 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA labeled dataset of simulated phlebotomy procedures for medical AI: polygon annotations for object detection and human-object interaction
Feb 04, 2026This data article presents a dataset of 11,884 labeled images documenting a simulated blood extraction (phlebotomy) procedure performed on a training arm. Images were extracted from high-definition videos recorded under controlled conditions and curated to reduce redundancy using Structural Similarity Index Measure (SSIM) filtering. An automated face-anonymization step was applied to all videos prior to frame selection. Each image contains polygon annotations for five medically relevant classes: syringe, rubber band, disinfectant wipe, gloves, and training arm. The annotations were exported in a segmentation format compatible with modern object detection frameworks (e.g., YOLOv8), ensuring broad usability. This dataset is partitioned into training (70%), validation (15%), and test (15%) subsets and is designed to advance research in medical training automation and human-object interaction. It enables multiple applications, including phlebotomy tool detection, procedural step recognition, workflow analysis, conformance checking, and the development of educational systems that provide structured feedback to medical trainees. The data and accompanying label files are publicly available on Zenodo.
Bootstrapping Generalization of Process Models Discovered From Event Data
Jul 08, 2021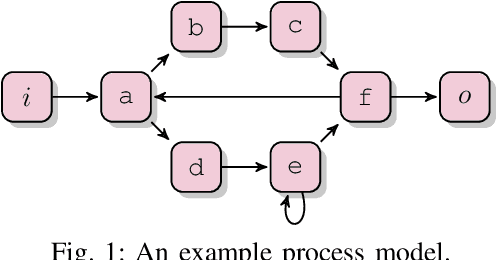
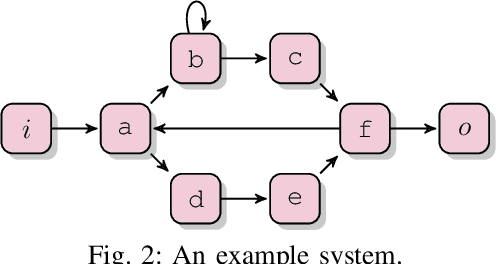
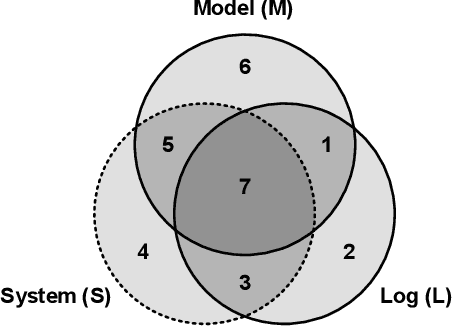
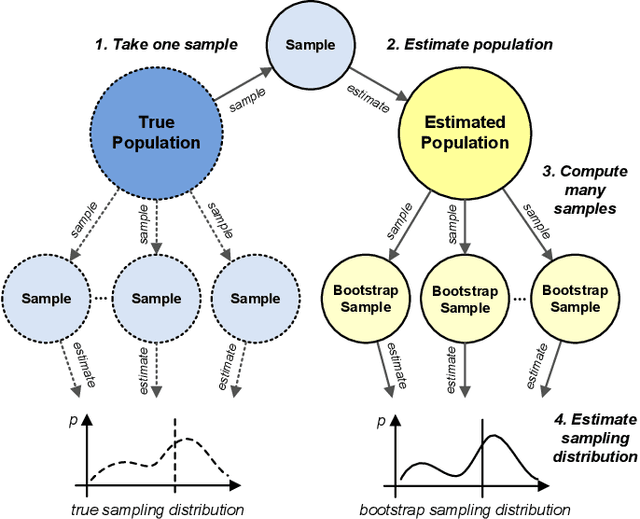
Process mining studies ways to derive value from process executions recorded in event logs of IT-systems, with process discovery the task of inferring a process model for an event log emitted by some unknown system. One quality criterion for discovered process models is generalization. Generalization seeks to quantify how well the discovered model describes future executions of the system, and is perhaps the least understood quality criterion in process mining. The lack of understanding is primarily a consequence of generalization seeking to measure properties over the entire future behavior of the system, when the only available sample of behavior is that provided by the event log itself. In this paper, we draw inspiration from computational statistics, and employ a bootstrap approach to estimate properties of a population based on a sample. Specifically, we define an estimator of the model's generalization based on the event log it was discovered from, and then use bootstrapping to measure the generalization of the model with respect to the system, and its statistical significance. Experiments demonstrate the feasibility of the approach in industrial settings.
Entropia: A Family of Entropy-Based Conformance Checking Measures for Process Mining
Sep 30, 2020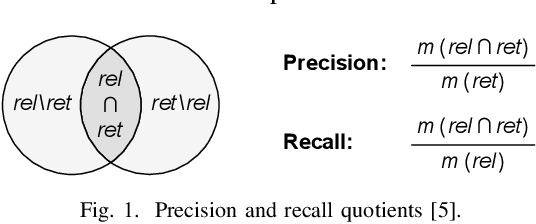

This paper presents a command-line tool, called Entropia, that implements a family of conformance checking measures for process mining founded on the notion of entropy from information theory. The measures allow quantifying classical non-deterministic and stochastic precision and recall quality criteria for process models automatically discovered from traces executed by IT-systems and recorded in their event logs. A process model has "good" precision with respect to the log it was discovered from if it does not encode many traces that are not part of the log, and has "good" recall if it encodes most of the traces from the log. By definition, the measures possess useful properties and can often be computed quickly.
An Entropic Relevance Measure for Stochastic Conformance Checking in Process Mining
Aug 26, 2020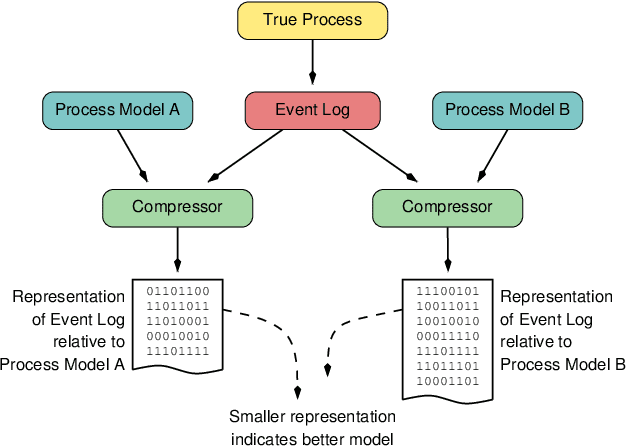
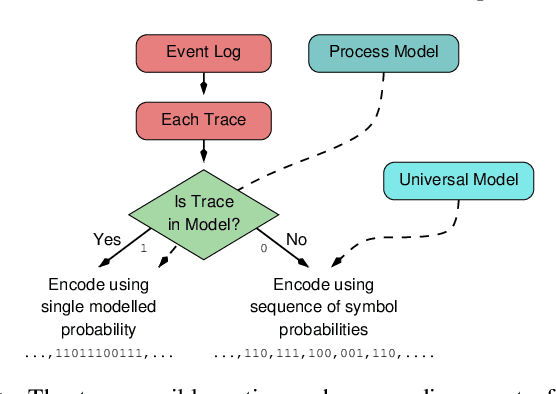
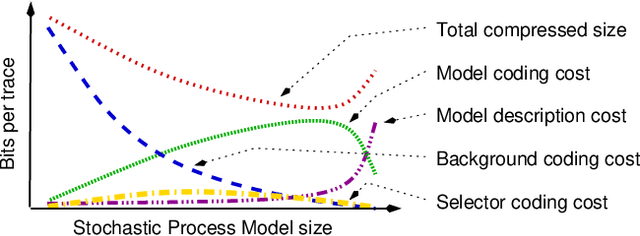
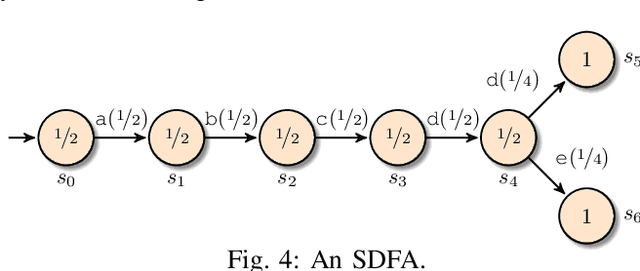
Given an event log as a collection of recorded real-world process traces, process mining aims to automatically construct a process model that is both simple and provides a useful explanation of the traces. Conformance checking techniques are then employed to characterize and quantify commonalities and discrepancies between the log's traces and the candidate models. Recent approaches to conformance checking acknowledge that the elements being compared are inherently stochastic - for example, some traces occur frequently and others infrequently - and seek to incorporate this knowledge in their analyses. Here we present an entropic relevance measure for stochastic conformance checking, computed as the average number of bits required to compress each of the log's traces, based on the structure and information about relative likelihoods provided by the model. The measure penalizes traces from the event log not captured by the model and traces described by the model but absent in the event log, thus addressing both precision and recall quality criteria at the same time. We further show that entropic relevance is computable in time linear in the size of the log, and provide evaluation outcomes that demonstrate the feasibility of using the new approach in industrial settings.