 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation in a Hybrid Approach for Aspect-Based Sentiment Analysis
Paper and Code

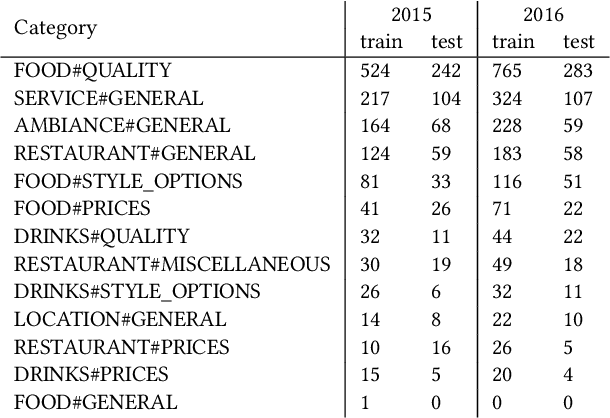
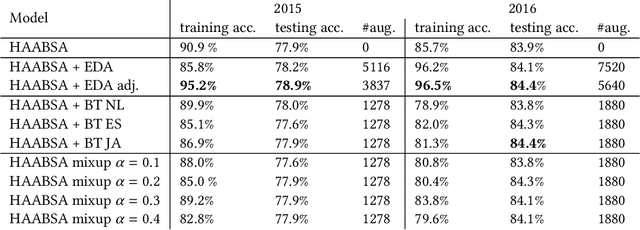

Data augmentation is a way to increase the diversity of available data by applying constrained transformations on the original data. This strategy has been widely used in image classification but has to the best of our knowledge not yet been used in aspect-based sentiment analysis (ABSA). ABSA is a text analysis technique that determines aspects and their associated sentiment in opinionated text. In this paper, we investigate the effect of data augmentation on a state-of-the-art hybrid approach for aspect-based sentiment analysis (HAABSA). We apply modified versions of easy data augmentation (EDA), backtranslation, and word mixup. We evaluate the proposed techniques on the SemEval 2015 and SemEval 2016 datasets. The best result is obtained with the adjusted version of EDA, which yields a 0.5 percentage point improvement on the SemEval 2016 dataset and 1 percentage point increase on the SemEval 2015 dataset compared to the original HAABSA model.