 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Hierarchical Neural Networks using Hierarchical Softmax
Aug 02, 2023This paper presents a framework in which hierarchical softmax is used to create a global hierarchical classifier. The approach is applicable for any classification task where there is a natural hierarchy among classes. We show empirical results on four text classification datasets. In all datasets the hierarchical softmax improved on the regular softmax used in a flat classifier in terms of macro-F1 and macro-recall. In three out of four datasets hierarchical softmax achieved a higher micro-accuracy and macro-precision.
A Survey on Aspect-Based Sentiment Classification
Mar 27, 2022
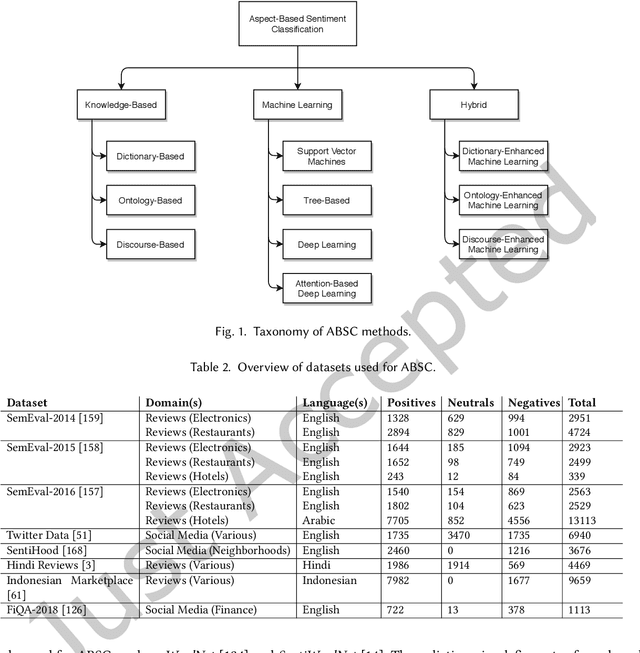
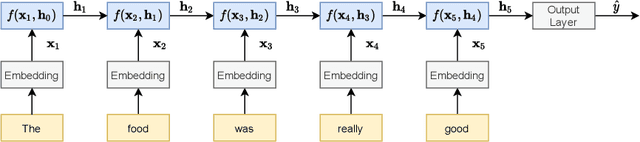
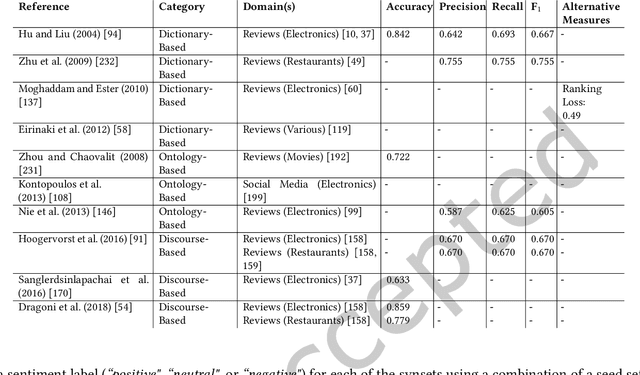
With the constantly growing number of reviews and other sentiment-bearing texts on the Web, the demand for automatic sentiment analysis algorithms continues to expand. Aspect-based sentiment classification (ABSC) allows for the automatic extraction of highly fine-grained sentiment information from text documents or sentences. In this survey, the rapidly evolving state of the research on ABSC is reviewed. A novel taxonomy is proposed that categorizes the ABSC models into three major categories: knowledge-based, machine learning, and hybrid models. This taxonomy is accompanied with summarizing overviews of the reported model performances, and both technical and intuitive explanations of the various ABSC models. State-of-the-art ABSC models are discussed, such as models based on the transformer model, and hybrid deep learning models that incorporate knowledge bases. Additionally, various techniques for representing the model inputs and evaluating the model outputs are reviewed. Furthermore, trends in the research on ABSC are identified and a discussion is provided on the ways in which the field of ABSC can be advanced in the future.
* 35 pages, 5 figures
A General Survey on Attention Mechanisms in Deep Learning
Mar 27, 2022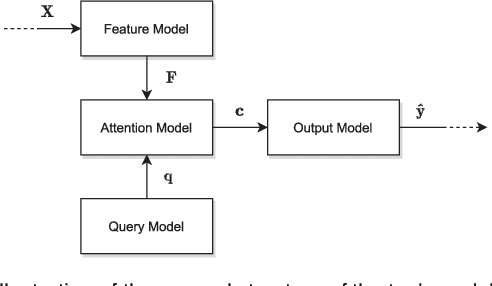

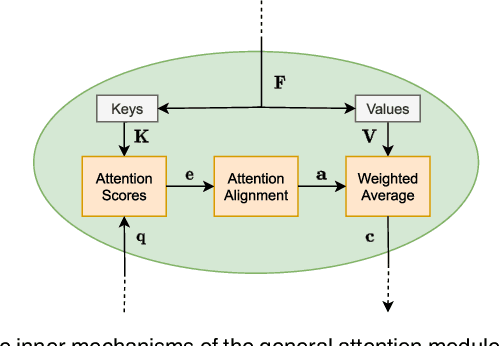

Attention is an important mechanism that can be employed for a variety of deep learning models across many different domains and tasks. This survey provides an overview of the most important attention mechanisms proposed in the literature. The various attention mechanisms are explained by means of a framework consisting of a general attention model, uniform notation, and a comprehensive taxonomy of attention mechanisms. Furthermore, the various measures for evaluating attention models are reviewed, and methods to characterize the structure of attention models based on the proposed framework are discussed. Last, future work in the field of attention models is considered.
* 20 pages, 11 figures
Adversarial Training for a Hybrid Approach to Aspect-Based Sentiment Analysis
Nov 29, 2021

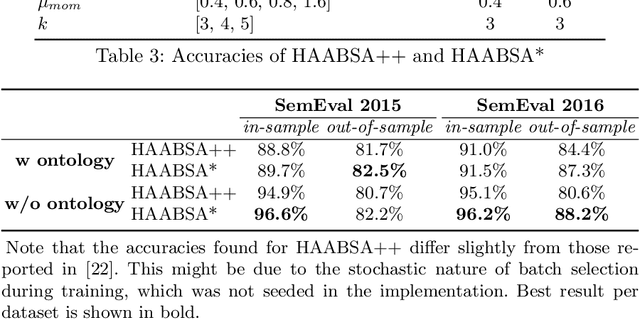
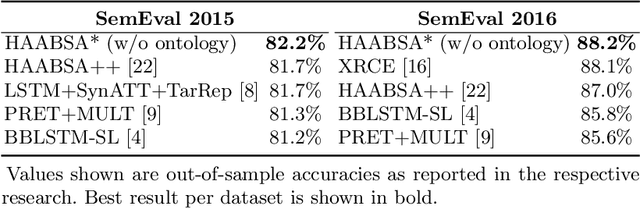
The increasing popularity of the Web has subsequently increased the abundance of reviews on products and services. Mining these reviews for expressed sentiment is beneficial for both companies and consumers, as quality can be improved based on this information. In this paper, we consider the state-of-the-art HAABSA++ algorithm for aspect-based sentiment analysis tasked with identifying the sentiment expressed towards a given aspect in review sentences. Specifically, we train the neural network part of this algorithm using an adversarial network, a novel machine learning training method where a generator network tries to fool the classifier network by generating highly realistic new samples, as such increasing robustness. This method, as of yet never in its classical form applied to aspect-based sentiment analysis, is found to be able to considerably improve the out-of-sample accuracy of HAABSA++: for the SemEval 2015 dataset, accuracy was increased from 81.7% to 82.5%, and for the SemEval 2016 task, accuracy increased from 84.4% to 87.3%.
Utilizing Textual Reviews in Latent Factor Models for Recommender Systems
Nov 16, 2021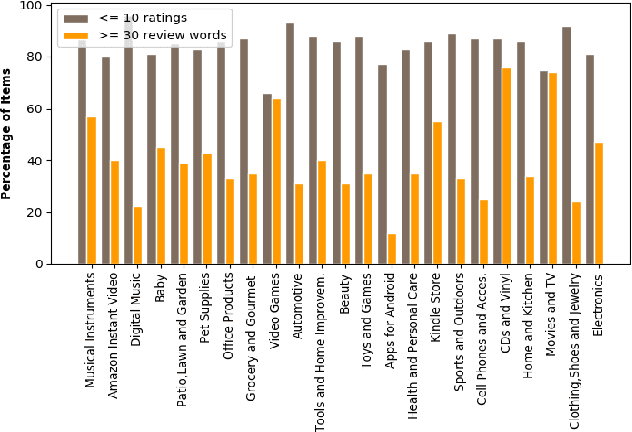
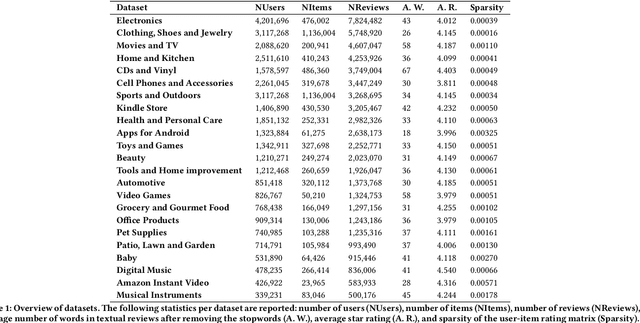


Most of the existing recommender systems are based only on the rating data, and they ignore other sources of information that might increase the quality of recommendations, such as textual reviews, or user and item characteristics. Moreover, the majority of those systems are applicable only on small datasets (with thousands of observations) and are unable to handle large datasets (with millions of observations). We propose a recommender algorithm that combines a rating modelling technique (i.e., Latent Factor Model) with a topic modelling method based on textual reviews (i.e., Latent Dirichlet Allocation), and we extend the algorithm such that it allows adding extra user- and item-specific information to the system. We evaluate the performance of the algorithm using Amazon.com datasets with different sizes, corresponding to 23 product categories. After comparing the built model to four other models we found that combining textual reviews with ratings leads to better recommendations. Moreover, we found that adding extra user and item features to the model increases its prediction accuracy, which is especially true for medium and large datasets.
Explaining a Neural Attention Model for Aspect-Based Sentiment Classification Using Diagnostic Classification
Mar 29, 2021

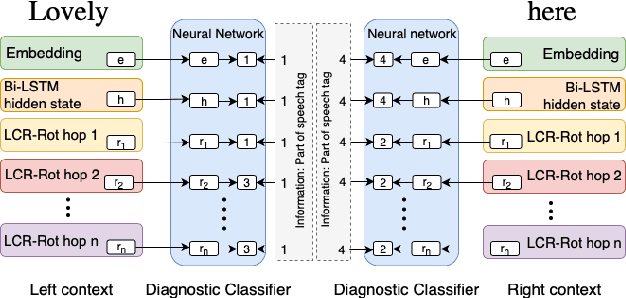

Many high performance machine learning models for Aspect-Based Sentiment Classification (ABSC) produce black box models, and therefore barely explain how they classify a certain sentiment value towards an aspect. In this paper, we propose explanation models, that inspect the internal dynamics of a state-of-the-art neural attention model, the LCR-Rot-hop, by using a technique called Diagnostic Classification. Our diagnostic classifier is a simple neural network, which evaluates whether the internal layers of the LCR-Rot-hop model encode useful word information for classification, i.e., the part of speech, the sentiment value, the presence of aspect relation, and the aspect-related sentiment value of words. We conclude that the lower layers in the LCR-Rot-hop model encode the part of speech and the sentiment value, whereas the higher layers represent the presence of a relation with the aspect and the aspect-related sentiment value of words.
Data Augmentation in a Hybrid Approach for Aspect-Based Sentiment Analysis
Mar 29, 2021
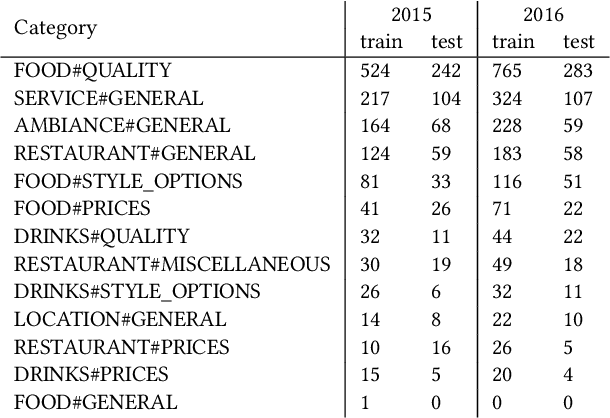
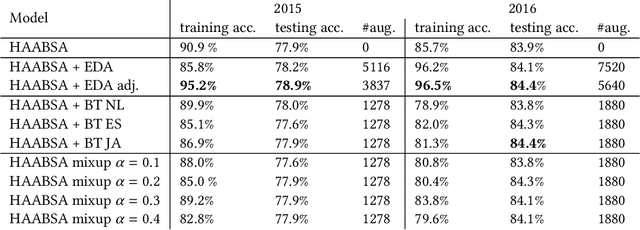

Data augmentation is a way to increase the diversity of available data by applying constrained transformations on the original data. This strategy has been widely used in image classification but has to the best of our knowledge not yet been used in aspect-based sentiment analysis (ABSA). ABSA is a text analysis technique that determines aspects and their associated sentiment in opinionated text. In this paper, we investigate the effect of data augmentation on a state-of-the-art hybrid approach for aspect-based sentiment analysis (HAABSA). We apply modified versions of easy data augmentation (EDA), backtranslation, and word mixup. We evaluate the proposed techniques on the SemEval 2015 and SemEval 2016 datasets. The best result is obtained with the adjusted version of EDA, which yields a 0.5 percentage point improvement on the SemEval 2016 dataset and 1 percentage point increase on the SemEval 2015 dataset compared to the original HAABSA model.
Pattern Learning for Detecting Defect Reports and Improvement Requests in App Reviews
Apr 19, 2020
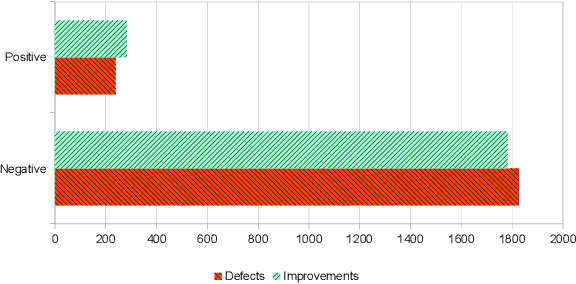

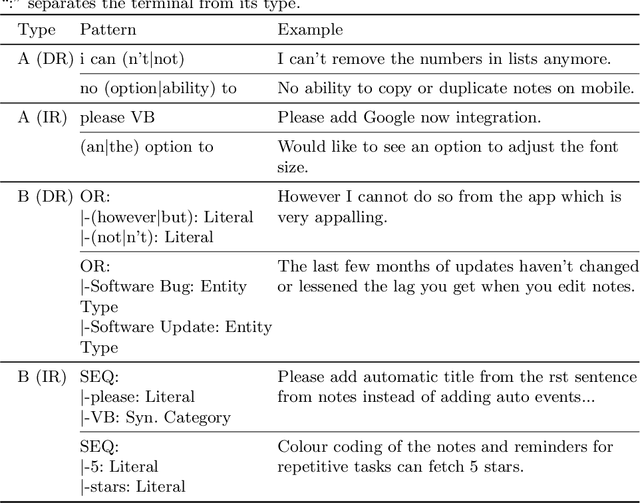
Online reviews are an important source of feedback for understanding customers. In this study, we follow novel approaches that target this absence of actionable insights by classifying reviews as defect reports and requests for improvement. Unlike traditional classification methods based on expert rules, we reduce the manual labour by employing a supervised system that is capable of learning lexico-semantic patterns through genetic programming. Additionally, we experiment with a distantly-supervised SVM that makes use of noisy labels generated by patterns. Using a real-world dataset of app reviews, we show that the automatically learned patterns outperform the manually created ones, to be generated. Also the distantly-supervised SVM models are not far behind the pattern-based solutions, showing the usefulness of this approach when the amount of annotated data is limited.
A Hybrid Approach for Aspect-Based Sentiment Analysis Using Deep Contextual Word Embeddings and Hierarchical Attention
Apr 18, 2020
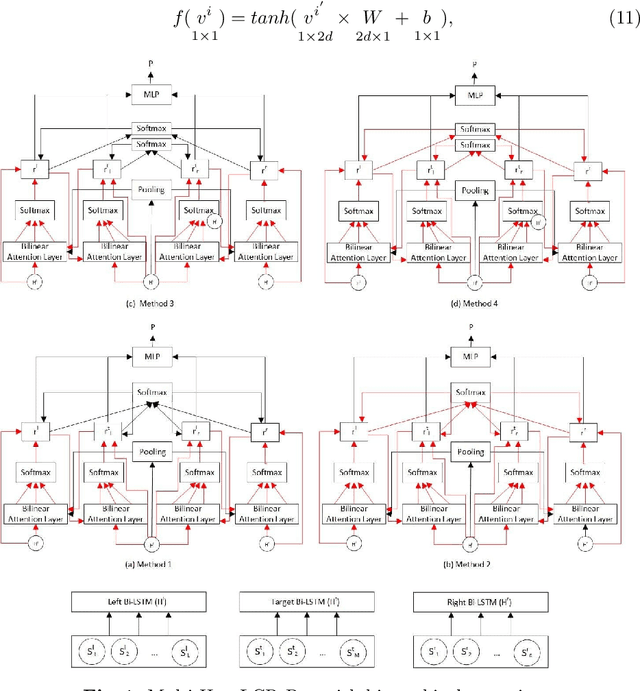
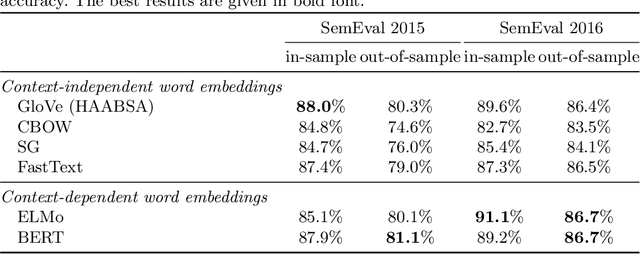

The Web has become the main platform where people express their opinions about entities of interest and their associated aspects. Aspect-Based Sentiment Analysis (ABSA) aims to automatically compute the sentiment towards these aspects from opinionated text. In this paper we extend the state-of-the-art Hybrid Approach for Aspect-Based Sentiment Analysis (HAABSA) method in two directions. First we replace the non-contextual word embeddings with deep contextual word embeddings in order to better cope with the word semantics in a given text. Second, we use hierarchical attention by adding an extra attention layer to the HAABSA high-level representations in order to increase the method flexibility in modeling the input data. Using two standard datasets (SemEval 2015 and SemEval 2016) we show that the proposed extensions improve the accuracy of the built model for ABSA.