 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLM Judges Inflate Scores: Exploring Overrating in Relevance Assessment
Feb 19, 2026Human relevance assessment is time-consuming and cognitively intensive, limiting the scalability of Information Retrieval evaluation. This has led to growing interest in using large language models (LLMs) as proxies for human judges. However, it remains an open question whether LLM-based relevance judgments are reliable, stable, and rigorous enough to match humans for relevance assessment. In this work, we conduct a systematic study of overrating behavior in LLM-based relevance judgments across model backbones, evaluation paradigms (pointwise and pairwise), and passage modification strategies. We show that models consistently assign inflated relevance scores -- often with high confidence -- to passages that do not genuinely satisfy the underlying information need, revealing a system-wide bias rather than random fluctuations in judgment. Furthermore, controlled experiments show that LLM-based relevance judgments can be highly sensitive to passage length and surface-level lexical cues. These results raise concerns about the usage of LLMs as drop-in replacements for human relevance assessors, and highlight the urgent need for careful diagnostic evaluation frameworks when applying LLMs for relevance assessments. Our code and results are publicly available.
Revisiting Human-vs-LLM judgments using the TREC Podcast Track
Jan 09, 2026Using large language models (LLMs) to annotate relevance is an increasingly important technique in the information retrieval community. While some studies demonstrate that LLMs can achieve high user agreement with ground truth (human) judgments, other studies have argued for the opposite conclusion. To the best of our knowledge, these studies have primarily focused on classic ad-hoc text search scenarios. In this paper, we conduct an analysis on user agreement between LLM and human experts, and explore the impact disagreement has on system rankings. In contrast to prior studies, we focus on a collection composed of audio files that are transcribed into two-minute segments -- the TREC 2020 and 2021 podcast track. We employ five different LLM models to re-assess all of the query-segment pairs, which were originally annotated by TREC assessors. Furthermore, we re-assess a small subset of pairs where LLM and TREC assessors have the highest disagreement, and found that the human experts tend to agree with LLMs more than with the TREC assessors. Our results reinforce the previous insights of Sormunen in 2002 -- that relying on a single assessor leads to lower user agreement.
How Much Freedom Does An Effectiveness Metric Really Have?
Sep 18, 2023It is tempting to assume that because effectiveness metrics have free choice to assign scores to search engine result pages (SERPs) there must thus be a similar degree of freedom as to the relative order that SERP pairs can be put into. In fact that second freedom is, to a considerable degree, illusory. That's because if one SERP in a pair has been given a certain score by a metric, fundamental ordering constraints in many cases then dictate that the score for the second SERP must be either not less than, or not greater than, the score assigned to the first SERP. We refer to these fixed relationships as innate pairwise SERP orderings. Our first goal in this work is to describe and defend those pairwise SERP relationship constraints, and tabulate their relative occurrence via both exhaustive and empirical experimentation. We then consider how to employ such innate pairwise relationships in IR experiments, leading to a proposal for a new measurement paradigm. Specifically, we argue that tables of results in which many different metrics are listed for champion versus challenger system comparisons should be avoided; and that instead a single metric be argued for in principled terms, with any relationships identified by that metric then reinforced via an assessment of the innate relationship as to whether other metrics - indeed, all other metrics - are likely to yield the same system-vs-system outcome.
Exploring the Representation Power of SPLADE Models
Jun 29, 2023The SPLADE (SParse Lexical AnD Expansion) model is a highly effective approach to learned sparse retrieval, where documents are represented by term impact scores derived from large language models. During training, SPLADE applies regularization to ensure postings lists are kept sparse -- with the aim of mimicking the properties of natural term distributions -- allowing efficient and effective lexical matching and ranking. However, we hypothesize that SPLADE may encode additional signals into common postings lists to further improve effectiveness. To explore this idea, we perform a number of empirical analyses where we re-train SPLADE with different, controlled vocabularies and measure how effective it is at ranking passages. Our findings suggest that SPLADE can effectively encode useful ranking signals in documents even when the vocabulary is constrained to terms that are not traditionally useful for ranking, such as stopwords or even random words.
Efficient Immediate-Access Dynamic Indexing
Nov 11, 2022In a dynamic retrieval system, documents must be ingested as they arrive, and be immediately findable by queries. Our purpose in this paper is to describe an index structure and processing regime that accommodates that requirement for immediate access, seeking to make the ingestion process as streamlined as possible, while at the same time seeking to make the growing index as small as possible, and seeking to make term-based querying via the index as efficient as possible. We describe a new compression operation and a novel approach to extensible lists which together facilitate that triple goal. In particular, the structure we describe provides incremental document-level indexing using as little as two bytes per posting and only a small amount more for word-level indexing; provides fast document insertion; supports immediate and continuous queryability; provides support for fast conjunctive queries and similarity score-based ranked queries; and facilitates fast conversion of the dynamic index to a "normal" static compressed inverted index structure. Measurement of our new mechanism confirms that in-memory dynamic document-level indexes for collections into the gigabyte range can be constructed at a rate of two gigabytes/minute using a typical server architecture, that multi-term conjunctive Boolean queries can be resolved in just a few milliseconds each on average even while new documents are being concurrently ingested, and that the net memory space required for all of the required data structures amounts to an average of as little as two bytes per stored posting.
Faster Learned Sparse Retrieval with Guided Traversal
Apr 24, 2022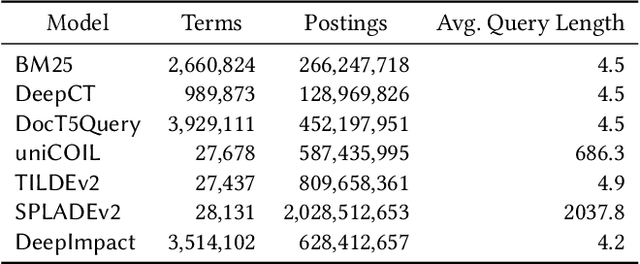
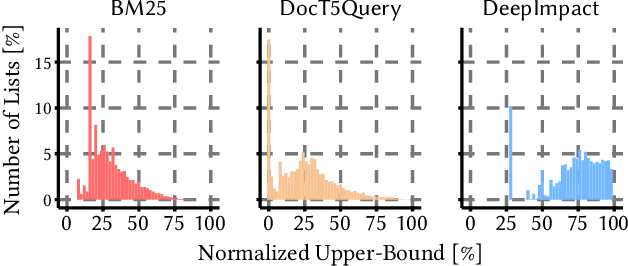
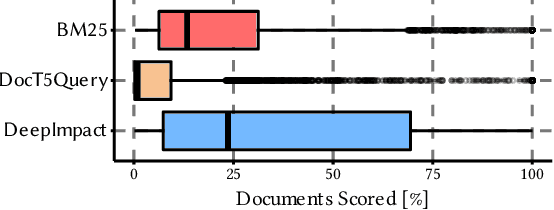
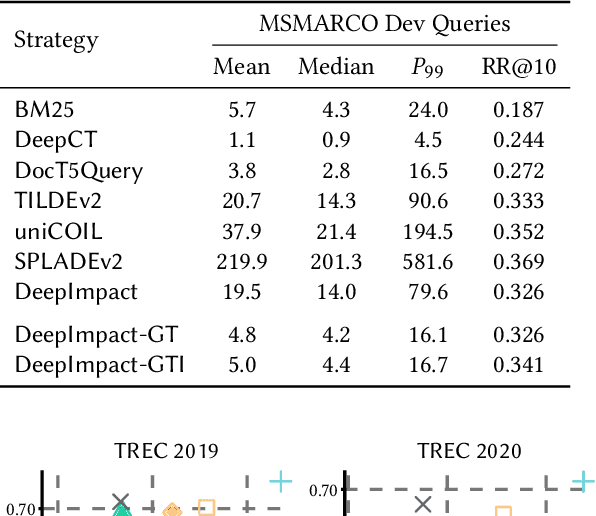
Neural information retrieval architectures based on transformers such as BERT are able to significantly improve system effectiveness over traditional sparse models such as BM25. Though highly effective, these neural approaches are very expensive to run, making them difficult to deploy under strict latency constraints. To address this limitation, recent studies have proposed new families of learned sparse models that try to match the effectiveness of learned dense models, while leveraging the traditional inverted index data structure for efficiency. Current learned sparse models learn the weights of terms in documents and, sometimes, queries; however, they exploit different vocabulary structures, document expansion techniques, and query expansion strategies, which can make them slower than traditional sparse models such as BM25. In this work, we propose a novel indexing and query processing technique that exploits a traditional sparse model's "guidance" to efficiently traverse the index, allowing the more effective learned model to execute fewer scoring operations. Our experiments show that our guided processing heuristic is able to boost the efficiency of the underlying learned sparse model by a factor of four without any measurable loss of effectiveness.
A Sensitivity Analysis of the MSMARCO Passage Collection
Jan 11, 2022

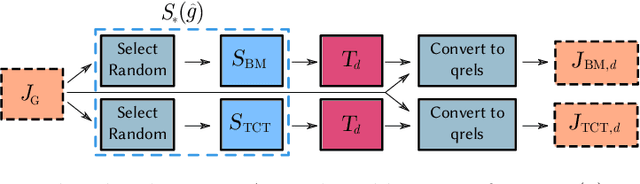
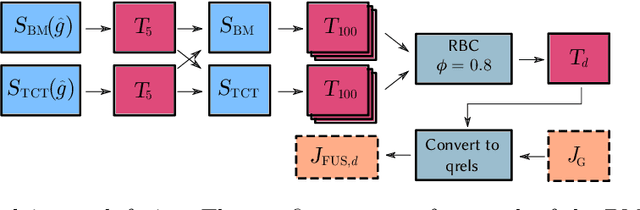
The recent MSMARCO passage retrieval collection has allowed researchers to develop highly tuned retrieval systems. One aspect of this data set that makes it distinctive compared to traditional corpora is that most of the topics only have a single answer passage marked relevant. Here we carry out a "what if" sensitivity study, asking whether a set of systems would still have the same relative performance if more passages per topic were deemed to be "relevant", exploring several mechanisms for identifying sets of passages to be so categorized. Our results show that, in general, while run scores can vary markedly if additional plausible passages are presumed to be relevant, the derived system ordering is relatively insensitive to additional relevance, providing support for the methodology that was used at the time the MSMARCO passage collection was created.
Wacky Weights in Learned Sparse Representations and the Revenge of Score-at-a-Time Query Evaluation
Oct 28, 2021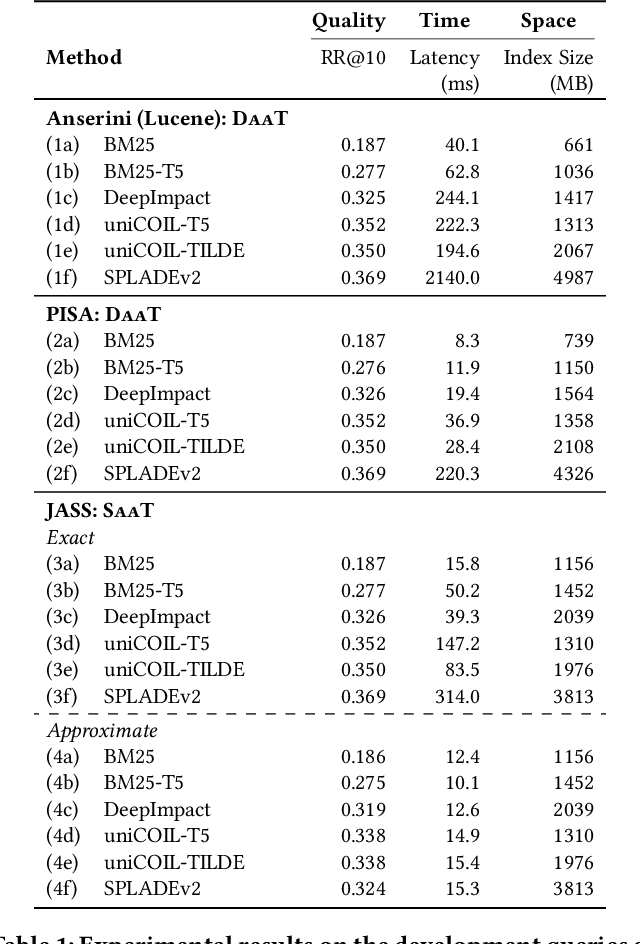
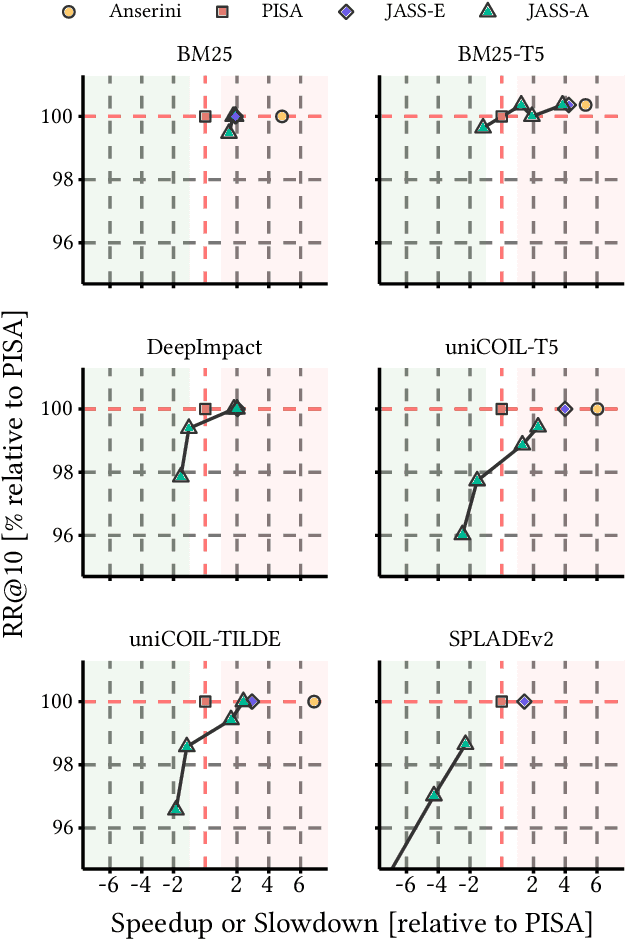
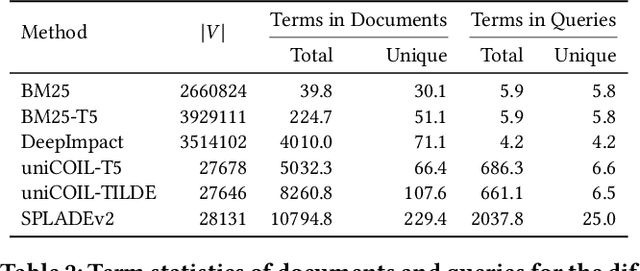
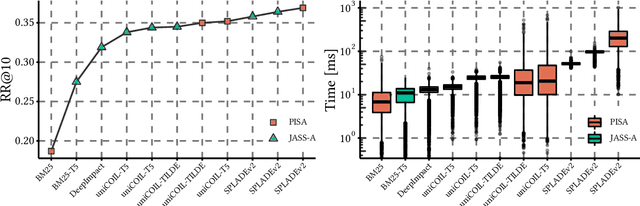
Recent advances in retrieval models based on learned sparse representations generated by transformers have led us to, once again, consider score-at-a-time query evaluation techniques for the top-k retrieval problem. Previous studies comparing document-at-a-time and score-at-a-time approaches have consistently found that the former approach yields lower mean query latency, although the latter approach has more predictable query latency. In our experiments with four different retrieval models that exploit representational learning with bags of words, we find that transformers generate "wacky weights" that appear to greatly reduce the opportunities for skipping and early exiting optimizations that lie at the core of standard document-at-a-time techniques. As a result, score-at-a-time approaches appear to be more competitive in terms of query evaluation latency than in previous studies. We find that, if an effectiveness loss of up to three percent can be tolerated, a score-at-a-time approach can yield substantial gains in mean query latency while at the same time dramatically reducing tail latency.
Anytime Ranking on Document-Ordered Indexes
Apr 18, 2021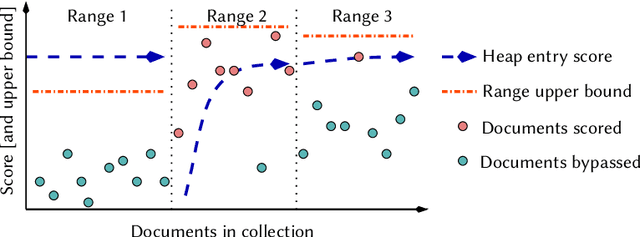


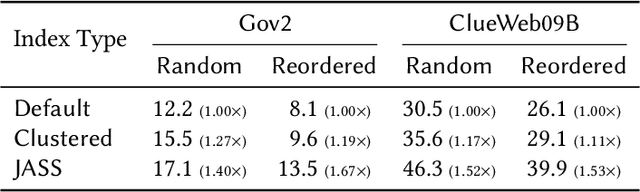
Inverted indexes continue to be a mainstay of text search engines, allowing efficient querying of large document collections. While there are a number of possible organizations, document-ordered indexes are the most common, since they are amenable to various query types, support index updates, and allow for efficient dynamic pruning operations. One disadvantage with document-ordered indexes is that high-scoring documents can be distributed across the document identifier space, meaning that index traversal algorithms that terminate early might put search effectiveness at risk. The alternative is impact-ordered indexes, which primarily support top-k disjunctions, but also allow for anytime query processing, where the search can be terminated at any time, with search quality improving as processing latency increases. Anytime query processing can be used to effectively reduce high-percentile tail latency which is essential for operational scenarios in which a service level agreement (SLA) imposes response time requirements. In this work, we show how document-ordered indexes can be organized such that they can be queried in an anytime fashion, enabling strict latency control with effective early termination. Our experiments show that processing document-ordered topical segments selected by a simple score estimator outperforms existing anytime algorithms, and allows query runtimes to be accurately limited in order to comply with SLA requirements.