 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWacky Weights in Learned Sparse Representations and the Revenge of Score-at-a-Time Query Evaluation
Paper and Code
Oct 28, 2021
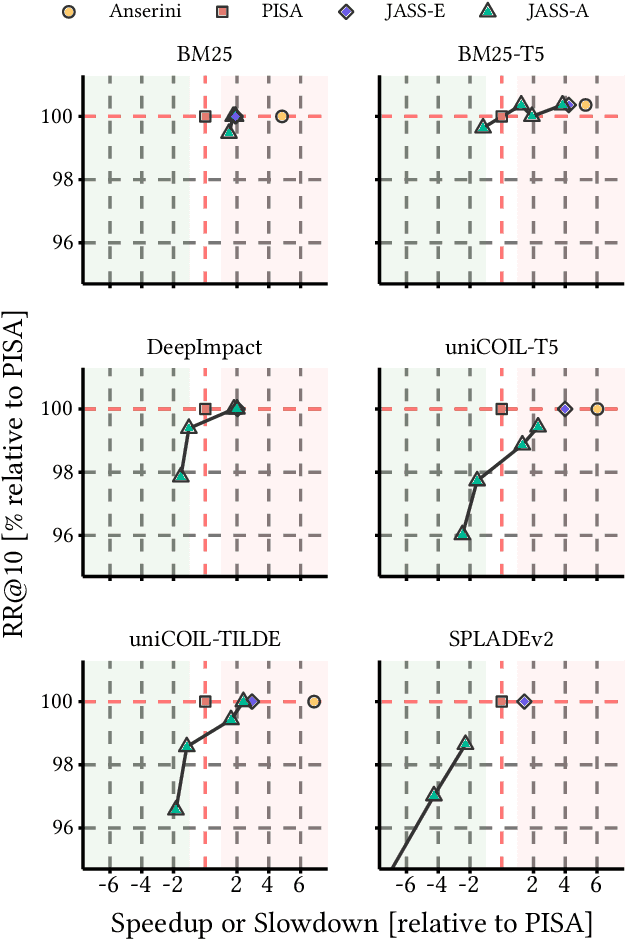
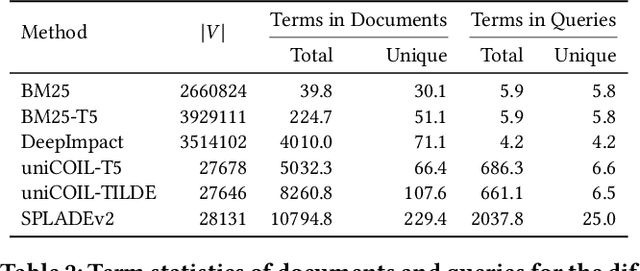
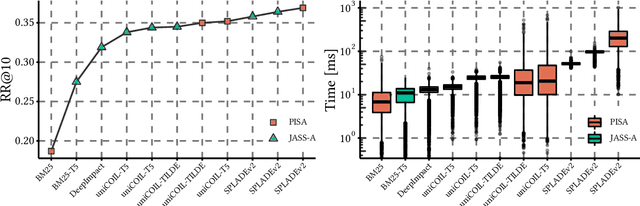
Recent advances in retrieval models based on learned sparse representations generated by transformers have led us to, once again, consider score-at-a-time query evaluation techniques for the top-k retrieval problem. Previous studies comparing document-at-a-time and score-at-a-time approaches have consistently found that the former approach yields lower mean query latency, although the latter approach has more predictable query latency. In our experiments with four different retrieval models that exploit representational learning with bags of words, we find that transformers generate "wacky weights" that appear to greatly reduce the opportunities for skipping and early exiting optimizations that lie at the core of standard document-at-a-time techniques. As a result, score-at-a-time approaches appear to be more competitive in terms of query evaluation latency than in previous studies. We find that, if an effectiveness loss of up to three percent can be tolerated, a score-at-a-time approach can yield substantial gains in mean query latency while at the same time dramatically reducing tail latency.