides an initial look at partial results from the TREC 2024 Retrieval-Augmented Generation (RAG) Track. We have identified RAG evaluation as a barrier to continued progress in information access (and more broadly, natural language processing and artificial intelligence), and it is our hope that we can contribute to tackling the many challenges in this space. The central hypothesis we explore in this work is that the nugget evaluation methodology, originally developed for the TREC Question Answering Track in 2003, provides a solid foundation for evaluating RAG systems. As such, our efforts have focused on "refactoring" this methodology, specifically applying large language models to both automatically create nuggets and to automatically assign nuggets to system answers. We call this the AutoNuggetizer framework. Within the TREC setup, we are able to calibrate our fully automatic process against a manual process whereby nuggets are created by human assessors semi-manually and then assigned manually to system answers. Based on initial results across 21 topics from 45 runs, we observe a strong correlation between scores derived from a fully automatic nugget evaluation and a (mostly) manual nugget evaluation by human assessors. This suggests that our fully automatic evaluation process can be used to guide future iterations of RAG systems.
A Large-Scale Study of Relevance Assessments with Large Language Models: An Initial Look
Nov 13, 2024The application of large language models to provide relevance assessments presents exciting opportunities to advance information retrieval, natural language processing, and beyond, but to date many unknowns remain. This paper reports on the results of a large-scale evaluation (the TREC 2024 RAG Track) where four different relevance assessment approaches were deployed in situ: the "standard" fully manual process that NIST has implemented for decades and three different alternatives that take advantage of LLMs to different extents using the open-source UMBRELA tool. This setup allows us to correlate system rankings induced by the different approaches to characterize tradeoffs between cost and quality. We find that in terms of nDCG@20, nDCG@100, and Recall@100, system rankings induced by automatically generated relevance assessments from UMBRELA correlate highly with those induced by fully manual assessments across a diverse set of 77 runs from 19 teams. Our results suggest that automatically generated UMBRELA judgments can replace fully manual judgments to accurately capture run-level effectiveness. Surprisingly, we find that LLM assistance does not appear to increase correlation with fully manual assessments, suggesting that costs associated with human-in-the-loop processes do not bring obvious tangible benefits. Overall, human assessors appear to be stricter than UMBRELA in applying relevance criteria. Our work validates the use of LLMs in academic TREC-style evaluations and provides the foundation for future studies.