 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Retrieval for Climate Impact
Apr 01, 2025The purpose of the MANILA24 Workshop on information retrieval for climate impact was to bring together researchers from academia, industry, governments, and NGOs to identify and discuss core research problems in information retrieval to assess climate change impacts. The workshop aimed to foster collaboration by bringing communities together that have so far not been very well connected -- information retrieval, natural language processing, systematic reviews, impact assessments, and climate science. The workshop brought together a diverse set of researchers and practitioners interested in contributing to the development of a technical research agenda for information retrieval to assess climate change impacts.
Wacky Weights in Learned Sparse Representations and the Revenge of Score-at-a-Time Query Evaluation
Oct 28, 2021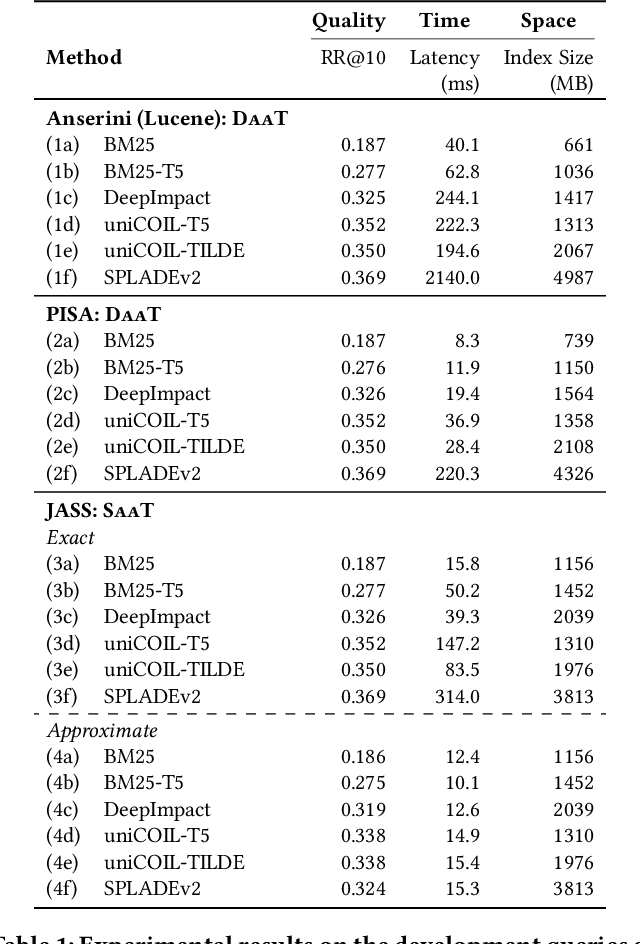
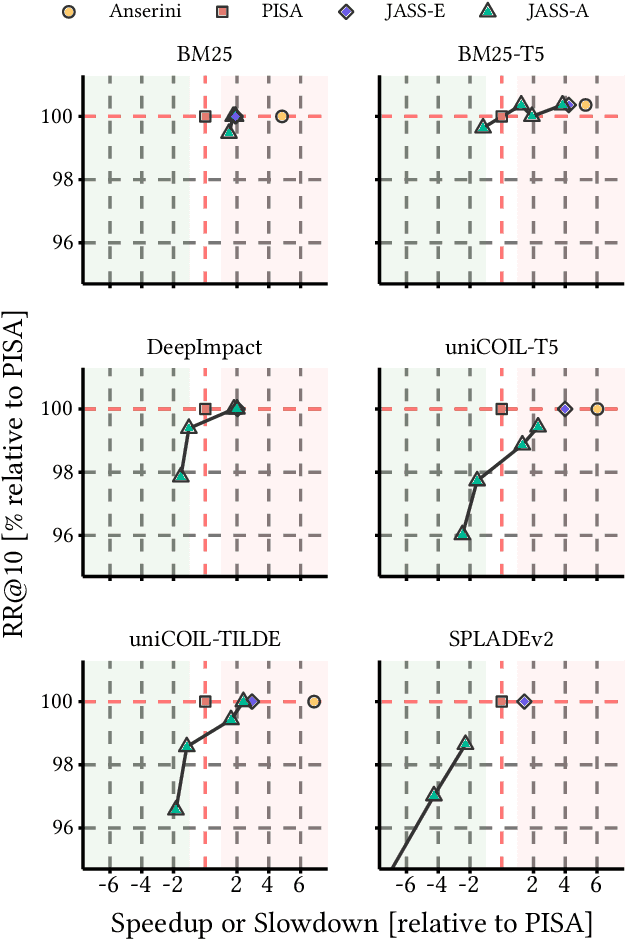
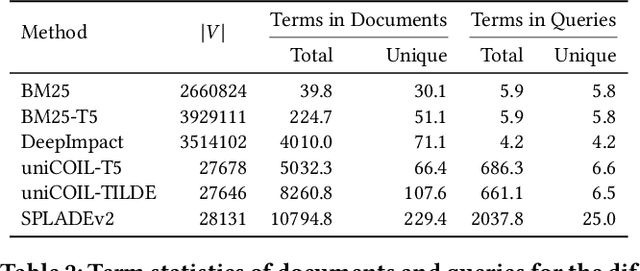
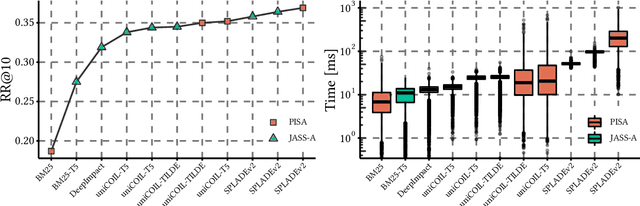
Recent advances in retrieval models based on learned sparse representations generated by transformers have led us to, once again, consider score-at-a-time query evaluation techniques for the top-k retrieval problem. Previous studies comparing document-at-a-time and score-at-a-time approaches have consistently found that the former approach yields lower mean query latency, although the latter approach has more predictable query latency. In our experiments with four different retrieval models that exploit representational learning with bags of words, we find that transformers generate "wacky weights" that appear to greatly reduce the opportunities for skipping and early exiting optimizations that lie at the core of standard document-at-a-time techniques. As a result, score-at-a-time approaches appear to be more competitive in terms of query evaluation latency than in previous studies. We find that, if an effectiveness loss of up to three percent can be tolerated, a score-at-a-time approach can yield substantial gains in mean query latency while at the same time dramatically reducing tail latency.
Document Clustering Evaluation: Divergence from a Random Baseline
Aug 29, 2012
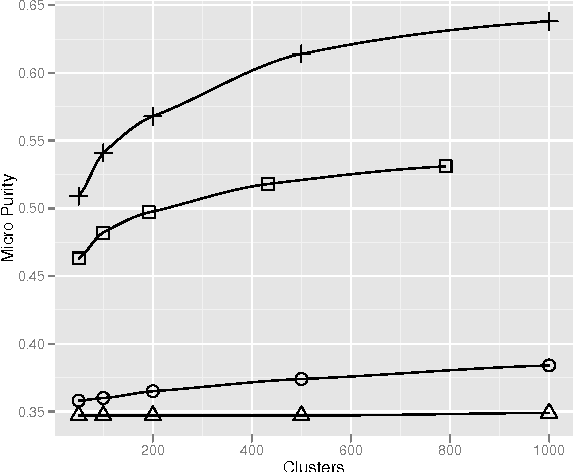
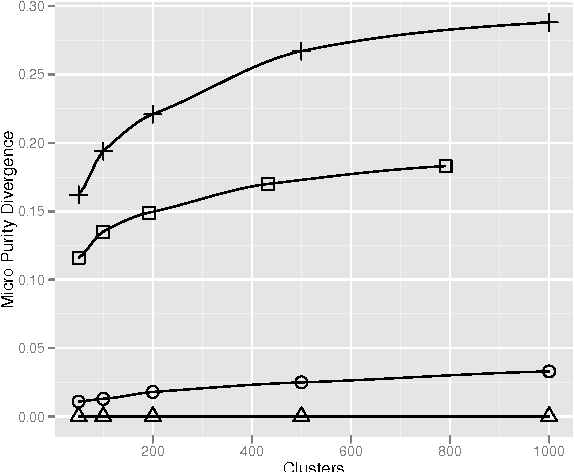
Divergence from a random baseline is a technique for the evaluation of document clustering. It ensures cluster quality measures are performing work that prevents ineffective clusterings from giving high scores to clusterings that provide no useful result. These concepts are defined and analysed using intrinsic and extrinsic approaches to the evaluation of document cluster quality. This includes the classical clusters to categories approach and a novel approach that uses ad hoc information retrieval. The divergence from a random baseline approach is able to differentiate ineffective clusterings encountered in the INEX XML Mining track. It also appears to perform a normalisation similar to the Normalised Mutual Information (NMI) measure but it can be applied to any measure of cluster quality. When it is applied to the intrinsic measure of distortion as measured by RMSE, subtraction from a random baseline provides a clear optimum that is not apparent otherwise. This approach can be applied to any clustering evaluation. This paper describes its use in the context of document clustering evaluation.