 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Foundations of DIME: Risk Estimation for Practical Index Selection
Jan 09, 2026High-dimensional dense embeddings have become central to modern Information Retrieval, but many dimensions are noisy or redundant. Recently proposed DIME (Dimension IMportance Estimation), provides query-dependent scores to identify informative components of embeddings. DIME relies on a costly grid search to select a priori a dimensionality for all the query corpus's embeddings. Our work provides a statistically grounded criterion that directly identifies the optimal set of dimensions for each query at inference time. Experiments confirm achieving parity of effectiveness and reduces embedding size by an average of $\sim50\%$ across different models and datasets at inference time.
ColBERT-serve: Efficient Multi-Stage Memory-Mapped Scoring
Apr 21, 2025We study serving retrieval models, specifically late interaction models like ColBERT, to many concurrent users at once and under a small budget, in which the index may not fit in memory. We present ColBERT-serve, a novel serving system that applies a memory-mapping strategy to the ColBERT index, reducing RAM usage by 90% and permitting its deployment on cheap servers, and incorporates a multi-stage architecture with hybrid scoring, reducing ColBERT's query latency and supporting many concurrent queries in parallel.
Efficient Constant-Space Multi-Vector Retrieval
Apr 02, 2025Multi-vector retrieval methods, exemplified by the ColBERT architecture, have shown substantial promise for retrieval by providing strong trade-offs in terms of retrieval latency and effectiveness. However, they come at a high cost in terms of storage since a (potentially compressed) vector needs to be stored for every token in the input collection. To overcome this issue, we propose encoding documents to a fixed number of vectors, which are no longer necessarily tied to the input tokens. Beyond reducing the storage costs, our approach has the advantage that document representations become of a fixed size on disk, allowing for better OS paging management. Through experiments using the MSMARCO passage corpus and BEIR with the ColBERT-v2 architecture, a representative multi-vector ranking model architecture, we find that passages can be effectively encoded into a fixed number of vectors while retaining most of the original effectiveness.
DeeperImpact: Optimizing Sparse Learned Index Structures
May 27, 2024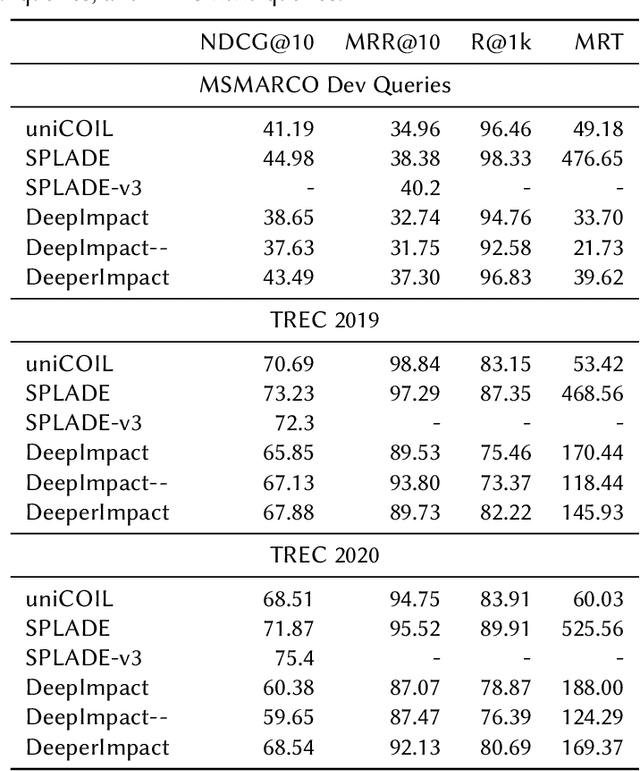
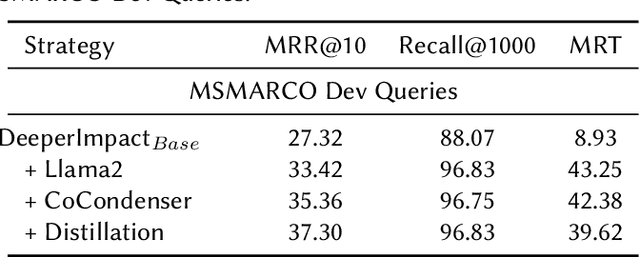
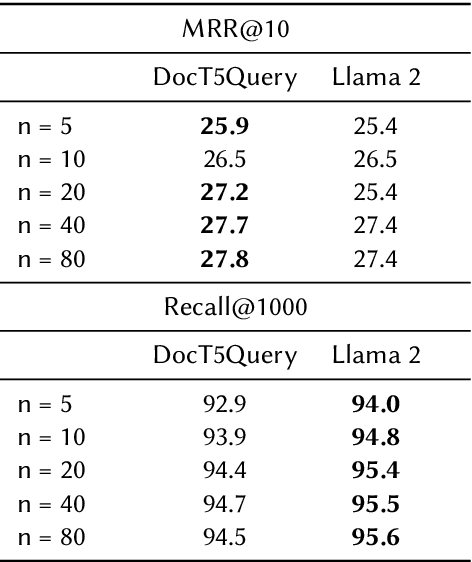
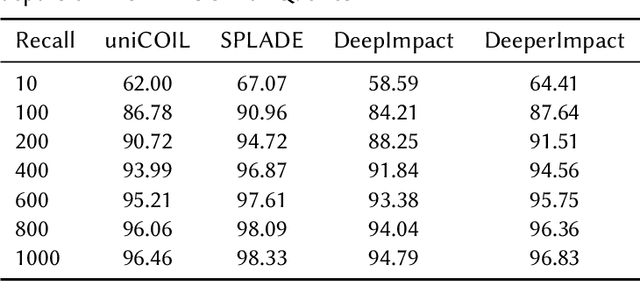
A lot of recent work has focused on sparse learned indexes that use deep neural architectures to significantly improve retrieval quality while keeping the efficiency benefits of the inverted index. While such sparse learned structures achieve effectiveness far beyond those of traditional inverted index-based rankers, there is still a gap in effectiveness to the best dense retrievers, or even to sparse methods that leverage more expensive optimizations such as query expansion and query term weighting. We focus on narrowing this gap by revisiting and optimizing DeepImpact, a sparse retrieval approach that uses DocT5Query for document expansion followed by a BERT language model to learn impact scores for document terms. We first reinvestigate the expansion process and find that the recently proposed Doc2Query query filtration does not enhance retrieval quality when used with DeepImpact. Instead, substituting T5 with a fine-tuned Llama 2 model for query prediction results in a considerable improvement. Subsequently, we study training strategies that have proven effective for other models, in particular the use of hard negatives, distillation, and pre-trained CoCondenser model initialization. Our results significantly narrow the effectiveness gap with the most effective versions of SPLADE.
Faster Learned Sparse Retrieval with Block-Max Pruning
May 02, 2024Learned sparse retrieval systems aim to combine the effectiveness of contextualized language models with the scalability of conventional data structures such as inverted indexes. Nevertheless, the indexes generated by these systems exhibit significant deviations from the ones that use traditional retrieval models, leading to a discrepancy in the performance of existing query optimizations that were specifically developed for traditional structures. These disparities arise from structural variations in query and document statistics, including sub-word tokenization, leading to longer queries, smaller vocabularies, and different score distributions within posting lists. This paper introduces Block-Max Pruning (BMP), an innovative dynamic pruning strategy tailored for indexes arising in learned sparse retrieval environments. BMP employs a block filtering mechanism to divide the document space into small, consecutive document ranges, which are then aggregated and sorted on the fly, and fully processed only as necessary, guided by a defined safe early termination criterion or based on approximate retrieval requirements. Through rigorous experimentation, we show that BMP substantially outperforms existing dynamic pruning strategies, offering unparalleled efficiency in safe retrieval contexts and improved tradeoffs between precision and efficiency in approximate retrieval tasks.
Improved Learned Sparse Retrieval with Corpus-Specific Vocabularies
Jan 12, 2024We explore leveraging corpus-specific vocabularies that improve both efficiency and effectiveness of learned sparse retrieval systems. We find that pre-training the underlying BERT model on the target corpus, specifically targeting different vocabulary sizes incorporated into the document expansion process, improves retrieval quality by up to 12% while in some scenarios decreasing latency by up to 50%. Our experiments show that adopting corpus-specific vocabulary and increasing vocabulary size decreases average postings list length which in turn reduces latency. Ablation studies show interesting interactions between custom vocabularies, document expansion techniques, and sparsification objectives of sparse models. Both effectiveness and efficiency improvements transfer to different retrieval approaches such as uniCOIL and SPLADE and offer a simple yet effective approach to providing new efficiency-effectiveness trade-offs for learned sparse retrieval systems.
Faster Learned Sparse Retrieval with Guided Traversal
Apr 24, 2022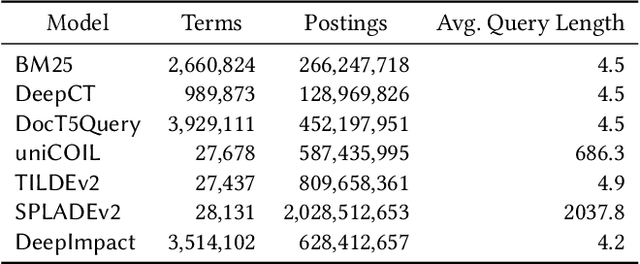
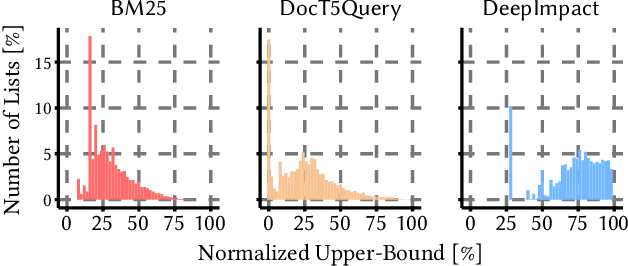
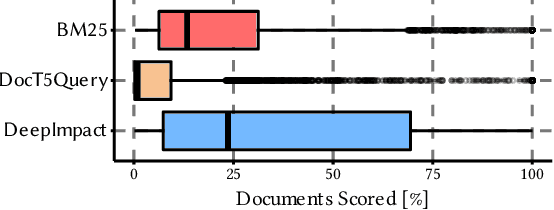
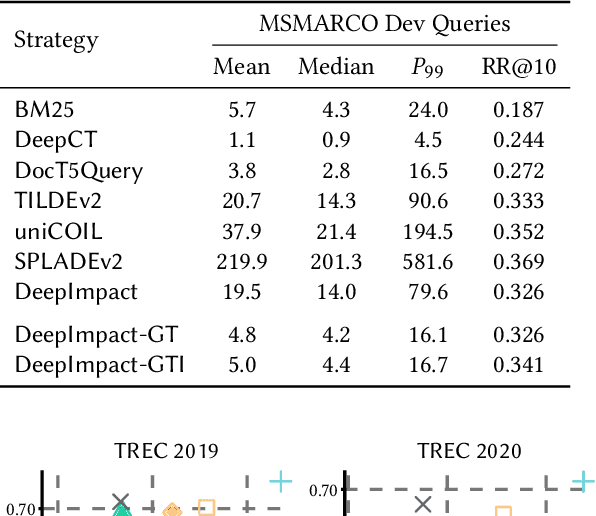
Neural information retrieval architectures based on transformers such as BERT are able to significantly improve system effectiveness over traditional sparse models such as BM25. Though highly effective, these neural approaches are very expensive to run, making them difficult to deploy under strict latency constraints. To address this limitation, recent studies have proposed new families of learned sparse models that try to match the effectiveness of learned dense models, while leveraging the traditional inverted index data structure for efficiency. Current learned sparse models learn the weights of terms in documents and, sometimes, queries; however, they exploit different vocabulary structures, document expansion techniques, and query expansion strategies, which can make them slower than traditional sparse models such as BM25. In this work, we propose a novel indexing and query processing technique that exploits a traditional sparse model's "guidance" to efficiently traverse the index, allowing the more effective learned model to execute fewer scoring operations. Our experiments show that our guided processing heuristic is able to boost the efficiency of the underlying learned sparse model by a factor of four without any measurable loss of effectiveness.
Learning Passage Impacts for Inverted Indexes
Apr 24, 2021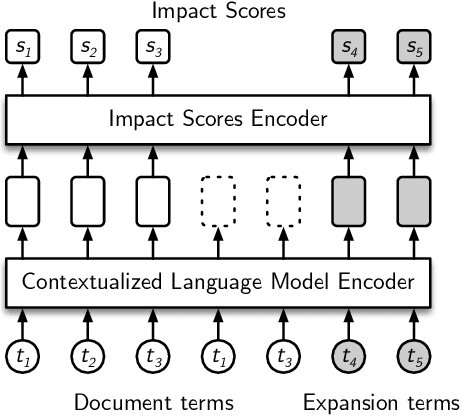

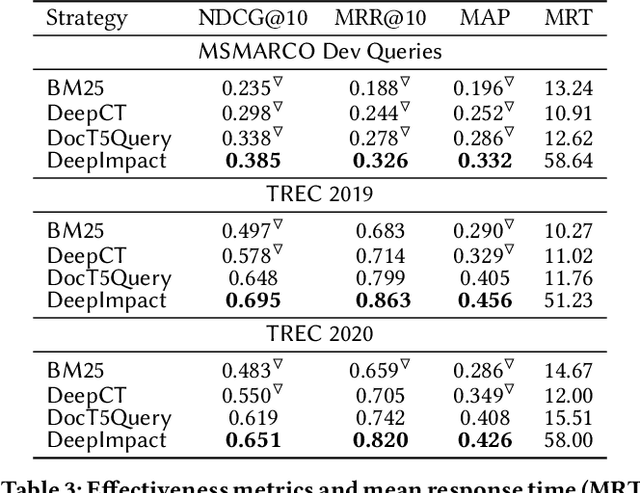
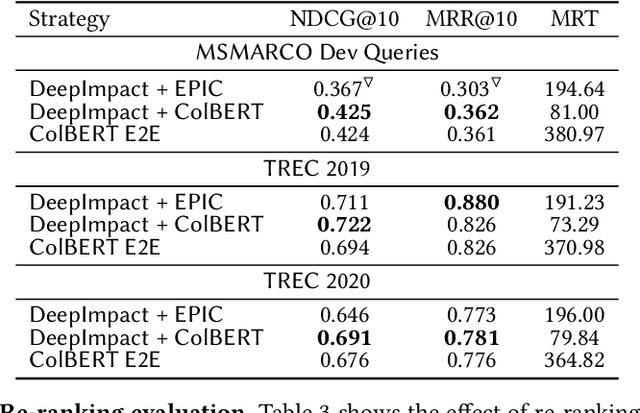
Neural information retrieval systems typically use a cascading pipeline, in which a first-stage model retrieves a candidate set of documents and one or more subsequent stages re-rank this set using contextualized language models such as BERT. In this paper, we propose DeepImpact, a new document term-weighting scheme suitable for efficient retrieval using a standard inverted index. Compared to existing methods, DeepImpact improves impact-score modeling and tackles the vocabulary-mismatch problem. In particular, DeepImpact leverages DocT5Query to enrich the document collection and, using a contextualized language model, directly estimates the semantic importance of tokens in a document, producing a single-value representation for each token in each document. Our experiments show that DeepImpact significantly outperforms prior first-stage retrieval approaches by up to 17% on effectiveness metrics w.r.t. DocT5Query, and, when deployed in a re-ranking scenario, can reach the same effectiveness of state-of-the-art approaches with up to 5.1x speedup in efficiency.
Debunking Fake News One Feature at a Time
Aug 08, 2018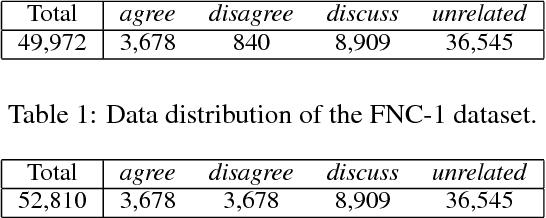

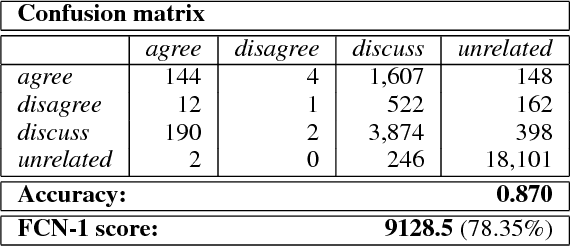
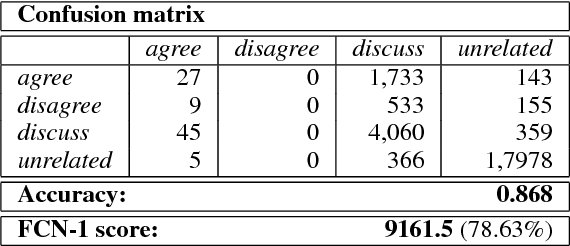
Identifying the stance of a news article body with respect to a certain headline is the first step to automated fake news detection. In this paper, we introduce a 2-stage ensemble model to solve the stance detection task. By using only hand-crafted features as input to a gradient boosting classifier, we are able to achieve a score of 9161.5 out of 11651.25 (78.63%) on the official Fake News Challenge (Stage 1) dataset. We identify the most useful features for detecting fake news and discuss how sampling techniques can be used to improve recall accuracy on a highly imbalanced dataset.