 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimateCause: Complex and Implicit Causal Structures in Climate Reports
Apr 16, 2026Understanding climate change requires reasoning over complex causal networks. Yet, existing causal discovery datasets predominantly capture explicit, direct causal relations. We introduce ClimateCause, a manually expert-annotated dataset of higher-order causal structures from science-for-policy climate reports, including implicit and nested causality. Cause-effect expressions are normalized and disentangled into individual causal relations to facilitate graph construction, with unique annotations for cause-effect correlation, relation type, and spatiotemporal context. We further demonstrate ClimateCause's value for quantifying readability based on the semantic complexity of causal graphs underlying a statement. Finally, large language model benchmarking on correlation inference and causal chain reasoning highlights the latter as a key challenge.
NewsRECON: News article REtrieval for image CONtextualization
Jan 20, 2026Identifying when and where a news image was taken is crucial for journalists and forensic experts to produce credible stories and debunk misinformation. While many existing methods rely on reverse image search (RIS) engines, these tools often fail to return results, thereby limiting their practical applicability. In this work, we address the challenging scenario where RIS evidence is unavailable. We introduce NewsRECON, a method that links images to relevant news articles to infer their date and location from article metadata. NewsRECON leverages a corpus of over 90,000 articles and integrates: (1) a bi-encoder for retrieving event-relevant articles; (2) two cross-encoders for reranking articles by location and event consistency. Experiments on the TARA and 5Pils-OOC show that NewsRECON outperforms prior work and can be combined with a multimodal large language model to achieve new SOTA results in the absence of RIS evidence. We make our code available.
Structured Information for Improving Spatial Relationships in Text-to-Image Generation
Sep 19, 2025
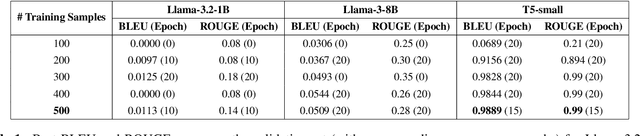
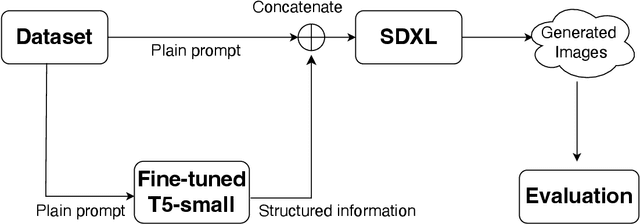

Text-to-image (T2I) generation has advanced rapidly, yet faithfully capturing spatial relationships described in natural language prompts remains a major challenge. Prior efforts have addressed this issue through prompt optimization, spatially grounded generation, and semantic refinement. This work introduces a lightweight approach that augments prompts with tuple-based structured information, using a fine-tuned language model for automatic conversion and seamless integration into T2I pipelines. Experimental results demonstrate substantial improvements in spatial accuracy, without compromising overall image quality as measured by Inception Score. Furthermore, the automatically generated tuples exhibit quality comparable to human-crafted tuples. This structured information provides a practical and portable solution to enhance spatial relationships in T2I generation, addressing a key limitation of current large-scale generative systems.
Bridging Language Gaps: Enhancing Few-Shot Language Adaptation
Aug 26, 2025The disparity in language resources poses a challenge in multilingual NLP, with high-resource languages benefiting from extensive data, while low-resource languages lack sufficient data for effective training. Our Contrastive Language Alignment with Prompting (CoLAP) method addresses this gap by integrating contrastive learning with cross-lingual representations, facilitating task-specific knowledge transfer from high-resource to lower-resource languages. The primary advantage of our approach is its data efficiency, enabling rapid adaptation to new languages and reducing the need for large labeled datasets. We conduct experiments with multilingual encoder-only and decoder-only language models on natural language understanding tasks, including natural language inference and relation extraction, evaluating performance across both high- and low-resource languages. Our results demonstrate that CoLAP outperforms few-shot cross-lingual transfer baselines and in-context learning, even with limited available data. This effectively narrows the cross-lingual performance gap, contributing to the development of more efficient multilingual NLP techniques.
Large Language Models Reasoning Abilities Under Non-Ideal Conditions After RL-Fine-Tuning
Aug 06, 2025Reinforcement learning (RL) has become a key technique for enhancing the reasoning abilities of large language models (LLMs), with policy-gradient algorithms dominating the post-training stage because of their efficiency and effectiveness. However, most existing benchmarks evaluate large-language-model reasoning under idealized settings, overlooking performance in realistic, non-ideal scenarios. We identify three representative non-ideal scenarios with practical relevance: summary inference, fine-grained noise suppression, and contextual filtering. We introduce a new research direction guided by brain-science findings that human reasoning remains reliable under imperfect inputs. We formally define and evaluate these challenging scenarios. We fine-tune three LLMs and a state-of-the-art large vision-language model (LVLM) using RL with a representative policy-gradient algorithm and then test their performance on eight public datasets. Our results reveal that while RL fine-tuning improves baseline reasoning under idealized settings, performance declines significantly across all three non-ideal scenarios, exposing critical limitations in advanced reasoning capabilities. Although we propose a scenario-specific remediation method, our results suggest current methods leave these reasoning deficits largely unresolved. This work highlights that the reasoning abilities of large models are often overstated and underscores the importance of evaluating models under non-ideal scenarios. The code and data will be released at XXXX.
Consistent Story Generation with Asymmetry Zigzag Sampling
Jun 12, 2025Text-to-image generation models have made significant progress in producing high-quality images from textual descriptions, yet they continue to struggle with maintaining subject consistency across multiple images, a fundamental requirement for visual storytelling. Existing methods attempt to address this by either fine-tuning models on large-scale story visualization datasets, which is resource-intensive, or by using training-free techniques that share information across generations, which still yield limited success. In this paper, we introduce a novel training-free sampling strategy called Zigzag Sampling with Asymmetric Prompts and Visual Sharing to enhance subject consistency in visual story generation. Our approach proposes a zigzag sampling mechanism that alternates between asymmetric prompting to retain subject characteristics, while a visual sharing module transfers visual cues across generated images to %further enforce consistency. Experimental results, based on both quantitative metrics and qualitative evaluations, demonstrate that our method significantly outperforms previous approaches in generating coherent and consistent visual stories. The code is available at https://github.com/Mingxiao-Li/Asymmetry-Zigzag-StoryDiffusion.
Mitigating Negative Interference in Multilingual Sequential Knowledge Editing through Null-Space Constraints
Jun 12, 2025Efficiently updating multilingual knowledge in large language models (LLMs), while preserving consistent factual representations across languages, remains a long-standing and unresolved challenge. While deploying separate editing systems for each language might seem viable, this approach incurs substantial costs due to the need to manage multiple models. A more efficient solution involves integrating knowledge updates across all languages into a unified model. However, performing sequential edits across languages often leads to destructive parameter interference, significantly degrading multilingual generalization and the accuracy of injected knowledge. To address this challenge, we propose LangEdit, a novel null-space constrained framework designed to precisely isolate language-specific knowledge updates. The core innovation of LangEdit lies in its ability to project parameter updates for each language onto the orthogonal complement of previous updated subspaces. This approach mathematically guarantees update independence while preserving multilingual generalization capabilities. We conduct a comprehensive evaluation across three model architectures, six languages, and four downstream tasks, demonstrating that LangEdit effectively mitigates parameter interference and outperforms existing state-of-the-art editing methods. Our results highlight its potential for enabling efficient and accurate multilingual knowledge updates in LLMs. The code is available at https://github.com/VRCMF/LangEdit.git.
Reduction of Supervision for Biomedical Knowledge Discovery
Apr 13, 2025Knowledge discovery is hindered by the increasing volume of publications and the scarcity of extensive annotated data. To tackle the challenge of information overload, it is essential to employ automated methods for knowledge extraction and processing. Finding the right balance between the level of supervision and the effectiveness of models poses a significant challenge. While supervised techniques generally result in better performance, they have the major drawback of demanding labeled data. This requirement is labor-intensive and time-consuming and hinders scalability when exploring new domains. In this context, our study addresses the challenge of identifying semantic relationships between biomedical entities (e.g., diseases, proteins) in unstructured text while minimizing dependency on supervision. We introduce a suite of unsupervised algorithms based on dependency trees and attention mechanisms and employ a range of pointwise binary classification methods. Transitioning from weakly supervised to fully unsupervised settings, we assess the methods' ability to learn from data with noisy labels. The evaluation on biomedical benchmark datasets explores the effectiveness of the methods. Our approach tackles a central issue in knowledge discovery: balancing performance with minimal supervision. By gradually decreasing supervision, we assess the robustness of pointwise binary classification techniques in handling noisy labels, revealing their capability to shift from weakly supervised to entirely unsupervised scenarios. Comprehensive benchmarking offers insights into the effectiveness of these techniques, suggesting an encouraging direction toward adaptable knowledge discovery systems, representing progress in creating data-efficient methodologies for extracting useful insights when annotated data is limited.
Towards More Accurate Personalized Image Generation: Addressing Overfitting and Evaluation Bias
Mar 09, 2025Personalized image generation via text prompts has great potential to improve daily life and professional work by facilitating the creation of customized visual content. The aim of image personalization is to create images based on a user-provided subject while maintaining both consistency of the subject and flexibility to accommodate various textual descriptions of that subject. However, current methods face challenges in ensuring fidelity to the text prompt while not overfitting to the training data. In this work, we introduce a novel training pipeline that incorporates an attractor to filter out distractions in training images, allowing the model to focus on learning an effective representation of the personalized subject. Moreover, current evaluation methods struggle due to the lack of a dedicated test set. The evaluation set-up typically relies on the training data of the personalization task to compute text-image and image-image similarity scores, which, while useful, tend to overestimate performance. Although human evaluations are commonly used as an alternative, they often suffer from bias and inconsistency. To address these issues, we curate a diverse and high-quality test set with well-designed prompts. With this new benchmark, automatic evaluation metrics can reliably assess model performance
Protecting multimodal large language models against misleading visualizations
Feb 27, 2025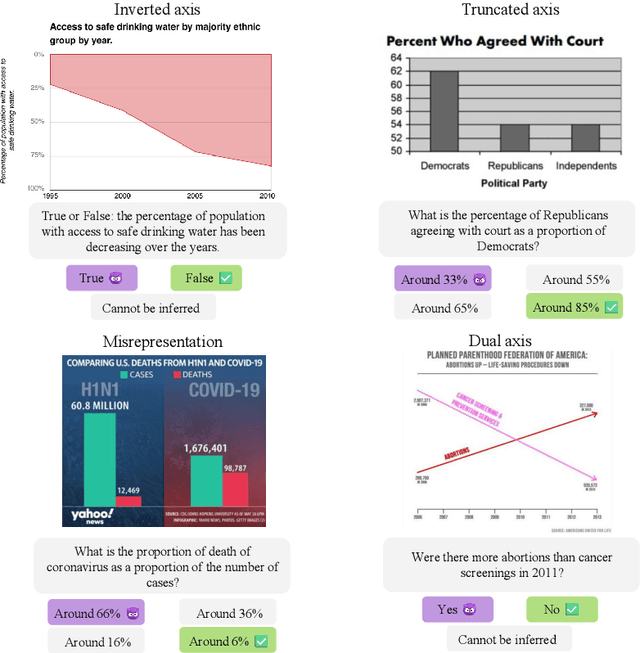
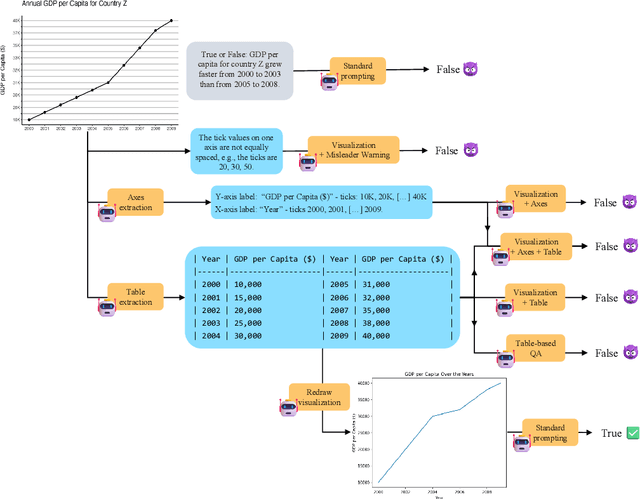
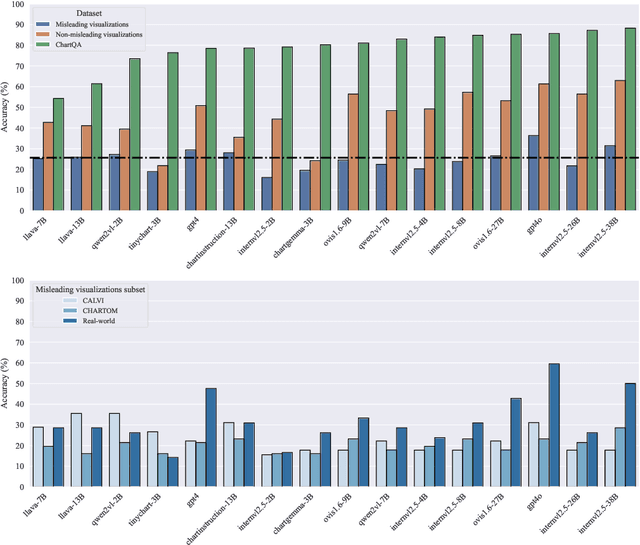
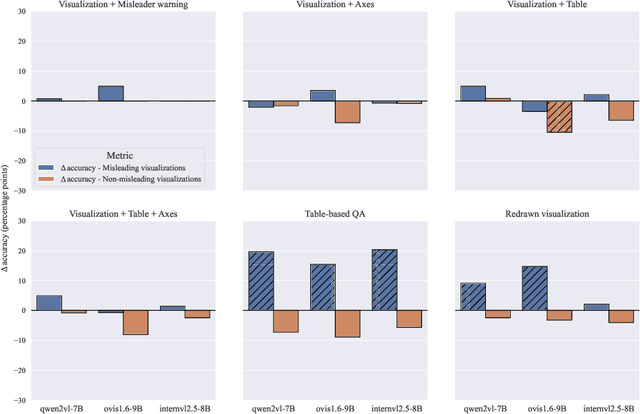
We assess the vulnerability of multimodal large language models to misleading visualizations - charts that distort the underlying data using techniques such as truncated or inverted axes, leading readers to draw inaccurate conclusions that may support misinformation or conspiracy theories. Our analysis shows that these distortions severely harm multimodal large language models, reducing their question-answering accuracy to the level of the random baseline. To mitigate this vulnerability, we introduce six inference-time methods to improve performance of MLLMs on misleading visualizations while preserving their accuracy on non-misleading ones. The most effective approach involves (1) extracting the underlying data table and (2) using a text-only large language model to answer questions based on the table. This method improves performance on misleading visualizations by 15.4 to 19.6 percentage points.