 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE: A Few-Shot Company Relation Classification Dataset for Robust Domain Adaptation
Oct 18, 2023We introduce CORE, a dataset for few-shot relation classification (RC) focused on company relations and business entities. CORE includes 4,708 instances of 12 relation types with corresponding textual evidence extracted from company Wikipedia pages. Company names and business entities pose a challenge for few-shot RC models due to the rich and diverse information associated with them. For example, a company name may represent the legal entity, products, people, or business divisions depending on the context. Therefore, deriving the relation type between entities is highly dependent on textual context. To evaluate the performance of state-of-the-art RC models on the CORE dataset, we conduct experiments in the few-shot domain adaptation setting. Our results reveal substantial performance gaps, confirming that models trained on different domains struggle to adapt to CORE. Interestingly, we find that models trained on CORE showcase improved out-of-domain performance, which highlights the importance of high-quality data for robust domain adaptation. Specifically, the information richness embedded in business entities allows models to focus on contextual nuances, reducing their reliance on superficial clues such as relation-specific verbs. In addition to the dataset, we provide relevant code snippets to facilitate reproducibility and encourage further research in the field.
Churn Prediction with Sequential Data and Deep Neural Networks. A Comparative Analysis
Sep 24, 2019
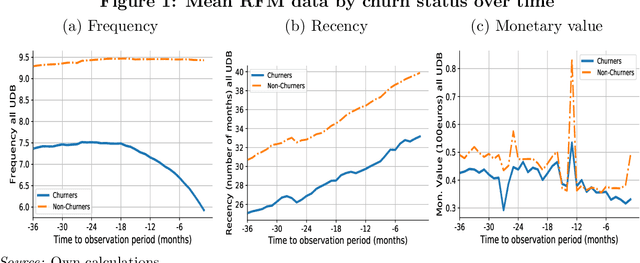


Off-the-shelf machine learning algorithms for prediction such as regularized logistic regression cannot exploit the information of time-varying features without previously using an aggregation procedure of such sequential data. However, recurrent neural networks provide an alternative approach by which time-varying features can be readily used for modeling. This paper assesses the performance of neural networks for churn modeling using recency, frequency, and monetary value data from a financial services provider. Results show that RFM variables in combination with LSTM neural networks have larger top-decile lift and expected maximum profit metrics than regularized logistic regression models with commonly-used demographic variables. Moreover, we show that using the fitted probabilities from the LSTM as feature in the logistic regression increases the out-of-sample performance of the latter by 25 percent compared to a model with only static features.