 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimicking How Humans Interpret Out-of-Context Sentences Through Controlled Toxicity Decoding
Mar 11, 2025Interpretations of a single sentence can vary, particularly when its context is lost. This paper aims to simulate how readers perceive content with varying toxicity levels by generating diverse interpretations of out-of-context sentences. By modeling toxicity, we can anticipate misunderstandings and reveal hidden toxic meanings. Our proposed decoding strategy explicitly controls toxicity in the set of generated interpretations by (i) aligning interpretation toxicity with the input, (ii) relaxing toxicity constraints for more toxic input sentences, and (iii) promoting diversity in toxicity levels within the set of generated interpretations. Experimental results show that our method improves alignment with human-written interpretations in both syntax and semantics while reducing model prediction uncertainty.
Action-based image editing guided by human instructions
Dec 05, 2024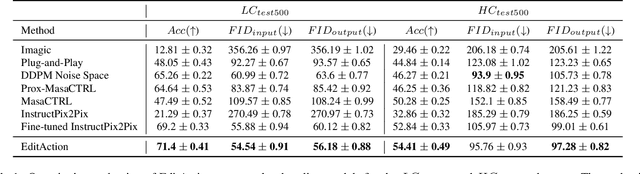
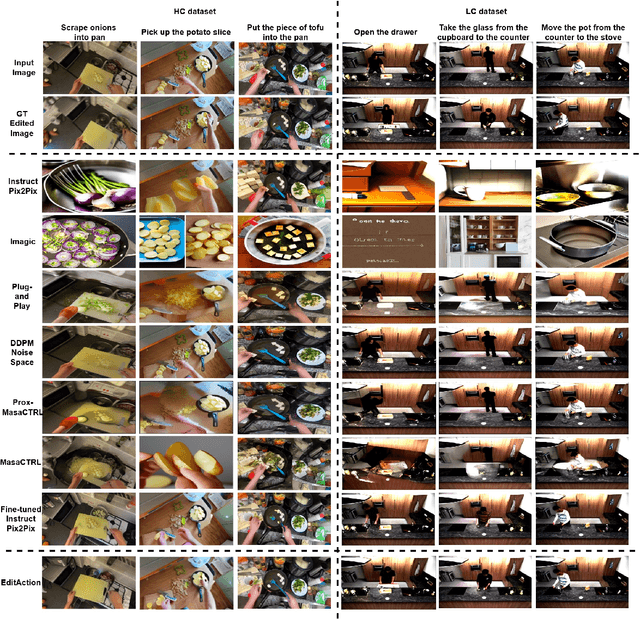
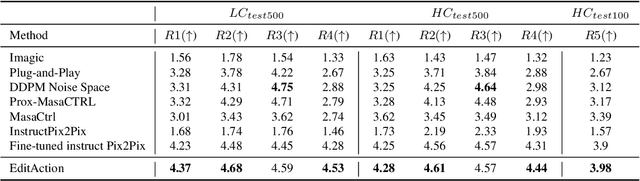

Text-based image editing is typically approached as a static task that involves operations such as inserting, deleting, or modifying elements of an input image based on human instructions. Given the static nature of this task, in this paper, we aim to make this task dynamic by incorporating actions. By doing this, we intend to modify the positions or postures of objects in the image to depict different actions while maintaining the visual properties of the objects. To implement this challenging task, we propose a new model that is sensitive to action text instructions by learning to recognize contrastive action discrepancies. The model training is done on new datasets defined by extracting frames from videos that show the visual scenes before and after an action. We show substantial improvements in image editing using action-based text instructions and high reasoning capabilities that allow our model to use the input image as a starting scene for an action while generating a new image that shows the final scene of the action.
DM-Align: Leveraging the Power of Natural Language Instructions to Make Changes to Images
Apr 27, 2024Text-based semantic image editing assumes the manipulation of an image using a natural language instruction. Although recent works are capable of generating creative and qualitative images, the problem is still mostly approached as a black box sensitive to generating unexpected outputs. Therefore, we propose a novel model to enhance the text-based control of an image editor by explicitly reasoning about which parts of the image to alter or preserve. It relies on word alignments between a description of the original source image and the instruction that reflects the needed updates, and the input image. The proposed Diffusion Masking with word Alignments (DM-Align) allows the editing of an image in a transparent and explainable way. It is evaluated on a subset of the Bison dataset and a self-defined dataset dubbed Dream. When comparing to state-of-the-art baselines, quantitative and qualitative results show that DM-Align has superior performance in image editing conditioned on language instructions, well preserves the background of the image and can better cope with long text instructions.
Object-Attribute Binding in Text-to-Image Generation: Evaluation and Control
Apr 21, 2024Current diffusion models create photorealistic images given a text prompt as input but struggle to correctly bind attributes mentioned in the text to the right objects in the image. This is evidenced by our novel image-graph alignment model called EPViT (Edge Prediction Vision Transformer) for the evaluation of image-text alignment. To alleviate the above problem, we propose focused cross-attention (FCA) that controls the visual attention maps by syntactic constraints found in the input sentence. Additionally, the syntax structure of the prompt helps to disentangle the multimodal CLIP embeddings that are commonly used in T2I generation. The resulting DisCLIP embeddings and FCA are easily integrated in state-of-the-art diffusion models without additional training of these models. We show substantial improvements in T2I generation and especially its attribute-object binding on several datasets.\footnote{Code and data will be made available upon acceptance.
Sequence-to-Sequence Spanish Pre-trained Language Models
Sep 20, 2023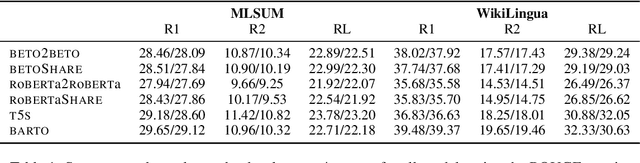



In recent years, substantial advancements in pre-trained language models have paved the way for the development of numerous non-English language versions, with a particular focus on encoder-only and decoder-only architectures. While Spanish language models encompassing BERT, RoBERTa, and GPT have exhibited prowess in natural language understanding and generation, there remains a scarcity of encoder-decoder models designed for sequence-to-sequence tasks involving input-output pairs. This paper breaks new ground by introducing the implementation and evaluation of renowned encoder-decoder architectures, exclusively pre-trained on Spanish corpora. Specifically, we present Spanish versions of BART, T5, and BERT2BERT-style models and subject them to a comprehensive assessment across a diverse range of sequence-to-sequence tasks, spanning summarization, rephrasing, and generative question answering. Our findings underscore the competitive performance of all models, with BART and T5 emerging as top performers across all evaluated tasks. As an additional contribution, we have made all models publicly available to the research community, fostering future exploration and development in Spanish language processing.
Adversarial Training for a Hybrid Approach to Aspect-Based Sentiment Analysis
Nov 29, 2021

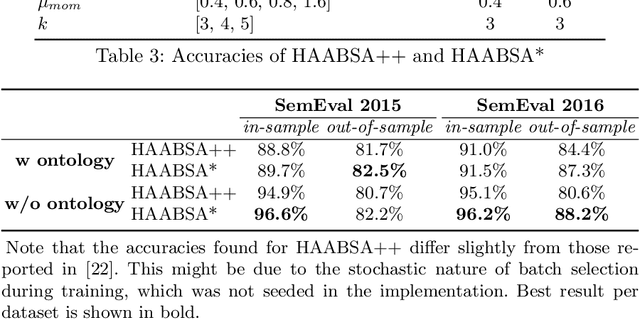
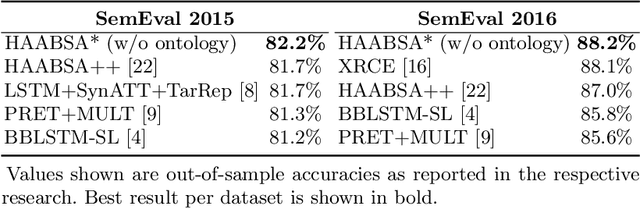
The increasing popularity of the Web has subsequently increased the abundance of reviews on products and services. Mining these reviews for expressed sentiment is beneficial for both companies and consumers, as quality can be improved based on this information. In this paper, we consider the state-of-the-art HAABSA++ algorithm for aspect-based sentiment analysis tasked with identifying the sentiment expressed towards a given aspect in review sentences. Specifically, we train the neural network part of this algorithm using an adversarial network, a novel machine learning training method where a generator network tries to fool the classifier network by generating highly realistic new samples, as such increasing robustness. This method, as of yet never in its classical form applied to aspect-based sentiment analysis, is found to be able to considerably improve the out-of-sample accuracy of HAABSA++: for the SemEval 2015 dataset, accuracy was increased from 81.7% to 82.5%, and for the SemEval 2016 task, accuracy increased from 84.4% to 87.3%.
Explaining a Neural Attention Model for Aspect-Based Sentiment Classification Using Diagnostic Classification
Mar 29, 2021

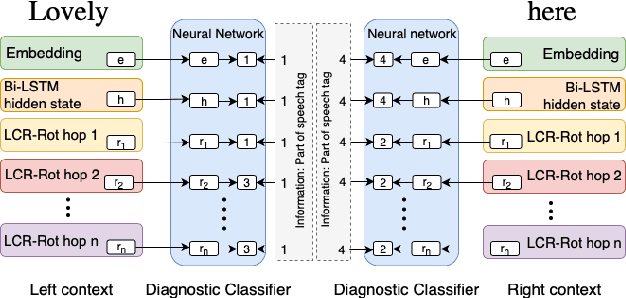

Many high performance machine learning models for Aspect-Based Sentiment Classification (ABSC) produce black box models, and therefore barely explain how they classify a certain sentiment value towards an aspect. In this paper, we propose explanation models, that inspect the internal dynamics of a state-of-the-art neural attention model, the LCR-Rot-hop, by using a technique called Diagnostic Classification. Our diagnostic classifier is a simple neural network, which evaluates whether the internal layers of the LCR-Rot-hop model encode useful word information for classification, i.e., the part of speech, the sentiment value, the presence of aspect relation, and the aspect-related sentiment value of words. We conclude that the lower layers in the LCR-Rot-hop model encode the part of speech and the sentiment value, whereas the higher layers represent the presence of a relation with the aspect and the aspect-related sentiment value of words.
Data Augmentation in a Hybrid Approach for Aspect-Based Sentiment Analysis
Mar 29, 2021
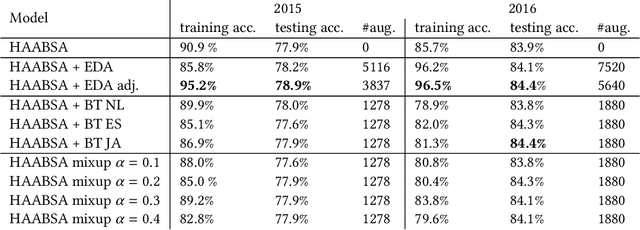

Data augmentation is a way to increase the diversity of available data by applying constrained transformations on the original data. This strategy has been widely used in image classification but has to the best of our knowledge not yet been used in aspect-based sentiment analysis (ABSA). ABSA is a text analysis technique that determines aspects and their associated sentiment in opinionated text. In this paper, we investigate the effect of data augmentation on a state-of-the-art hybrid approach for aspect-based sentiment analysis (HAABSA). We apply modified versions of easy data augmentation (EDA), backtranslation, and word mixup. We evaluate the proposed techniques on the SemEval 2015 and SemEval 2016 datasets. The best result is obtained with the adjusted version of EDA, which yields a 0.5 percentage point improvement on the SemEval 2016 dataset and 1 percentage point increase on the SemEval 2015 dataset compared to the original HAABSA model.
Pattern Learning for Detecting Defect Reports and Improvement Requests in App Reviews
Apr 19, 2020
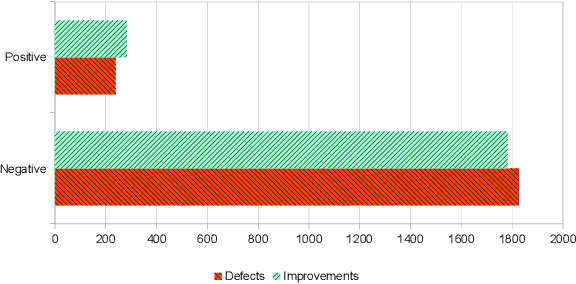

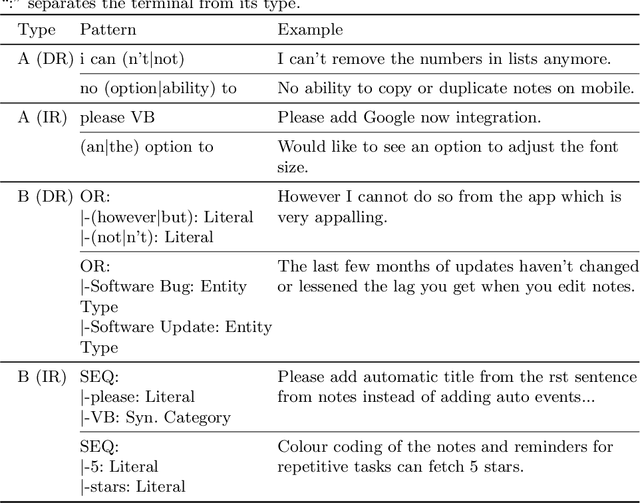
Online reviews are an important source of feedback for understanding customers. In this study, we follow novel approaches that target this absence of actionable insights by classifying reviews as defect reports and requests for improvement. Unlike traditional classification methods based on expert rules, we reduce the manual labour by employing a supervised system that is capable of learning lexico-semantic patterns through genetic programming. Additionally, we experiment with a distantly-supervised SVM that makes use of noisy labels generated by patterns. Using a real-world dataset of app reviews, we show that the automatically learned patterns outperform the manually created ones, to be generated. Also the distantly-supervised SVM models are not far behind the pattern-based solutions, showing the usefulness of this approach when the amount of annotated data is limited.
A Hybrid Approach for Aspect-Based Sentiment Analysis Using Deep Contextual Word Embeddings and Hierarchical Attention
Apr 18, 2020
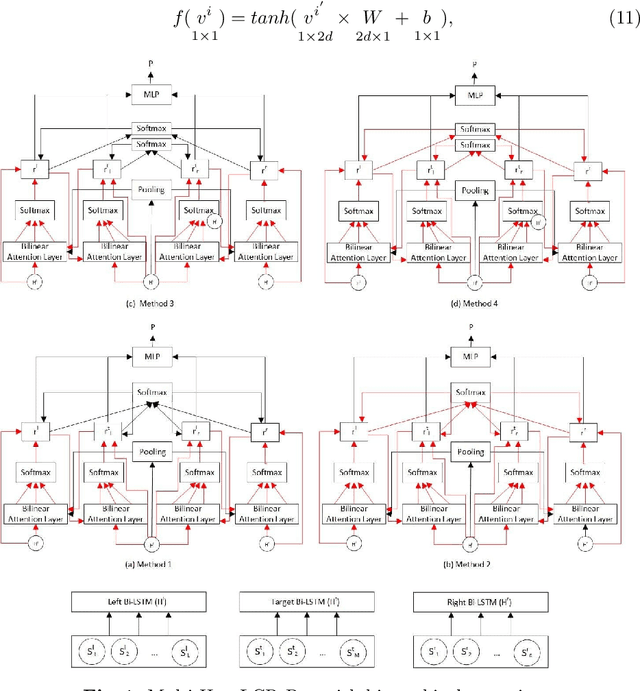
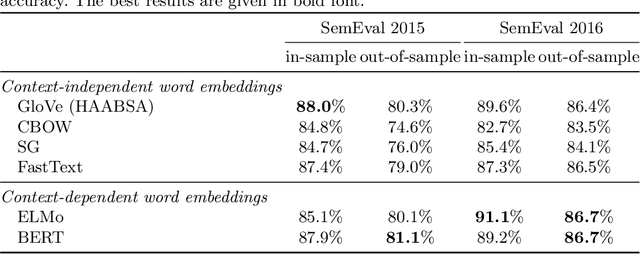

The Web has become the main platform where people express their opinions about entities of interest and their associated aspects. Aspect-Based Sentiment Analysis (ABSA) aims to automatically compute the sentiment towards these aspects from opinionated text. In this paper we extend the state-of-the-art Hybrid Approach for Aspect-Based Sentiment Analysis (HAABSA) method in two directions. First we replace the non-contextual word embeddings with deep contextual word embeddings in order to better cope with the word semantics in a given text. Second, we use hierarchical attention by adding an extra attention layer to the HAABSA high-level representations in order to increase the method flexibility in modeling the input data. Using two standard datasets (SemEval 2015 and SemEval 2016) we show that the proposed extensions improve the accuracy of the built model for ABSA.