 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Sequential Causal Optimization of Process Interventions
Dec 22, 2025



Prescriptive Process Monitoring (PresPM) recommends interventions during business processes to optimize key performance indicators (KPIs). In realistic settings, interventions are rarely isolated: organizations need to align sequences of interventions to jointly steer the outcome of a case. Existing PresPM approaches fall short in this respect. Many focus on a single intervention decision, while others treat multiple interventions independently, ignoring how they interact over time. Methods that do address these dependencies depend either on simulation or data augmentation to approximate the process to train a Reinforcement Learning (RL) agent, which can create a reality gap and introduce bias. We introduce SCOPE, a PresPM approach that learns aligned sequential intervention recommendations. SCOPE employs backward induction to estimate the effect of each candidate intervention action, propagating its impact from the final decision point back to the first. By leveraging causal learners, our method can utilize observational data directly, unlike methods that require constructing process approximations for reinforcement learning. Experiments on both an existing synthetic dataset and a new semi-synthetic dataset show that SCOPE consistently outperforms state-of-the-art PresPM techniques in optimizing the KPI. The novel semi-synthetic setup, based on a real-life event log, is provided as a reusable benchmark for future work on sequential PresPM.
Time Series Foundation Models for Process Model Forecasting
Dec 08, 2025



Process Model Forecasting (PMF) aims to predict how the control-flow structure of a process evolves over time by modeling the temporal dynamics of directly-follows (DF) relations, complementing predictive process monitoring that focuses on single-case prefixes. Prior benchmarks show that machine learning and deep learning models provide only modest gains over statistical baselines, mainly due to the sparsity and heterogeneity of the DF time series. We investigate Time Series Foundation Models (TSFMs), large pre-trained models for generic time series, as an alternative for PMF. Using DF time series derived from real-life event logs, we compare zero-shot use of TSFMs, without additional training, with fine-tuned variants adapted on PMF-specific data. TSFMs generally achieve lower forecasting errors (MAE and RMSE) than traditional and specialized models trained from scratch on the same logs, indicating effective transfer of temporal structure from non-process domains. While fine-tuning can further improve accuracy, the gains are often small and may disappear on smaller or more complex datasets, so zero-shot use remains a strong default. Our study highlights the generalization capability and data efficiency of TSFMs for process-related time series and, to the best of our knowledge, provides the first systematic evaluation of temporal foundation models for PMF.
Bridging Language Gaps: Enhancing Few-Shot Language Adaptation
Aug 26, 2025The disparity in language resources poses a challenge in multilingual NLP, with high-resource languages benefiting from extensive data, while low-resource languages lack sufficient data for effective training. Our Contrastive Language Alignment with Prompting (CoLAP) method addresses this gap by integrating contrastive learning with cross-lingual representations, facilitating task-specific knowledge transfer from high-resource to lower-resource languages. The primary advantage of our approach is its data efficiency, enabling rapid adaptation to new languages and reducing the need for large labeled datasets. We conduct experiments with multilingual encoder-only and decoder-only language models on natural language understanding tasks, including natural language inference and relation extraction, evaluating performance across both high- and low-resource languages. Our results demonstrate that CoLAP outperforms few-shot cross-lingual transfer baselines and in-context learning, even with limited available data. This effectively narrows the cross-lingual performance gap, contributing to the development of more efficient multilingual NLP techniques.
On the Performance of LLMs for Real Estate Appraisal
Jun 13, 2025The real estate market is vital to global economies but suffers from significant information asymmetry. This study examines how Large Language Models (LLMs) can democratize access to real estate insights by generating competitive and interpretable house price estimates through optimized In-Context Learning (ICL) strategies. We systematically evaluate leading LLMs on diverse international housing datasets, comparing zero-shot, few-shot, market report-enhanced, and hybrid prompting techniques. Our results show that LLMs effectively leverage hedonic variables, such as property size and amenities, to produce meaningful estimates. While traditional machine learning models remain strong for pure predictive accuracy, LLMs offer a more accessible, interactive and interpretable alternative. Although self-explanations require cautious interpretation, we find that LLMs explain their predictions in agreement with state-of-the-art models, confirming their trustworthiness. Carefully selected in-context examples based on feature similarity and geographic proximity, significantly enhance LLM performance, yet LLMs struggle with overconfidence in price intervals and limited spatial reasoning. We offer practical guidance for structured prediction tasks through prompt optimization. Our findings highlight LLMs' potential to improve transparency in real estate appraisal and provide actionable insights for stakeholders.
Language Fusion for Parameter-Efficient Cross-lingual Transfer
Jan 12, 2025Limited availability of multilingual text corpora for training language models often leads to poor performance on downstream tasks due to undertrained representation spaces for languages other than English. This 'under-representation' has motivated recent cross-lingual transfer methods to leverage the English representation space by e.g. mixing English and 'non-English' tokens at the input level or extending model parameters to accommodate new languages. However, these approaches often come at the cost of increased computational complexity. We propose Fusion forLanguage Representations (FLARE) in adapters, a novel method that enhances representation quality and downstream performance for languages other than English while maintaining parameter efficiency. FLARE integrates source and target language representations within low-rank (LoRA) adapters using lightweight linear transformations, maintaining parameter efficiency while improving transfer performance. A series of experiments across representative cross-lingual natural language understanding tasks, including natural language inference, question-answering and sentiment analysis, demonstrate FLARE's effectiveness. FLARE achieves performance improvements of 4.9% for Llama 3.1 and 2.2% for Gemma~2 compared to standard LoRA fine-tuning on question-answering tasks, as measured by the exact match metric.
Generating Realistic Adversarial Examples for Business Processes using Variational Autoencoders
Nov 21, 2024



In predictive process monitoring, predictive models are vulnerable to adversarial attacks, where input perturbations can lead to incorrect predictions. Unlike in computer vision, where these perturbations are designed to be imperceptible to the human eye, the generation of adversarial examples in predictive process monitoring poses unique challenges. Minor changes to the activity sequences can create improbable or even impossible scenarios to occur due to underlying constraints such as regulatory rules or process constraints. To address this, we focus on generating realistic adversarial examples tailored to the business process context, in contrast to the imperceptible, pixel-level changes commonly seen in computer vision adversarial attacks. This paper introduces two novel latent space attacks, which generate adversaries by adding noise to the latent space representation of the input data, rather than directly modifying the input attributes. These latent space methods are domain-agnostic and do not rely on process-specific knowledge, as we restrict the generation of adversarial examples to the learned class-specific data distributions by directly perturbing the latent space representation of the business process executions. We evaluate these two latent space methods with six other adversarial attacking methods on eleven real-life event logs and four predictive models. The first three attacking methods directly permute the activities of the historically observed business process executions. The fourth method constrains the adversarial examples to lie within the same data distribution as the original instances, by projecting the adversarial examples to the original data distribution.
Native Design Bias: Studying the Impact of English Nativeness on Language Model Performance
Jun 25, 2024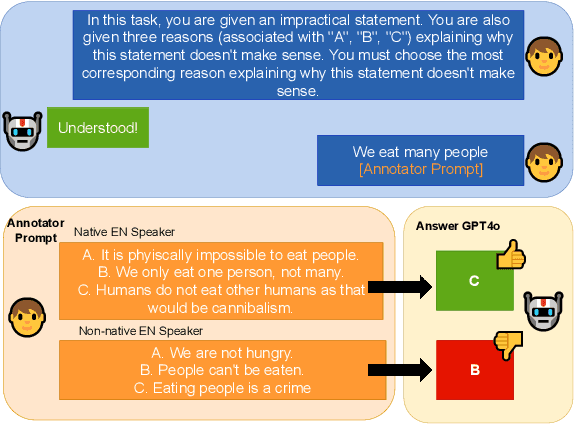
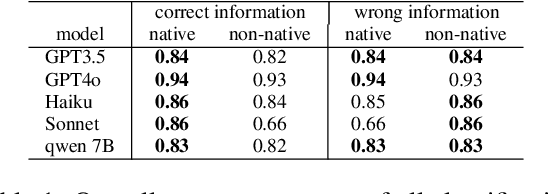
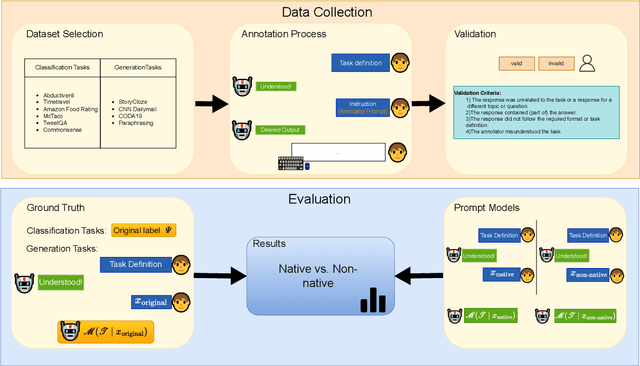
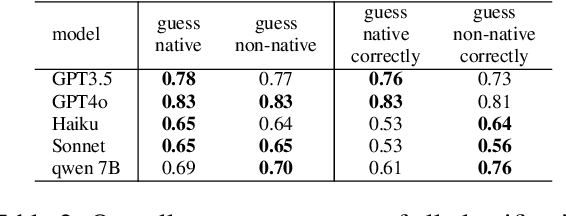
Large Language Models (LLMs) excel at providing information acquired during pretraining on large-scale corpora and following instructions through user prompts. This study investigates whether the quality of LLM responses varies depending on the demographic profile of users. Considering English as the global lingua franca, along with the diversity of its dialects among speakers of different native languages, we explore whether non-native English speakers receive lower-quality or even factually incorrect responses from LLMs more frequently. Our results show that performance discrepancies occur when LLMs are prompted by native versus non-native English speakers and persist when comparing native speakers from Western countries with others. Additionally, we find a strong anchoring effect when the model recognizes or is made aware of the user's nativeness, which further degrades the response quality when interacting with non-native speakers. Our analysis is based on a newly collected dataset with over 12,000 unique annotations from 124 annotators, including information on their native language and English proficiency.
Efficient Information Extraction in Few-Shot Relation Classification through Contrastive Representation Learning
Mar 25, 2024Differentiating relationships between entity pairs with limited labeled instances poses a significant challenge in few-shot relation classification. Representations of textual data extract rich information spanning the domain, entities, and relations. In this paper, we introduce a novel approach to enhance information extraction combining multiple sentence representations and contrastive learning. While representations in relation classification are commonly extracted using entity marker tokens, we argue that substantial information within the internal model representations remains untapped. To address this, we propose aligning multiple sentence representations, such as the [CLS] token, the [MASK] token used in prompting, and entity marker tokens. Our method employs contrastive learning to extract complementary discriminative information from these individual representations. This is particularly relevant in low-resource settings where information is scarce. Leveraging multiple sentence representations is especially effective in distilling discriminative information for relation classification when additional information, like relation descriptions, are not available. We validate the adaptability of our approach, maintaining robust performance in scenarios that include relation descriptions, and showcasing its flexibility to adapt to different resource constraints.
CORE: A Few-Shot Company Relation Classification Dataset for Robust Domain Adaptation
Oct 18, 2023We introduce CORE, a dataset for few-shot relation classification (RC) focused on company relations and business entities. CORE includes 4,708 instances of 12 relation types with corresponding textual evidence extracted from company Wikipedia pages. Company names and business entities pose a challenge for few-shot RC models due to the rich and diverse information associated with them. For example, a company name may represent the legal entity, products, people, or business divisions depending on the context. Therefore, deriving the relation type between entities is highly dependent on textual context. To evaluate the performance of state-of-the-art RC models on the CORE dataset, we conduct experiments in the few-shot domain adaptation setting. Our results reveal substantial performance gaps, confirming that models trained on different domains struggle to adapt to CORE. Interestingly, we find that models trained on CORE showcase improved out-of-domain performance, which highlights the importance of high-quality data for robust domain adaptation. Specifically, the information richness embedded in business entities allows models to focus on contextual nuances, reducing their reliance on superficial clues such as relation-specific verbs. In addition to the dataset, we provide relevant code snippets to facilitate reproducibility and encourage further research in the field.
Investigating Bias in Multilingual Language Models: Cross-Lingual Transfer of Debiasing Techniques
Oct 16, 2023



This paper investigates the transferability of debiasing techniques across different languages within multilingual models. We examine the applicability of these techniques in English, French, German, and Dutch. Using multilingual BERT (mBERT), we demonstrate that cross-lingual transfer of debiasing techniques is not only feasible but also yields promising results. Surprisingly, our findings reveal no performance disadvantages when applying these techniques to non-English languages. Using translations of the CrowS-Pairs dataset, our analysis identifies SentenceDebias as the best technique across different languages, reducing bias in mBERT by an average of 13%. We also find that debiasing techniques with additional pretraining exhibit enhanced cross-lingual effectiveness for the languages included in the analyses, particularly in lower-resource languages. These novel insights contribute to a deeper understanding of bias mitigation in multilingual language models and provide practical guidance for debiasing techniques in different language contexts.