 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Streaming Signature EM-tree: A Clustering Algorithm for Web Scale Applications
May 21, 2015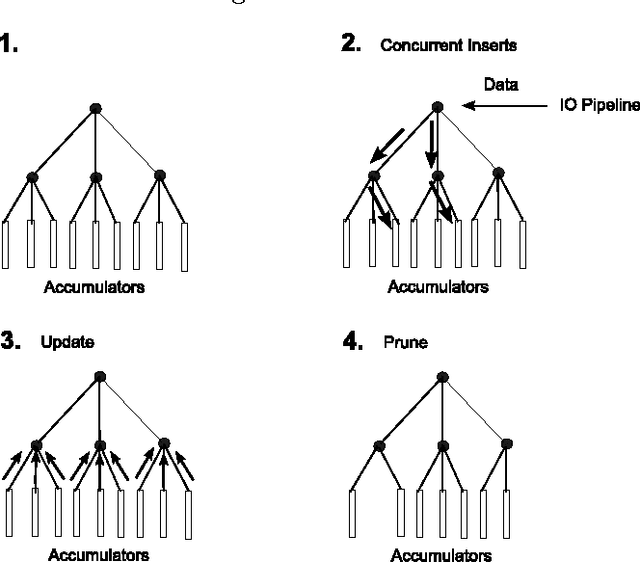


The proliferation of the web presents an unsolved problem of automatically analyzing billions of pages of natural language. We introduce a scalable algorithm that clusters hundreds of millions of web pages into hundreds of thousands of clusters. It does this on a single mid-range machine using efficient algorithms and compressed document representations. It is applied to two web-scale crawls covering tens of terabytes. ClueWeb09 and ClueWeb12 contain 500 and 733 million web pages and were clustered into 500,000 to 700,000 clusters. To the best of our knowledge, such fine grained clustering has not been previously demonstrated. Previous approaches clustered a sample that limits the maximum number of discoverable clusters. The proposed EM-tree algorithm uses the entire collection in clustering and produces several orders of magnitude more clusters than the existing algorithms. Fine grained clustering is necessary for meaningful clustering in massive collections where the number of distinct topics grows linearly with collection size. These fine-grained clusters show an improved cluster quality when assessed with two novel evaluations using ad hoc search relevance judgments and spam classifications for external validation. These evaluations solve the problem of assessing the quality of clusters where categorical labeling is unavailable and unfeasible.
Document Clustering Evaluation: Divergence from a Random Baseline
Aug 29, 2012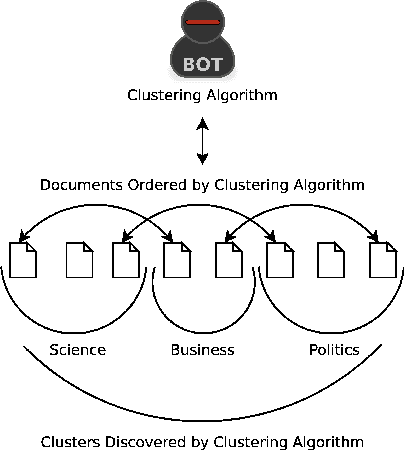
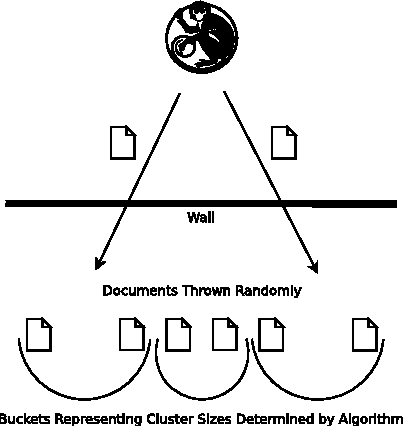
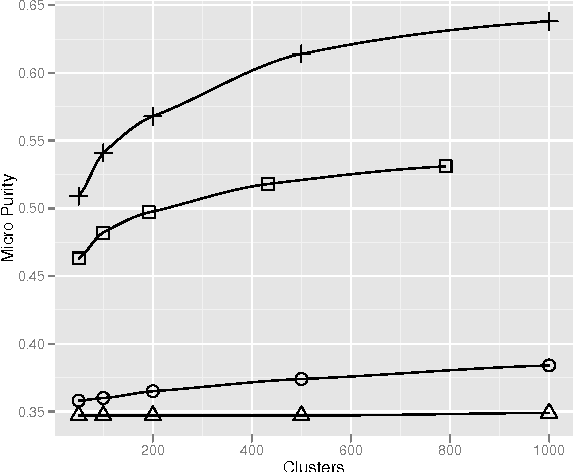
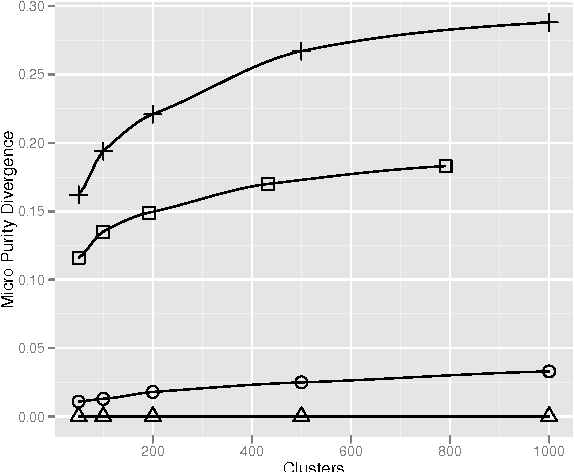
Divergence from a random baseline is a technique for the evaluation of document clustering. It ensures cluster quality measures are performing work that prevents ineffective clusterings from giving high scores to clusterings that provide no useful result. These concepts are defined and analysed using intrinsic and extrinsic approaches to the evaluation of document cluster quality. This includes the classical clusters to categories approach and a novel approach that uses ad hoc information retrieval. The divergence from a random baseline approach is able to differentiate ineffective clusterings encountered in the INEX XML Mining track. It also appears to perform a normalisation similar to the Normalised Mutual Information (NMI) measure but it can be applied to any measure of cluster quality. When it is applied to the intrinsic measure of distortion as measured by RMSE, subtraction from a random baseline provides a clear optimum that is not apparent otherwise. This approach can be applied to any clustering evaluation. This paper describes its use in the context of document clustering evaluation.
Random Indexing K-tree
Feb 02, 2010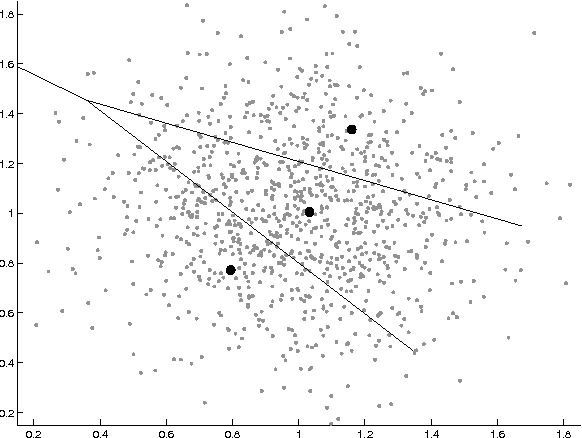
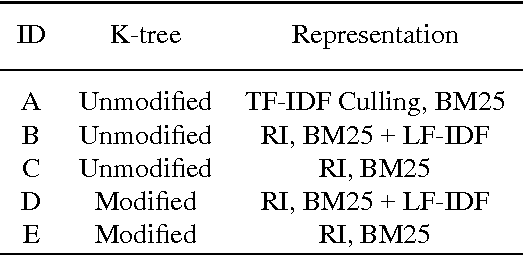
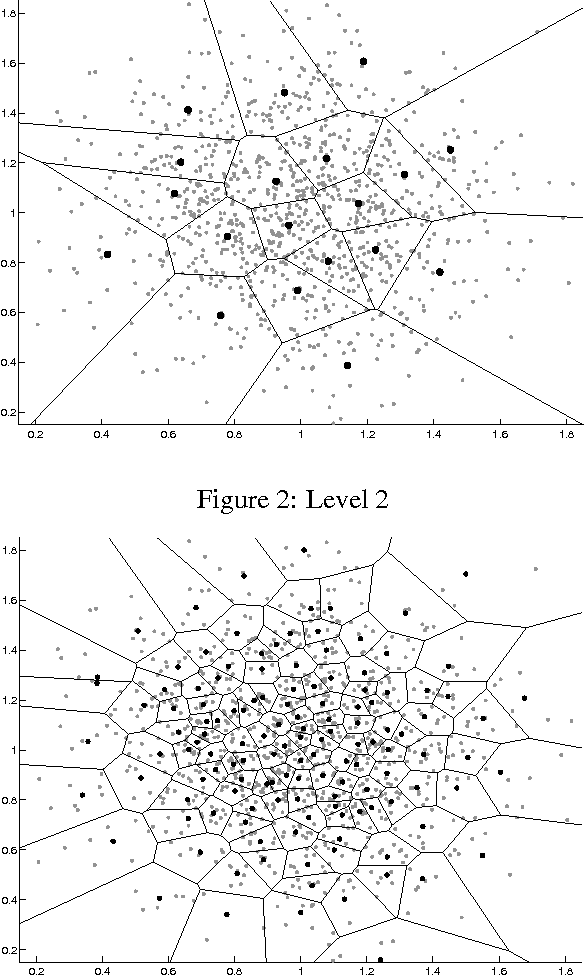
Random Indexing (RI) K-tree is the combination of two algorithms for clustering. Many large scale problems exist in document clustering. RI K-tree scales well with large inputs due to its low complexity. It also exhibits features that are useful for managing a changing collection. Furthermore, it solves previous issues with sparse document vectors when using K-tree. The algorithms and data structures are defined, explained and motivated. Specific modifications to K-tree are made for use with RI. Experiments have been executed to measure quality. The results indicate that RI K-tree improves document cluster quality over the original K-tree algorithm.
Document Clustering with K-tree
Jan 06, 2010



This paper describes the approach taken to the XML Mining track at INEX 2008 by a group at the Queensland University of Technology. We introduce the K-tree clustering algorithm in an Information Retrieval context by adapting it for document clustering. Many large scale problems exist in document clustering. K-tree scales well with large inputs due to its low complexity. It offers promising results both in terms of efficiency and quality. Document classification was completed using Support Vector Machines.
K-tree: Large Scale Document Clustering
Jan 06, 2010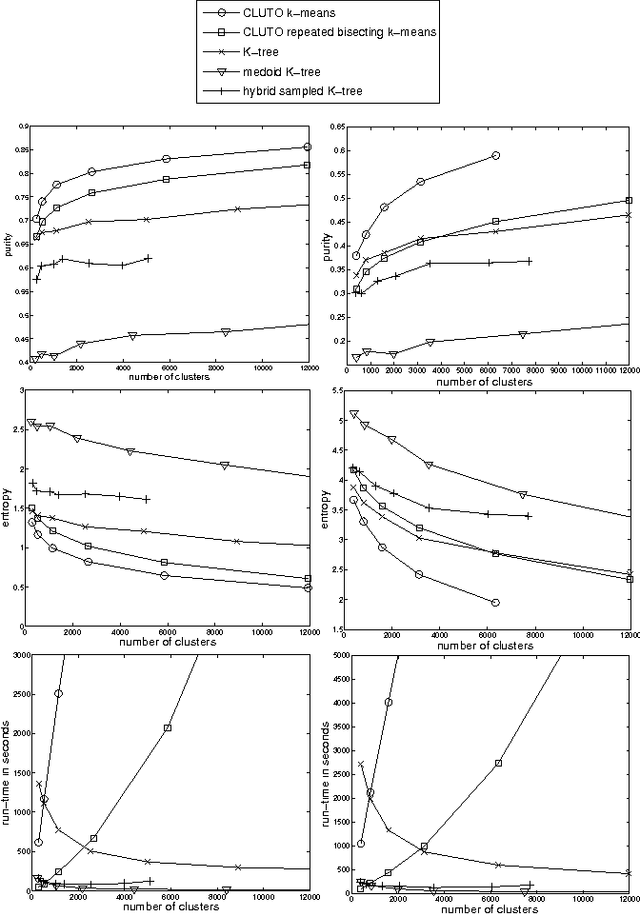
We introduce K-tree in an information retrieval context. It is an efficient approximation of the k-means clustering algorithm. Unlike k-means it forms a hierarchy of clusters. It has been extended to address issues with sparse representations. We compare performance and quality to CLUTO using document collections. The K-tree has a low time complexity that is suitable for large document collections. This tree structure allows for efficient disk based implementations where space requirements exceed that of main memory.