 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Demographic Instructions on LLM Personas
May 17, 2025Social media platforms must filter sexist content in compliance with governmental regulations. Current machine learning approaches can reliably detect sexism based on standardized definitions, but often neglect the subjective nature of sexist language and fail to consider individual users' perspectives. To address this gap, we adopt a perspectivist approach, retaining diverse annotations rather than enforcing gold-standard labels or their aggregations, allowing models to account for personal or group-specific views of sexism. Using demographic data from Twitter, we employ large language models (LLMs) to personalize the identification of sexism.
Categorical, Ratio, and Professorial Data: The Case for Reciprocal Rank
Dec 20, 2023Search engine results pages are usually abstracted as binary relevance vectors and hence are categorical data, meaning that only a limited set of operations is permitted, most notably tabulation of occurrence frequencies, with determination of medians and averages not possible. To compare retrieval systems it is thus usual to make use of a categorical-to-numeric effectiveness mapping. A previous paper has argued that any desired categorical-to-numeric mapping may be used, provided only that there is an argued connection between each category of SERP and the score that is assigned to that category by the mapping. Further, once that plausible connection has been established, then the mapped values can be treated as real-valued observations on a ratio scale, allowing the computation of averages. This article is written in support of that point of view, and to respond to ongoing claims that SERP scores may only be averaged if very restrictive conditions are imposed on the effectiveness mapping.
Stochastic Directly-Follows Process Discovery Using Grammatical Inference
Dec 09, 2023



Starting with a collection of traces generated by process executions, process discovery is the task of constructing a simple model that describes the process, where simplicity is often measured in terms of model size. The challenge of process discovery is that the process of interest is unknown, and that while the input traces constitute positive examples of process executions, no negative examples are available. Many commercial tools discover Directly-Follows Graphs, in which nodes represent the observable actions of the process, and directed arcs indicate execution order possibilities over the actions. We propose a new approach for discovering sound Directly-Follows Graphs that is grounded in grammatical inference over the input traces. To promote the discovery of small graphs that also describe the process accurately we design and evaluate a genetic algorithm that supports the convergence of the inference parameters to the areas that lead to the discovery of interesting models. Experiments over real-world datasets confirm that our new approach can construct smaller models that represent the input traces and their frequencies more accurately than the state-of-the-art technique. Reasoning over the frequencies of encoded traces also becomes possible, due to the stochastic semantics of the action graphs we propose, which, for the first time, are interpreted as models that describe the stochastic languages of action traces.
How Much Freedom Does An Effectiveness Metric Really Have?
Sep 18, 2023It is tempting to assume that because effectiveness metrics have free choice to assign scores to search engine result pages (SERPs) there must thus be a similar degree of freedom as to the relative order that SERP pairs can be put into. In fact that second freedom is, to a considerable degree, illusory. That's because if one SERP in a pair has been given a certain score by a metric, fundamental ordering constraints in many cases then dictate that the score for the second SERP must be either not less than, or not greater than, the score assigned to the first SERP. We refer to these fixed relationships as innate pairwise SERP orderings. Our first goal in this work is to describe and defend those pairwise SERP relationship constraints, and tabulate their relative occurrence via both exhaustive and empirical experimentation. We then consider how to employ such innate pairwise relationships in IR experiments, leading to a proposal for a new measurement paradigm. Specifically, we argue that tables of results in which many different metrics are listed for champion versus challenger system comparisons should be avoided; and that instead a single metric be argued for in principled terms, with any relationships identified by that metric then reinforced via an assessment of the innate relationship as to whether other metrics - indeed, all other metrics - are likely to yield the same system-vs-system outcome.
Efficient Immediate-Access Dynamic Indexing
Nov 11, 2022In a dynamic retrieval system, documents must be ingested as they arrive, and be immediately findable by queries. Our purpose in this paper is to describe an index structure and processing regime that accommodates that requirement for immediate access, seeking to make the ingestion process as streamlined as possible, while at the same time seeking to make the growing index as small as possible, and seeking to make term-based querying via the index as efficient as possible. We describe a new compression operation and a novel approach to extensible lists which together facilitate that triple goal. In particular, the structure we describe provides incremental document-level indexing using as little as two bytes per posting and only a small amount more for word-level indexing; provides fast document insertion; supports immediate and continuous queryability; provides support for fast conjunctive queries and similarity score-based ranked queries; and facilitates fast conversion of the dynamic index to a "normal" static compressed inverted index structure. Measurement of our new mechanism confirms that in-memory dynamic document-level indexes for collections into the gigabyte range can be constructed at a rate of two gigabytes/minute using a typical server architecture, that multi-term conjunctive Boolean queries can be resolved in just a few milliseconds each on average even while new documents are being concurrently ingested, and that the net memory space required for all of the required data structures amounts to an average of as little as two bytes per stored posting.
Batch Evaluation Metrics in Information Retrieval: Measures, Scales, and Meaning
Jul 07, 2022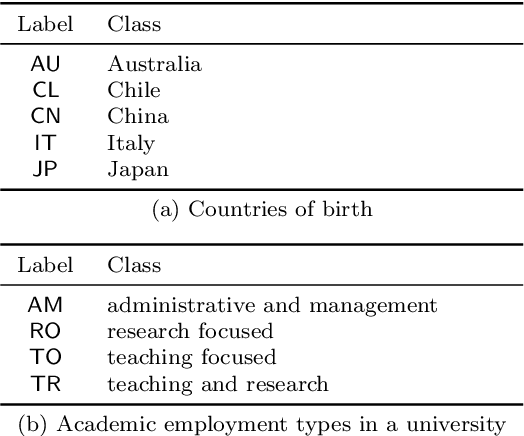
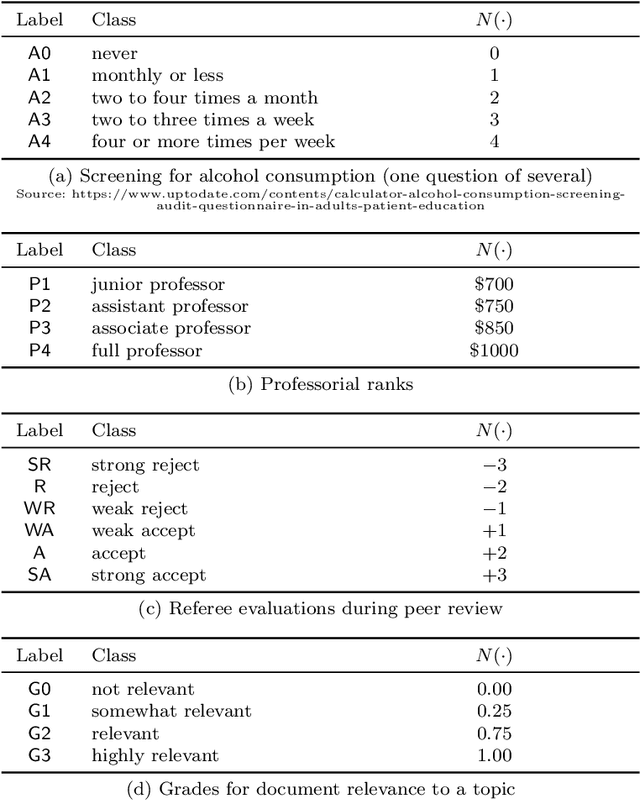

A sequence of recent papers has considered the role of measurement scales in information retrieval (IR) experimentation, and presented the argument that (only) uniform-step interval scales should be used, and hence that well-known metrics such as reciprocal rank, expected reciprocal rank, normalized discounted cumulative gain, and average precision, should be either discarded as measurement tools, or adapted so that their metric values lie at uniformly-spaced points on the number line. These papers paint a rather bleak picture of past decades of IR evaluation, at odds with the community's overall emphasis on practical experimentation and measurable improvement. Our purpose in this work is to challenge that position. In particular, we argue that mappings from categorical and ordinal data to sets of points on the number line are valid provided there is an external reason for each target point to have been selected. We first consider the general role of measurement scales, and of categorical, ordinal, interval, ratio, and absolute data collections. In connection with the first two of those categories we also provide examples of the knowledge that is captured and represented by numeric mappings to the real number line. Focusing then on information retrieval, we argue that document rankings are categorical data, and that the role of an effectiveness metric is to provide a single value that represents the usefulness to a user or population of users of any given ranking, with usefulness able to be represented as a continuous variable on a ratio scale. That is, we argue that current IR metrics are well-founded, and, moreover, that those metrics are more meaningful in their current form than in the proposed "intervalized" versions.
A Sensitivity Analysis of the MSMARCO Passage Collection
Jan 11, 2022

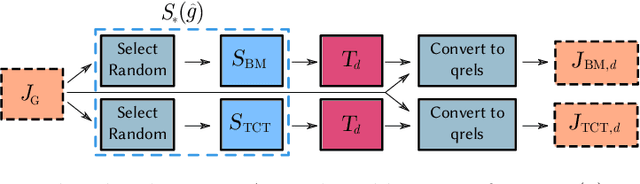
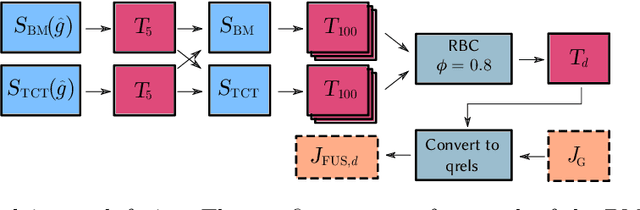
The recent MSMARCO passage retrieval collection has allowed researchers to develop highly tuned retrieval systems. One aspect of this data set that makes it distinctive compared to traditional corpora is that most of the topics only have a single answer passage marked relevant. Here we carry out a "what if" sensitivity study, asking whether a set of systems would still have the same relative performance if more passages per topic were deemed to be "relevant", exploring several mechanisms for identifying sets of passages to be so categorized. Our results show that, in general, while run scores can vary markedly if additional plausible passages are presumed to be relevant, the derived system ordering is relatively insensitive to additional relevance, providing support for the methodology that was used at the time the MSMARCO passage collection was created.
Bootstrapping Generalization of Process Models Discovered From Event Data
Jul 08, 2021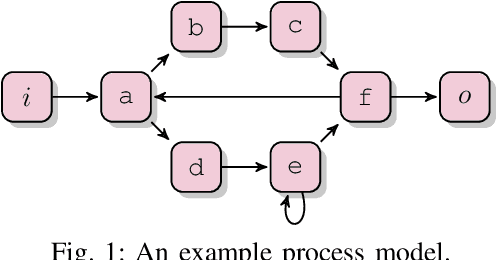
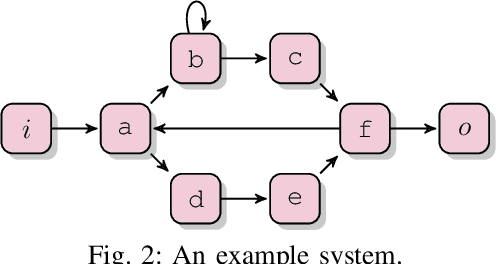
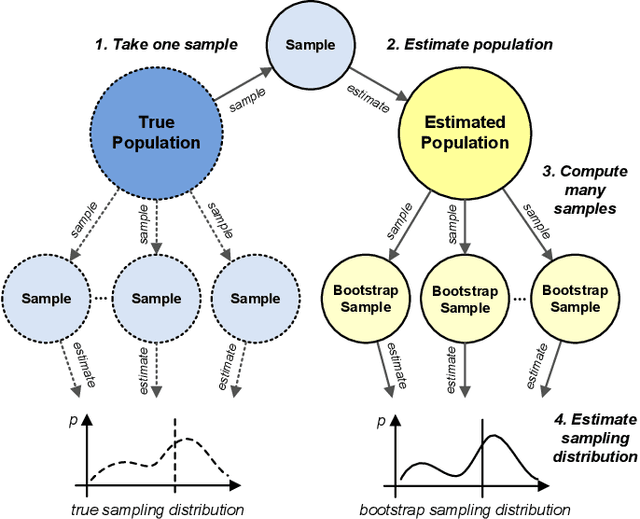
Process mining studies ways to derive value from process executions recorded in event logs of IT-systems, with process discovery the task of inferring a process model for an event log emitted by some unknown system. One quality criterion for discovered process models is generalization. Generalization seeks to quantify how well the discovered model describes future executions of the system, and is perhaps the least understood quality criterion in process mining. The lack of understanding is primarily a consequence of generalization seeking to measure properties over the entire future behavior of the system, when the only available sample of behavior is that provided by the event log itself. In this paper, we draw inspiration from computational statistics, and employ a bootstrap approach to estimate properties of a population based on a sample. Specifically, we define an estimator of the model's generalization based on the event log it was discovered from, and then use bootstrapping to measure the generalization of the model with respect to the system, and its statistical significance. Experiments demonstrate the feasibility of the approach in industrial settings.
Anytime Ranking on Document-Ordered Indexes
Apr 18, 2021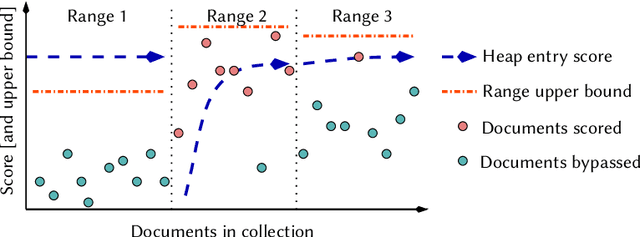


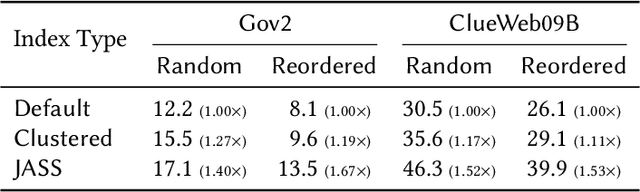
Inverted indexes continue to be a mainstay of text search engines, allowing efficient querying of large document collections. While there are a number of possible organizations, document-ordered indexes are the most common, since they are amenable to various query types, support index updates, and allow for efficient dynamic pruning operations. One disadvantage with document-ordered indexes is that high-scoring documents can be distributed across the document identifier space, meaning that index traversal algorithms that terminate early might put search effectiveness at risk. The alternative is impact-ordered indexes, which primarily support top-k disjunctions, but also allow for anytime query processing, where the search can be terminated at any time, with search quality improving as processing latency increases. Anytime query processing can be used to effectively reduce high-percentile tail latency which is essential for operational scenarios in which a service level agreement (SLA) imposes response time requirements. In this work, we show how document-ordered indexes can be organized such that they can be queried in an anytime fashion, enabling strict latency control with effective early termination. Our experiments show that processing document-ordered topical segments selected by a simple score estimator outperforms existing anytime algorithms, and allows query runtimes to be accurately limited in order to comply with SLA requirements.
Entropia: A Family of Entropy-Based Conformance Checking Measures for Process Mining
Sep 30, 2020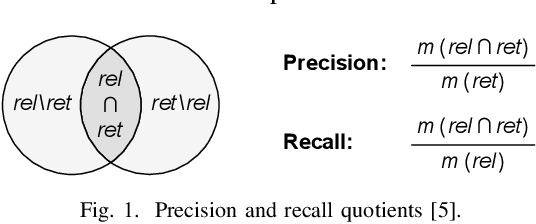
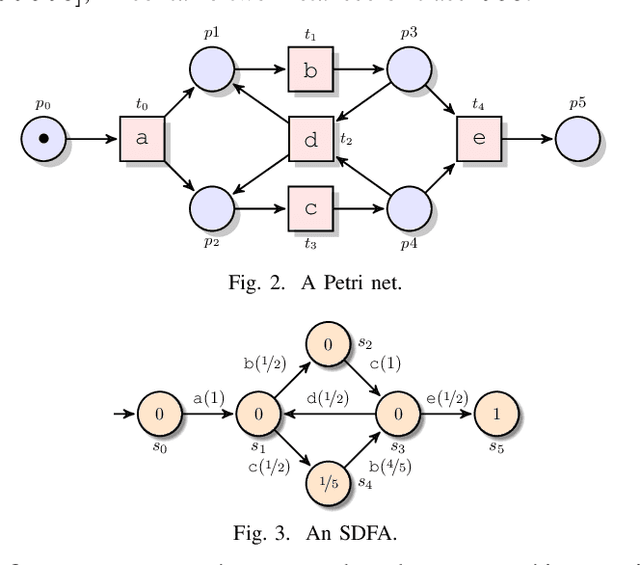

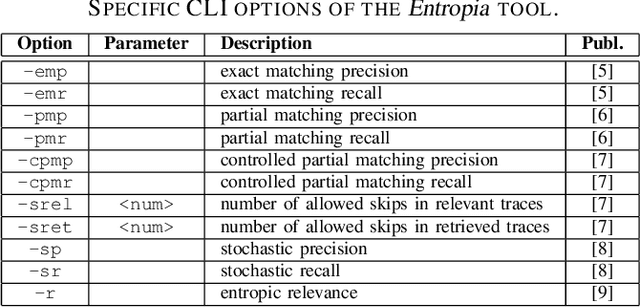
This paper presents a command-line tool, called Entropia, that implements a family of conformance checking measures for process mining founded on the notion of entropy from information theory. The measures allow quantifying classical non-deterministic and stochastic precision and recall quality criteria for process models automatically discovered from traces executed by IT-systems and recorded in their event logs. A process model has "good" precision with respect to the log it was discovered from if it does not encode many traces that are not part of the log, and has "good" recall if it encodes most of the traces from the log. By definition, the measures possess useful properties and can often be computed quickly.