 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Business Process Management: A Research Manifesto
Mar 19, 2026This paper presents a manifesto that articulates the conceptual foundations of Agentic Business Process Management (APM), an extension of Business Process Management (BPM) for governing autonomous agents executing processes in organizations. From a management perspective, APM represents a paradigm shift from the traditional process view of the business process, driven by the realization of process awareness and an agent-oriented abstraction, where software and human agents act as primary functional entities that perceive, reason, and act within explicit process frames. This perspective marks a shift from traditional, automation-oriented BPM toward systems in which autonomy is constrained, aligned, and made operational through process awareness. We introduce the core abstractions and architectural elements required to realize APM systems and elaborate on four key capabilities that such APM agents must support: framed autonomy, explainability, conversational actionability, and self-modification. These capabilities jointly ensure that agents' goals are aligned with organizational goals and that agents behave in a framed yet proactive manner in pursuing those goals. We discuss the extent to which the capabilities can be realized and identify research challenges whose resolution requires further advances in BPM, AI, and multi-agent systems. The manifesto thus serves as a roadmap for bridging these communities and for guiding the development of APM systems in practice.
Stochastic Alignments: Matching an Observed Trace to Stochastic Process Models
Jul 09, 2025Process mining leverages event data extracted from IT systems to generate insights into the business processes of organizations. Such insights benefit from explicitly considering the frequency of behavior in business processes, which is captured by stochastic process models. Given an observed trace and a stochastic process model, conventional alignment-based conformance checking techniques face a fundamental limitation: They prioritize matching the trace to a model path with minimal deviations, which may, however, lead to selecting an unlikely path. In this paper, we study the problem of matching an observed trace to a stochastic process model by identifying a likely model path with a low edit distance to the trace. We phrase this as an optimization problem and develop a heuristic-guided path-finding algorithm to solve it. Our open-source implementation demonstrates the feasibility of the approach and shows that it can provide new, useful diagnostic insights for analysts.
PELP: Pioneer Event Log Prediction Using Sequence-to-Sequence Neural Networks
Dec 15, 2023Process mining, a data-driven approach for analyzing, visualizing, and improving business processes using event logs, has emerged as a powerful technique in the field of business process management. Process forecasting is a sub-field of process mining that studies how to predict future processes and process models. In this paper, we introduce and motivate the problem of event log prediction and present our approach to solving the event log prediction problem, in particular, using the sequence-to-sequence deep learning approach. We evaluate and analyze the prediction outcomes on a variety of synthetic logs and seven real-life logs and show that our approach can generate perfect predictions on synthetic logs and that deep learning techniques have the potential to be applied in real-world event log prediction tasks. We further provide practical recommendations for event log predictions grounded in the outcomes of the conducted experiments.
Stochastic Directly-Follows Process Discovery Using Grammatical Inference
Dec 09, 2023



Starting with a collection of traces generated by process executions, process discovery is the task of constructing a simple model that describes the process, where simplicity is often measured in terms of model size. The challenge of process discovery is that the process of interest is unknown, and that while the input traces constitute positive examples of process executions, no negative examples are available. Many commercial tools discover Directly-Follows Graphs, in which nodes represent the observable actions of the process, and directed arcs indicate execution order possibilities over the actions. We propose a new approach for discovering sound Directly-Follows Graphs that is grounded in grammatical inference over the input traces. To promote the discovery of small graphs that also describe the process accurately we design and evaluate a genetic algorithm that supports the convergence of the inference parameters to the areas that lead to the discovery of interesting models. Experiments over real-world datasets confirm that our new approach can construct smaller models that represent the input traces and their frequencies more accurately than the state-of-the-art technique. Reasoning over the frequencies of encoded traces also becomes possible, due to the stochastic semantics of the action graphs we propose, which, for the first time, are interpreted as models that describe the stochastic languages of action traces.
Data-Driven Goal Recognition in Transhumeral Prostheses Using Process Mining Techniques
Sep 15, 2023A transhumeral prosthesis restores missing anatomical segments below the shoulder, including the hand. Active prostheses utilize real-valued, continuous sensor data to recognize patient target poses, or goals, and proactively move the artificial limb. Previous studies have examined how well the data collected in stationary poses, without considering the time steps, can help discriminate the goals. In this case study paper, we focus on using time series data from surface electromyography electrodes and kinematic sensors to sequentially recognize patients' goals. Our approach involves transforming the data into discrete events and training an existing process mining-based goal recognition system. Results from data collected in a virtual reality setting with ten subjects demonstrate the effectiveness of our proposed goal recognition approach, which achieves significantly better precision and recall than the state-of-the-art machine learning techniques and is less confident when wrong, which is beneficial when approximating smoother movements of prostheses.
Large Process Models: Business Process Management in the Age of Generative AI
Sep 11, 2023
The continued success of Large Language Models (LLMs) and other generative artificial intelligence approaches highlights the advantages that large information corpora can have over rigidly defined symbolic models, but also serves as a proof-point of the challenges that purely statistics-based approaches have in terms of safety and trustworthiness. As a framework for contextualizing the potential, as well as the limitations of LLMs and other foundation model-based technologies, we propose the concept of a Large Process Model (LPM) that combines the correlation power of LLMs with the analytical precision and reliability of knowledge-based systems and automated reasoning approaches. LPMs are envisioned to directly utilize the wealth of process management experience that experts have accumulated, as well as process performance data of organizations with diverse characteristics, e.g., regarding size, region, or industry. In this vision, the proposed LPM would allow organizations to receive context-specific (tailored) process and other business models, analytical deep-dives, and improvement recommendations. As such, they would allow to substantially decrease the time and effort required for business transformation, while also allowing for deeper, more impactful, and more actionable insights than previously possible. We argue that implementing an LPM is feasible, but also highlight limitations and research challenges that need to be solved to implement particular aspects of the LPM vision.
Learning When to Treat Business Processes: Prescriptive Process Monitoring with Causal Inference and Reinforcement Learning
Mar 07, 2023



Increasing the success rate of a process, i.e. the percentage of cases that end in a positive outcome, is a recurrent process improvement goal. At runtime, there are often certain actions (a.k.a. treatments) that workers may execute to lift the probability that a case ends in a positive outcome. For example, in a loan origination process, a possible treatment is to issue multiple loan offers to increase the probability that the customer takes a loan. Each treatment has a cost. Thus, when defining policies for prescribing treatments to cases, managers need to consider the net gain of the treatments. Also, the effect of a treatment varies over time: treating a case earlier may be more effective than later in a case. This paper presents a prescriptive monitoring method that automates this decision-making task. The method combines causal inference and reinforcement learning to learn treatment policies that maximize the net gain. The method leverages a conformal prediction technique to speed up the convergence of the reinforcement learning mechanism by separating cases that are likely to end up in a positive or negative outcome, from uncertain cases. An evaluation on two real-life datasets shows that the proposed method outperforms a state-of-the-art baseline.
Bootstrapping Generalization of Process Models Discovered From Event Data
Jul 08, 2021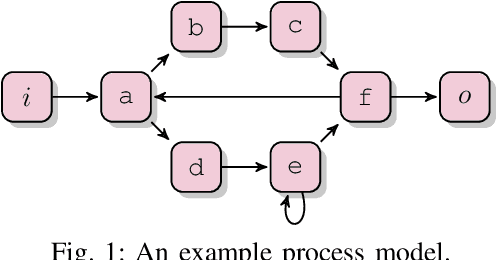
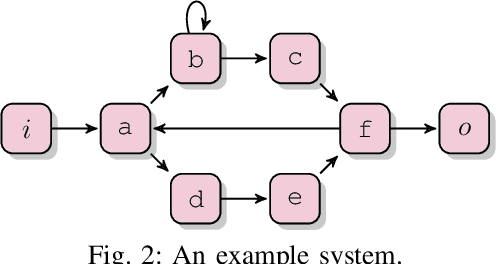
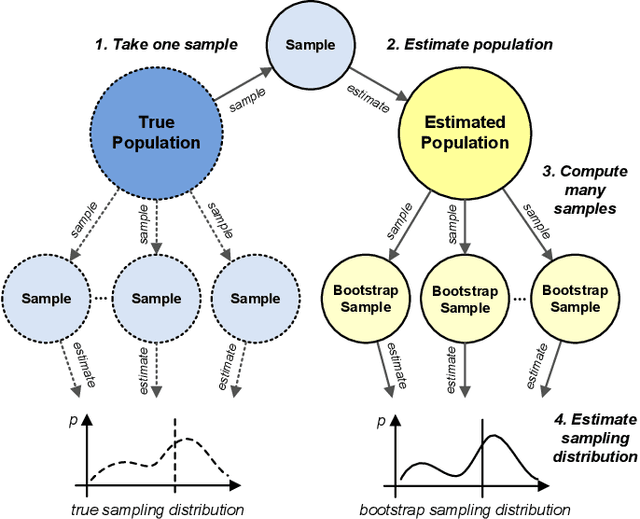
Process mining studies ways to derive value from process executions recorded in event logs of IT-systems, with process discovery the task of inferring a process model for an event log emitted by some unknown system. One quality criterion for discovered process models is generalization. Generalization seeks to quantify how well the discovered model describes future executions of the system, and is perhaps the least understood quality criterion in process mining. The lack of understanding is primarily a consequence of generalization seeking to measure properties over the entire future behavior of the system, when the only available sample of behavior is that provided by the event log itself. In this paper, we draw inspiration from computational statistics, and employ a bootstrap approach to estimate properties of a population based on a sample. Specifically, we define an estimator of the model's generalization based on the event log it was discovered from, and then use bootstrapping to measure the generalization of the model with respect to the system, and its statistical significance. Experiments demonstrate the feasibility of the approach in industrial settings.
Automated Repair of Process Models with Non-Local Constraints Using State-Based Region Theory
Jun 26, 2021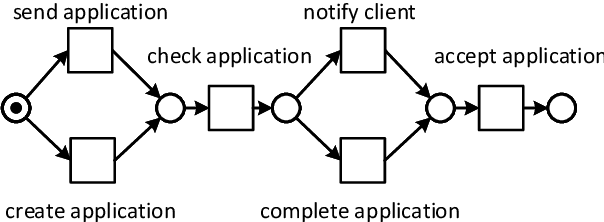
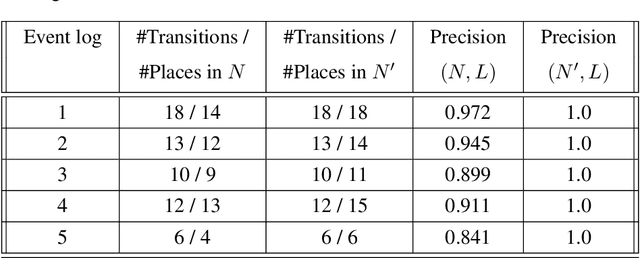
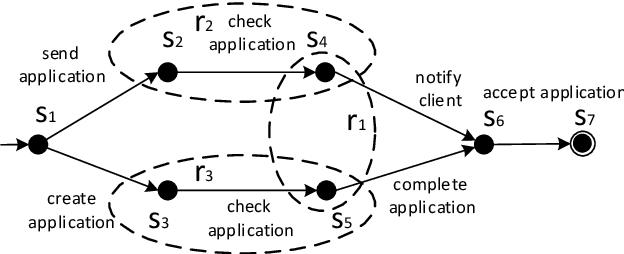
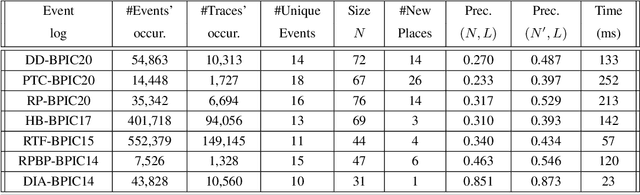
State-of-the-art process discovery methods construct free-choice process models from event logs. Consequently, the constructed models do not take into account indirect dependencies between events. Whenever the input behaviour is not free-choice, these methods fail to provide a precise model. In this paper, we propose a novel approach for enhancing free-choice process models by adding non-free-choice constructs discovered a-posteriori via region-based techniques. This allows us to benefit from the performance of existing process discovery methods and the accuracy of the employed fundamental synthesis techniques. We prove that the proposed approach preserves fitness with respect to the event log while improving the precision when indirect dependencies exist. The approach has been implemented and tested on both synthetic and real-life datasets. The results show its effectiveness in repairing models discovered from event logs.
Process Model Forecasting Using Time Series Analysis of Event Sequence Data
May 03, 2021



Process analytics is the field focusing on predictions for individual process instances or overall process models. At the instance level, various novel techniques have been recently devised, tackling next activity, remaining time, and outcome prediction. At the model level, there is a notable void. It is the ambition of this paper to fill this gap. To this end, we develop a technique to forecast the entire process model from historical event data. A forecasted model is a will-be process model representing a probable future state of the overall process. Such a forecast helps to investigate the consequences of drift and emerging bottlenecks. Our technique builds on a representation of event data as multiple time series, each capturing the evolution of a behavioural aspect of the process model, such that corresponding forecasting techniques can be applied. Our implementation demonstrates the accuracy of our technique on real-world event log data.